Slide
充斥着大量的谬误与个人的随意理解: sched_ext机制研究
简介
<The extensible scheduler class [LWN.net]>
BPF背后的核心思想是, 它允许程序在运行时从用户空间加载到内核中; 与现在的Linux系统相比, 使用BPF进行调度有可能实现明显不同的调度行为. 那么, 为什么现在要提出BPF机制呢? 为了期待一场长时间的讨论, 补丁系列的封面信详细描述了这项工作背后的动机. 简而言之, 该论点认为, 在BPF中编写调度策略的能力大大降低了试验新调度方法的难度. 由于引入了完全公平调度器CFS, 我们的工作负载及其运行的系统都变得更加复杂. 要开发适合当前系统的调度算法, 需要进行试验. BPF调度类允许以一种安全的方式进行实验, 甚至不需要重新启动测试机器. bpf编写的调度器还可以提高可能不值得在主线内核中支持的小众工作负载的性能, 这些工作负载更容易部署到大量系统中.
补丁集添加了一个新的调度类SCHED_EXT, 可以像大多数其他类一样通过sched_setscheduler()调用来选择它(选择SCHED_DEADLINE稍微复杂一些). 这是一个非特权类, 意味着任何进程都可以将自身放置到SCHED_EXT中. SCHED_EXT位于优先级栈中的空闲类(SCHED_IDLE)和完全公平调度器(SCHED_NORMAL)之间. 因此, SCHED_EXT调度器无法以某种方式接管系统, 例如, 无法阻止以SCHED_NORMAL形式运行的普通shell会话运行. 它还表明, 在使用SCHED_EXT的系统上, 预期大部分工作负载将在该类中运行.
bpf编写的调度器对整个系统是全局的, 没有规定不同的进程组可以加载自己的调度器. 如果没有加载BPF调度器, 那么已经放入SCHED_EXT类的任何进程都会像运行在SCHED_NORMAL中一样运行. 装载BPF调度器后, 它将接管所有SCHED_EXT进程的职责. 还有一个神奇的函数, BPF调度器可以调用(scx_bpf_switch_all()), 将所有运行在实时优先级以下的进程移动到SCHED_EXT.
实现调度器的BPF程序通常会管理一组调度队列, 其中每个队列可能包含等待CPU执行的可运行任务. 默认情况下, 系统中的每个CPU都有一个调度队列, 以及一个全局队列. 当一个CPU准备运行一个新任务时, 调度器将从相关的调度队列中取出一个任务, 并将CPU分配给它. 调度器的BPF端主要实现为一组通过操作结构调用的回调函数, 每个回调函数都会通知BPF代码某个事件或需要做出的决定. 这个列表很长;完整的集合可以在SCHED_EXT存储库分支的include/sched/ext.h中找到.
即便如此, BPF调度器类显然对核心内核社区来说是一个很大的负担. 它增加了10 000多行核心代码, 并暴露了许多调度细节, 这些细节到目前为止一直深藏在内核内部. 这意味着一个通用调度器无法为所有工作负载提供最佳的服务; 有些人可能会担心, 这将标志着完全公平调度器为实现这一目标而工作的终结, 并增加Linux系统上的碎片. BPF-scheduling的开发人员则持相反的观点, 他们认为自由试验调度模型的能力反而会加速对完全公平调度器的改进.
除了注意到BPF这个庞然大物迄今为止已经成功地克服了它遇到的几乎所有反对意见之外, 很难预测这一切将如何发展. 将核心内核功能锁定在内核内部的日子似乎即将结束. 该子系统将启用哪些新的调度方法, 这将是一件有趣的事情.
SCX内核接口与基础设施
总的来说, SCX机制涉及的代码文件不多, 主要在3个地方, 读起来很舒服:
-
include/linux/sched/ext.hdefines the core data structures, ops table and constants. 内核与用户的接口文件, 定义了绝大数的函数接口. -
kernel/sched/ext.ccontains sched_ext core implementation and helpers. The functions prefixed withscx_bpf_can be called from the BPF scheduler. 内核具体对于拓展调度器的实现, 以scx_bpf_结尾. -
tools/sched_ext/hosts example BPF scheduler implementations. 通过eBPF实现的调度器的例子.-
scx_example_dummy[.bpf].c: Minimal global FIFO scheduler example using a custom dsq. -
scx_example_qmap[.bpf].c: A multi-level FIFO scheduler supporting five levels of priority implemented withBPF_MAP_TYPE_QUEUE.
-
sched_ext有一个dsq's的概念:
To match the impedance between the scheduler core and the BPF scheduler, sched_ext uses simple FIFOs called dsq’s (dispatch queues). By default, there is one global FIFO (
SCX_DSQ_GLOBAL), and one local dsq per CPU (SCX_DSQ_LOCAL). The BPF scheduler can manage an arbitrary number of dsq’s usingscx_bpf_create_dsq()andscx_bpf_destroy_dsq().A task is always dispatched to a dsq for execution. The task starts execution when a CPU consumes the task from the dsq.
Internally, a CPU only executes tasks which are running on its local dsq, and the
.consume()operation is in fact a transfer of a task from a remote dsq to the CPU’s local dsq. A CPU therefore only consumes from other dsq’s when its local dsq is empty, and dispatching a task to a local dsq will cause it to be executed before the CPU attempts to consume tasks which were previously dispatched to other dsq’s.
在一个调度周期中, 主要发生如下的流程:
-
当一个task被唤醒, 首先执行的是
select_cpu方法, 其用于选择最优的CPU, 同时如果该CPU闲置则唤醒该CPU.-
虽然任务真正执行的CPU在调度的最后才决定, 但是如果该CPU与select的CPU一致则会也有一些微弱的性能的提升. And why?
-
该函数带来的一个副作用是其会唤醒选中的CPU. 尽管BPF调度器可以通过
scx_bpf_kick_cpu唤醒任意的cpu, 但是通过select_cpu会更加简单且高效.
-
-
一旦选中一个CPU后, 将调用
enqueue方法, 其将执行下述的一个操作:-
通过带有
SCX_DSQ_GLOBAL或SCX_DSQ_LOCAL的scx_bpf_dispatch函数立即分发当前任务到全局或本地dsq -
通过传递一个dsq id给
scx_bpf_dispatch将任务分发到用户自己创建的dsq. -
在BPF侧将任务入队列
-
-
当一个CPU准备好进行调度了, 其将首先查看自己的本地dsq. 如果其为空, 则将调用
consume方法, 进而调用若干次scx_bpf_consume函数来从dsq(哪个呢)中取任务. 一旦函数返回成功则CPU将获得下一个用于执行的任务. 默认情况下, consume方法将消费SCX_DSQ_GLOBAL全局dsq队列. -
如果仍然没有任务可用于执行, 将调用
dispatch方法, 进而调用若干次scx_bpf_dispatch函数来要求BPF调度器对任务进行分发. 如果有任务被成功分发了, 则回到上一步进行处理. -
如果仍然没有任务可用于执行, 则则调用
consume_final方法. 该方法与consume等价, 但是其在CPU即将闲置前才被进行调用. 这为调度器提供了一个hook, 可用于执行自定义的一些操作.
事实上, BPF调度器可以选择在enqueue方法中就直接调用scx_bpf_dispatch, 因而不必再实现dispatch方法了, 比如dummy-example就是这样做的.
struct rq
1/*
2 * This is the main, per-CPU runqueue data structure.
3 *
4 * Locking rule: those places that want to lock multiple runqueues
5 * (such as the load balancing or the thread migration code), lock
6 * acquire operations must be ordered by ascending &runqueue.
7 */
8struct rq {
9 /* runqueue lock: */
10 raw_spinlock_t __lock;
11
12 /*
13 * nr_running and cpu_load should be in the same cacheline because
14 * remote CPUs use both these fields when doing load calculation.
15 */
16 unsigned int nr_running;
17#ifdef CONFIG_NUMA_BALANCING
18 unsigned int nr_numa_running;
19 unsigned int nr_preferred_running;
20 unsigned int numa_migrate_on;
21#endif
22#ifdef CONFIG_NO_HZ_COMMON
23#ifdef CONFIG_SMP
24 unsigned long last_blocked_load_update_tick;
25 unsigned int has_blocked_load;
26 call_single_data_t nohz_csd;
27#endif /* CONFIG_SMP */
28 unsigned int nohz_tick_stopped;
29 atomic_t nohz_flags;
30#endif /* CONFIG_NO_HZ_COMMON */
31
32#ifdef CONFIG_SMP
33 unsigned int ttwu_pending;
34#endif
35 u64 nr_switches;
36
37#ifdef CONFIG_UCLAMP_TASK
38 /* Utilization clamp values based on CPU's RUNNABLE tasks */
39 struct uclamp_rq uclamp[UCLAMP_CNT] ____cacheline_aligned;
40 unsigned int uclamp_flags;
41#define UCLAMP_FLAG_IDLE 0x01
42#endif
43
44 struct cfs_rq cfs;
45 struct rt_rq rt;
46 struct dl_rq dl;
47#ifdef CONFIG_SCHED_CLASS_EXT
48 struct scx_rq scx;
49#endif
50
51#ifdef CONFIG_FAIR_GROUP_SCHED
52 /* list of leaf cfs_rq on this CPU: */
53 struct list_head leaf_cfs_rq_list;
54 struct list_head *tmp_alone_branch;
55#endif /* CONFIG_FAIR_GROUP_SCHED */
56
57 /*
58 * This is part of a global counter where only the total sum
59 * over all CPUs matters. A task can increase this counter on
60 * one CPU and if it got migrated afterwards it may decrease
61 * it on another CPU. Always updated under the runqueue lock:
62 */
63 unsigned int nr_uninterruptible;
64
65 struct task_struct __rcu *curr;
66 struct task_struct *idle;
67 struct task_struct *stop;
68 unsigned long next_balance;
69 struct mm_struct *prev_mm;
70
71 unsigned int clock_update_flags;
72 u64 clock;
73 /* Ensure that all clocks are in the same cache line */
74 u64 clock_task ____cacheline_aligned;
75 u64 clock_pelt;
76 unsigned long lost_idle_time;
77 u64 clock_pelt_idle;
78 u64 clock_idle;
79#ifndef CONFIG_64BIT
80 u64 clock_pelt_idle_copy;
81 u64 clock_idle_copy;
82#endif
83
84 atomic_t nr_iowait;
85
86#ifdef CONFIG_SCHED_DEBUG
87 u64 last_seen_need_resched_ns;
88 int ticks_without_resched;
89#endif
90
91#ifdef CONFIG_MEMBARRIER
92 int membarrier_state;
93#endif
94
95#ifdef CONFIG_SMP
96 struct root_domain *rd;
97 struct sched_domain __rcu *sd;
98
99 unsigned long cpu_capacity;
100 unsigned long cpu_capacity_orig;
101
102 struct balance_callback *balance_callback;
103
104 unsigned char nohz_idle_balance;
105 unsigned char idle_balance;
106
107 unsigned long misfit_task_load;
108
109 /* For active balancing */
110 int active_balance;
111 int push_cpu;
112 struct cpu_stop_work active_balance_work;
113
114 /* CPU of this runqueue: */
115 int cpu;
116 int online;
117
118 struct list_head cfs_tasks;
119
120 struct sched_avg avg_rt;
121 struct sched_avg avg_dl;
122#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
123 struct sched_avg avg_irq;
124#endif
125#ifdef CONFIG_SCHED_THERMAL_PRESSURE
126 struct sched_avg avg_thermal;
127#endif
128 u64 idle_stamp;
129 u64 avg_idle;
130
131 unsigned long wake_stamp;
132 u64 wake_avg_idle;
133
134 /* This is used to determine avg_idle's max value */
135 u64 max_idle_balance_cost;
136
137#ifdef CONFIG_HOTPLUG_CPU
138 struct rcuwait hotplug_wait;
139#endif
140#endif /* CONFIG_SMP */
141
142#ifdef CONFIG_IRQ_TIME_ACCOUNTING
143 u64 prev_irq_time;
144#endif
145#ifdef CONFIG_PARAVIRT
146 u64 prev_steal_time;
147#endif
148#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
149 u64 prev_steal_time_rq;
150#endif
151
152 /* calc_load related fields */
153 unsigned long calc_load_update;
154 long calc_load_active;
155
156#ifdef CONFIG_SCHED_HRTICK
157#ifdef CONFIG_SMP
158 call_single_data_t hrtick_csd;
159#endif
160 struct hrtimer hrtick_timer;
161 ktime_t hrtick_time;
162#endif
163
164#ifdef CONFIG_SCHEDSTATS
165 /* latency stats */
166 struct sched_info rq_sched_info;
167 unsigned long long rq_cpu_time;
168 /* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
169
170 /* sys_sched_yield() stats */
171 unsigned int yld_count;
172
173 /* schedule() stats */
174 unsigned int sched_count;
175 unsigned int sched_goidle;
176
177 /* try_to_wake_up() stats */
178 unsigned int ttwu_count;
179 unsigned int ttwu_local;
180#endif
181
182#ifdef CONFIG_CPU_IDLE
183 /* Must be inspected within a rcu lock section */
184 struct cpuidle_state *idle_state;
185#endif
186
187#ifdef CONFIG_SMP
188 unsigned int nr_pinned;
189#endif
190 unsigned int push_busy;
191 struct cpu_stop_work push_work;
192
193#ifdef CONFIG_SCHED_CORE
194 /* per rq */
195 struct rq *core;
196 struct task_struct *core_pick;
197 unsigned int core_enabled;
198 unsigned int core_sched_seq;
199 struct rb_root core_tree;
200
201 /* shared state -- careful with sched_core_cpu_deactivate() */
202 unsigned int core_task_seq;
203 unsigned int core_pick_seq;
204 unsigned long core_cookie;
205 unsigned int core_forceidle_count;
206 unsigned int core_forceidle_seq;
207 unsigned int core_forceidle_occupation;
208 u64 core_forceidle_start;
209#endif
210};据ULK说, runqueue是Linux2.6调度中最重要的数据结构, 所以关于rq可能要留坑, 后续完善
struct scx_rq
1#ifdef CONFIG_SCHED_CLASS_EXT
2/* scx_rq->flags, protected by the rq lock */
3enum scx_rq_flags {
4 SCX_RQ_CAN_STOP_TICK = 1 << 0,
5};
6
7struct scx_rq {
8 struct scx_dispatch_q local_dsq;
9 struct list_head watchdog_list;
10 u64 ops_qseq;
11 u32 nr_running;
12 u32 flags;
13 bool cpu_released;
14#ifdef CONFIG_SMP
15 cpumask_var_t cpus_to_kick;
16 cpumask_var_t cpus_to_preempt;
17 cpumask_var_t cpus_to_wait;
18 u64 pnt_seq;
19 struct irq_work kick_cpus_irq_work;
20#endif
21};
22#endif /* CONFIG_SCHED_CLASS_EXT */scx_dispatch_q
1/*
2 * Dispatch queue (dsq) is a simple FIFO which is used to buffer between the
3 * scheduler core and the BPF scheduler. See the documentation for more details.
4 */
5struct scx_dispatch_q {
6 raw_spinlock_t lock;
7 struct list_head fifo;
8 u64 id;
9 u32 nr;
10 struct rhash_head hash_node;
11 struct list_head all_node;
12 struct llist_node free_node;
13 struct rcu_head rcu;
14};sched_ext_ops
在用户空间中, 只要实现了struct sched_ext_ops结构即可装载任意一个BPF调度器进入内核.
1 # pri kind tag file
2 1 F C s sched_ext_ops include/linux/sched/ext.h
3 struct sched_ext_ops {
4 2 F s sched_ext_ops tools/sched_ext/tools/build/bpftool/vmlinux.h
5 struct sched_ext_ops {
6 3 F s sched_ext_ops tools/sched_ext/tools/include/vmlinux.h
7 struct sched_ext_ops {貌似3号所对应的就是vmlinux的各个符号表, 所以里面包含了所有文件的结构, 或者也可能是因为开启了BTF的原因.
尽管真的很长, 但是还是拿出来以供后续的参考:
1/**
2 * struct sched_ext_ops - Operation table for BPF scheduler implementation
3 *
4 * Userland can implement an arbitrary scheduling policy by implementing and
5 * loading operations in this table.
6 */
7struct sched_ext_ops {
8 /**
9 * select_cpu - Pick the target CPU for a task which is being woken up
10 * @p: task being woken up
11 * @prev_cpu: the cpu @p was on before sleeping
12 * @wake_flags: SCX_WAKE_*
13 *
14 * Decision made here isn't final. @p may be moved to any CPU while it
15 * is getting dispatched for execution later. However, as @p is not on
16 * the rq at this point, getting the eventual execution CPU right here
17 * saves a small bit of overhead down the line.
18 *
19 * If an idle CPU is returned, the CPU is kicked and will try to
20 * dispatch. While an explicit custom mechanism can be added,
21 * select_cpu() serves as the default way to wake up idle CPUs.
22 */
23 s32 (*select_cpu)(struct task_struct *p, s32 prev_cpu, u64 wake_flags);
24
25 /**
26 * enqueue - Enqueue a task on the BPF scheduler
27 * @p: task being enqueued
28 * @enq_flags: %SCX_ENQ_*
29 *
30 * @p is ready to run. Dispatch directly by calling scx_bpf_dispatch()
31 * or enqueue on the BPF scheduler. If not directly dispatched, the bpf
32 * scheduler owns @p and if it fails to dispatch @p, the task will
33 * stall.
34 */
35 void (*enqueue)(struct task_struct *p, u64 enq_flags);
36
37 /**
38 * dequeue - Remove a task from the BPF scheduler
39 * @p: task being dequeued
40 * @deq_flags: %SCX_DEQ_*
41 *
42 * Remove @p from the BPF scheduler. This is usually called to isolate
43 * the task while updating its scheduling properties (e.g. priority).
44 *
45 * The ext core keeps track of whether the BPF side owns a given task or
46 * not and can gracefully ignore spurious dispatches from BPF side,
47 * which makes it safe to not implement this method. However, depending
48 * on the scheduling logic, this can lead to confusing behaviors - e.g.
49 * scheduling position not being updated across a priority change.
50 */
51 void (*dequeue)(struct task_struct *p, u64 deq_flags);
52
53 /**
54 * dispatch - Dispatch tasks from the BPF scheduler into dsq's
55 * @cpu: CPU to dispatch tasks for
56 * @prev: previous task being switched out
57 *
58 * Called when a CPU can't find a task to execute after ops.consume().
59 * The operation should dispatch one or more tasks from the BPF
60 * scheduler to the dsq's using scx_bpf_dispatch(). The maximum number
61 * of tasks which can be dispatched in a single call is specified by the
62 * @dispatch_max_batch field of this struct.
63 */
64 void (*dispatch)(s32 cpu, struct task_struct *prev);
65
66 /**
67 * consume - Consume tasks from the dsq's to the local dsq for execution
68 * @cpu: CPU to consume tasks for
69 *
70 * Called when a CPU's local dsq is empty. The operation should transfer
71 * one or more tasks from the dsq's to the CPU's local dsq using
72 * scx_bpf_consume(). If this function fails to fill the local dsq,
73 * ops.dispatch() will be called.
74 *
75 * This operation is unnecessary if the BPF scheduler always dispatches
76 * either to one of the local dsq's or the global dsq. If implemented,
77 * this operation is also responsible for consuming the global_dsq.
78 */
79 void (*consume)(s32 cpu);
80
81 /**
82 * consume_final - Final consume call before going idle
83 * @cpu: CPU to consume tasks for
84 *
85 * After ops.consume() and .dispatch(), @cpu still doesn't have a task
86 * to execute and is about to go idle. This operation can be used to
87 * implement more aggressive consumption strategies. Otherwise
88 * equivalent to ops.consume().
89 */
90 void (*consume_final)(s32 cpu);
91
92 /**
93 * runnable - A task is becoming runnable on its associated CPU
94 * @p: task becoming runnable
95 * @enq_flags: %SCX_ENQ_*
96 *
97 * This and the following three functions can be used to track a task's
98 * execution state transitions. A task becomes ->runnable() on a CPU,
99 * and then goes through one or more ->running() and ->stopping() pairs
100 * as it runs on the CPU, and eventually becomes ->quiescent() when it's
101 * done running on the CPU.
102 *
103 * @p is becoming runnable on the CPU because it's
104 *
105 * - waking up (%SCX_ENQ_WAKEUP)
106 * - being moved from another CPU
107 * - being restored after temporarily taken off the queue for an
108 * attribute change.
109 *
110 * This and ->enqueue() are related but not coupled. This operation
111 * notifies @p's state transition and may not be followed by ->enqueue()
112 * e.g. when @p is being dispatched to a remote CPU. Likewise, a task
113 * may be ->enqueue()'d without being preceded by this operation e.g.
114 * after exhausting its slice.
115 */
116 void (*runnable)(struct task_struct *p, u64 enq_flags);
117
118 /**
119 * running - A task is starting to run on its associated CPU
120 * @p: task starting to run
121 *
122 * See ->runnable() for explanation on the task state notifiers.
123 */
124 void (*running)(struct task_struct *p);
125
126 /**
127 * stopping - A task is stopping execution
128 * @p: task stopping to run
129 * @runnable: is task @p still runnable?
130 *
131 * See ->runnable() for explanation on the task state notifiers. If
132 * !@runnable, ->quiescent() will be invoked after this operation
133 * returns.
134 */
135 void (*stopping)(struct task_struct *p, bool runnable);
136
137 /**
138 * quiescent - A task is becoming not runnable on its associated CPU
139 * @p: task becoming not runnable
140 * @deq_flags: %SCX_DEQ_*
141 *
142 * See ->runnable() for explanation on the task state notifiers.
143 *
144 * @p is becoming quiescent on the CPU because it's
145 *
146 * - sleeping (%SCX_DEQ_SLEEP)
147 * - being moved to another CPU
148 * - being temporarily taken off the queue for an attribute change
149 * (%SCX_DEQ_SAVE)
150 *
151 * This and ->dequeue() are related but not coupled. This operation
152 * notifies @p's state transition and may not be preceded by ->dequeue()
153 * e.g. when @p is being dispatched to a remote CPU.
154 */
155 void (*quiescent)(struct task_struct *p, u64 deq_flags);
156
157 /**
158 * yield - Yield CPU
159 * @from: yielding task
160 * @to: optional yield target task
161 *
162 * If @to is NULL, @from is yielding the CPU to other runnable tasks.
163 * The BPF scheduler should ensure that other available tasks are
164 * dispatched before the yielding task. Return value is ignored in this
165 * case.
166 *
167 * If @to is not-NULL, @from wants to yield the CPU to @to. If the bpf
168 * scheduler can implement the request, return %true; otherwise, %false.
169 */
170 bool (*yield)(struct task_struct *from, struct task_struct *to);
171
172 /**
173 * set_cpumask - Set CPU affinity
174 * @p: task to set CPU affinity for
175 * @cpumask: cpumask of cpus that @p can run on
176 *
177 * Update @p's CPU affinity to @cpumask.
178 */
179 void (*set_cpumask)(struct task_struct *p, struct cpumask *cpumask);
180
181 /**
182 * update_idle - Update the idle state of a CPU
183 * @cpu: CPU to udpate the idle state for
184 * @idle: whether entering or exiting the idle state
185 *
186 * This operation is called when @rq's CPU goes or leaves the idle
187 * state. By default, implementing this operation disables the built-in
188 * idle CPU tracking and the following helpers become unavailable:
189 *
190 * - scx_bpf_select_cpu_dfl()
191 * - scx_bpf_test_and_clear_cpu_idle()
192 * - scx_bpf_pick_idle_cpu()
193 * - scx_bpf_any_idle_cpu()
194 *
195 * The user also must implement ops.select_cpu() as the default
196 * implementation relies on scx_bpf_select_cpu_dfl().
197 *
198 * If you keep the built-in idle tracking, specify the
199 * %SCX_OPS_KEEP_BUILTIN_IDLE flag.
200 */
201 void (*update_idle)(s32 cpu, bool idle);
202
203 /**
204 * cpu_acquire - A CPU is becoming available to the BPF scheduler
205 * @cpu: The CPU being acquired by the BPF scheduler.
206 * @args: Acquire arguments, see the struct definition.
207 *
208 * A CPU that was previously released from the BPF scheduler is now once
209 * again under its control.
210 */
211 void (*cpu_acquire)(s32 cpu, struct scx_cpu_acquire_args *args);
212
213 /**
214 * cpu_release - A CPU is taken away from the BPF scheduler
215 * @cpu: The CPU being released by the BPF scheduler.
216 * @args: Release arguments, see the struct definition.
217 *
218 * The specified CPU is no longer under the control of the BPF
219 * scheduler. This could be because it was preempted by a higher
220 * priority sched_class, though there may be other reasons as well. The
221 * caller should consult @args->reason to determine the cause.
222 */
223 void (*cpu_release)(s32 cpu, struct scx_cpu_release_args *args);
224
225 /**
226 * cpu_online - A CPU became online
227 * @cpu: CPU which just came up
228 *
229 * @cpu just came online. @cpu doesn't call ->enqueue() or consume tasks
230 * associated with other CPUs beforehand.
231 */
232 void (*cpu_online)(s32 cpu);
233
234 /**
235 * cpu_offline - A CPU is going offline
236 * @cpu: CPU which is going offline
237 *
238 * @cpu is going offline. @cpu doesn't call ->enqueue() or consume tasks
239 * associated with other CPUs afterwards.
240 */
241 void (*cpu_offline)(s32 cpu);
242
243 /**
244 * prep_enable - Prepare to enable BPF scheduling for a task
245 * @p: task to prepare BPF scheduling for
246 * @args: enable arguments, see the struct definition
247 *
248 * Either we're loading a BPF scheduler or a new task is being forked.
249 * Prepare BPF scheduling for @p. This operation may block and can be
250 * used for allocations.
251 *
252 * Return 0 for success, -errno for failure. An error return while
253 * loading will abort loading of the BPF scheduler. During a fork, will
254 * abort the specific fork.
255 */
256 s32 (*prep_enable)(struct task_struct *p, struct scx_enable_args *args);
257
258 /**
259 * enable - Enable BPF scheduling for a task
260 * @p: task to enable BPF scheduling for
261 * @args: enable arguments, see the struct definition
262 *
263 * Enable @p for BPF scheduling. @p is now in the cgroup specified for
264 * the preceding prep_enable() and will start running soon.
265 */
266 void (*enable)(struct task_struct *p, struct scx_enable_args *args);
267
268 /**
269 * cancel_enable - Cancel prep_enable()
270 * @p: task being canceled
271 * @args: enable arguments, see the struct definition
272 *
273 * @p was prep_enable()'d but failed before reaching enable(). Undo the
274 * preparation.
275 */
276 void (*cancel_enable)(struct task_struct *p,
277 struct scx_enable_args *args);
278
279 /**
280 * disable - Disable BPF scheduling for a task
281 * @p: task to disable BPF scheduling for
282 *
283 * @p is exiting, leaving SCX or the BPF scheduler is being unloaded.
284 * Disable BPF scheduling for @p.
285 */
286 void (*disable)(struct task_struct *p);
287
288 /**
289 * cgroup_init - Initialize a cgroup
290 * @cgrp: cgroup being initialized
291 * @args: init arguments, see the struct definition
292 *
293 * Either the BPF scheduler is being loaded or @cgrp created, initialize
294 * @cgrp for sched_ext. This operation may block.
295 *
296 * Return 0 for success, -errno for failure. An error return while
297 * loading will abort loading of the BPF scheduler. During cgroup
298 * creation, it will abort the specific cgroup creation.
299 */
300 s32 (*cgroup_init)(struct cgroup *cgrp,
301 struct scx_cgroup_init_args *args);
302
303 /**
304 * cgroup_exit - Exit a cgroup
305 * @cgrp: cgroup being exited
306 *
307 * Either the BPF scheduler is being unloaded or @cgrp destroyed, exit
308 * @cgrp for sched_ext. This operation my block.
309 */
310 void (*cgroup_exit)(struct cgroup *cgrp);
311
312 /**
313 * cgroup_prep_move - Prepare a task to be moved to a different cgroup
314 * @p: task being moved
315 * @from: cgroup @p is being moved from
316 * @to: cgroup @p is being moved to
317 *
318 * Prepare @p for move from cgroup @from to @to. This operation may
319 * block and can be used for allocations.
320 *
321 * Return 0 for success, -errno for failure. An error return aborts the
322 * migration.
323 */
324 s32 (*cgroup_prep_move)(struct task_struct *p,
325 struct cgroup *from, struct cgroup *to);
326
327 /**
328 * cgroup_move - Commit cgroup move
329 * @p: task being moved
330 * @from: cgroup @p is being moved from
331 * @to: cgroup @p is being moved to
332 *
333 * Commit the move. @p is dequeued during this operation.
334 */
335 void (*cgroup_move)(struct task_struct *p,
336 struct cgroup *from, struct cgroup *to);
337
338 /**
339 * cgroup_cancel_move - Cancel cgroup move
340 * @p: task whose cgroup move is being canceled
341 * @from: cgroup @p was being moved from
342 * @to: cgroup @p was being moved to
343 *
344 * @p was cgroup_prep_move()'d but failed before reaching cgroup_move().
345 * Undo the preparation.
346 */
347 void (*cgroup_cancel_move)(struct task_struct *p,
348 struct cgroup *from, struct cgroup *to);
349
350 /**
351 * cgroup_set_weight - A cgroup's weight is being changed
352 * @cgrp: cgroup whose weight is being updated
353 * @weight: new weight [1..10000]
354 *
355 * Update @tg's weight to @weight.
356 */
357 void (*cgroup_set_weight)(struct cgroup *cgrp, u32 weight);
358
359 /*
360 * All online ops must come before ops.init().
361 */
362
363 /**
364 * init - Initialize the BPF scheduler
365 */
366 s32 (*init)(void);
367
368 /**
369 * exit - Clean up after the BPF scheduler
370 * @info: Exit info
371 */
372 void (*exit)(struct scx_exit_info *info);
373
374 /**
375 * dispatch_max_batch - Max nr of tasks that dispatch() can dispatch
376 */
377 u32 dispatch_max_batch;
378
379 /**
380 * flags - %SCX_OPS_* flags
381 */
382 u64 flags;
383
384 /**
385 * timeout_ms - The maximum amount of time, in milliseconds, that a
386 * runnable task should be able to wait before being scheduled. The
387 * maximum timeout may not exceed the default timeout of 30 seconds.
388 *
389 * Defaults to the maximum allowed timeout value of 30 seconds.
390 */
391 u32 timeout_ms;
392
393 /**
394 * name - BPF scheduler's name
395 *
396 * Must be a non-zero valid BPF object name including only isalnum(),
397 * '_' and '.' chars. Shows up in kernel.sched_ext_ops sysctl while the
398 * BPF scheduler is enabled.
399 */
400 char name[SCX_OPS_NAME_LEN];
401};对于scx机制而言, 唯一必须的字段只是.name字段, 并且是一个合法的BPF对象名称, 而其余所有的operation均是可选的.
struct rq_flags
1struct rq_flags {
2 unsigned long flags;
3 struct pin_cookie cookie;
4#ifdef CONFIG_SCHED_DEBUG
5 /*
6 * A copy of (rq::clock_update_flags & RQCF_UPDATED) for the
7 * current pin context is stashed here in case it needs to be
8 * restored in rq_repin_lock().
9 */
10 unsigned int clock_update_flags;
11#endif
12};scx_dsq_id_flags
1/*
2 * DSQ (dispatch queue) IDs are 64bit of the format:
3 *
4 * Bits: [63] [62 .. 0]
5 * [ B] [ ID ]
6 *
7 * B: 1 for IDs for built-in DSQs, 0 for ops-created user DSQs
8 * ID: 63 bit ID
9 *
10 * Built-in IDs:
11 *
12 * Bits: [63] [62] [61..32] [31 .. 0]
13 * [ 1] [ L] [ R ] [ V ]
14 *
15 * 1: 1 for built-in DSQs.
16 * L: 1 for LOCAL_ON DSQ IDs, 0 for others
17 * V: For LOCAL_ON DSQ IDs, a CPU number. For others, a pre-defined value.
18 */
19enum scx_dsq_id_flags {
20 SCX_DSQ_FLAG_BUILTIN = 1LLU << 63,
21 SCX_DSQ_FLAG_LOCAL_ON = 1LLU << 62,
22
23 SCX_DSQ_INVALID = SCX_DSQ_FLAG_BUILTIN | 0,
24 SCX_DSQ_GLOBAL = SCX_DSQ_FLAG_BUILTIN | 1,
25 SCX_DSQ_LOCAL = SCX_DSQ_FLAG_BUILTIN | 2,
26 SCX_DSQ_LOCAL_ON = SCX_DSQ_FLAG_BUILTIN | SCX_DSQ_FLAG_LOCAL_ON,
27 SCX_DSQ_LOCAL_CPU_MASK = 0xffffffffLLU,
28};enq_flags
1enum scx_enq_flags {
2 /* expose select ENQUEUE_* flags as enums */
3 SCX_ENQ_WAKEUP = ENQUEUE_WAKEUP,
4 SCX_ENQ_HEAD = ENQUEUE_HEAD,
5
6 /* high 32bits are ext specific flags */
7
8 /*
9 * Set the following to trigger preemption when calling
10 * scx_bpf_dispatch() with a local dsq as the target. The slice of the
11 * current task is cleared to zero and the CPU is kicked into the
12 * scheduling path. Implies %SCX_ENQ_HEAD.
13 */
14 SCX_ENQ_PREEMPT = 1LLU << 32,
15
16 /*
17 * The task being enqueued was previously enqueued on the current CPU's
18 * %SCX_DSQ_LOCAL, but was removed from it in a call to the
19 * bpf_scx_reenqueue_local() kfunc. If bpf_scx_reenqueue_local() was
20 * invoked in a ->cpu_release() callback, and the task is again
21 * dispatched back to %SCX_LOCAL_DSQ by this current ->enqueue(), the
22 * task will not be scheduled on the CPU until at least the next invocation
23 * of the ->cpu_acquire() callback.
24 */
25 SCX_ENQ_REENQ = 1LLU << 40,
26
27 /*
28 * The task being enqueued is the only task available for the cpu. By
29 * default, ext core keeps executing such tasks but when
30 * %SCX_OPS_ENQ_LAST is specified, they're ops.enqueue()'d with
31 * %SCX_ENQ_LAST and %SCX_ENQ_LOCAL flags set.
32 *
33 * If the BPF scheduler wants to continue executing the task,
34 * ops.enqueue() should dispatch the task to %SCX_DSQ_LOCAL immediately.
35 * If the task gets queued on a different dsq or the BPF side, the BPF
36 * scheduler is responsible for triggering a follow-up scheduling event.
37 * Otherwise, Execution may stall.
38 */
39 SCX_ENQ_LAST = 1LLU << 41,
40
41 /*
42 * A hint indicating that it's advisable to enqueue the task on the
43 * local dsq of the currently selected CPU. Currently used by
44 * select_cpu_dfl() and together with %SCX_ENQ_LAST.
45 */
46 SCX_ENQ_LOCAL = 1LLU << 42,
47
48 /* high 8 bits are internal */
49 __SCX_ENQ_INTERNAL_MASK = 0xffLLU << 56,
50
51 SCX_ENQ_CLEAR_OPSS = 1LLU << 56,
52};task_struct
1struct task_struct {
2 ...
3#ifdef CONFIG_SCHED_CLASS_EXT
4 struct sched_ext_entity scx;
5#endif
6 const struct sched_class *sched_class;
7 ...sched_ext_entity
1/*
2 * The following is embedded in task_struct and contains all fields necessary
3 * for a task to be scheduled by SCX.
4 */
5struct sched_ext_entity {
6 struct scx_dispatch_q *dsq;
7 struct list_head dsq_node;
8 struct list_head watchdog_node;
9 u32 flags; /* protected by rq lock */
10 u32 weight;
11 s32 sticky_cpu;
12 s32 holding_cpu;
13 atomic64_t ops_state;
14 unsigned long runnable_at;
15
16 /* BPF scheduler modifiable fields */
17
18 /*
19 * Runtime budget in nsecs. This is usually set through
20 * scx_bpf_dispatch() but can also be modified directly by the BPF
21 * scheduler. Automatically decreased by SCX as the task executes. On
22 * depletion, a scheduling event is triggered.
23 *
24 * This value is cleared to zero if the task is preempted by
25 * %SCX_KICK_PREEMPT and shouldn't be used to determine how long the
26 * task ran. Use p->se.sum_exec_runtime instead.
27 */
28 u64 slice;
29
30 /*
31 * If set, reject future sched_setscheduler(2) calls updating the policy
32 * to %SCHED_EXT with -%EACCES.
33 *
34 * If set from ops.prep_enable() and the task's policy is already
35 * %SCHED_EXT, which can happen while the BPF scheduler is being loaded
36 * or by inhering the parent's policy during fork, the task's policy is
37 * rejected and forcefully reverted to %SCHED_NORMAL. The number of such
38 * events are reported through /sys/kernel/debug/sched_ext::nr_rejected.
39 */
40 bool disallow; /* reject switching into SCX */
41
42 /* cold fields */
43 struct list_head tasks_node;
44#ifdef CONFIG_EXT_GROUP_SCHED
45 struct cgroup *cgrp_moving_from;
46#endif
47};这是嵌入到task_struct结构中的一个结构体字段scx
dispatch_buf_ent
1/* dispatch buf */
2struct dispatch_buf_ent {
3 struct task_struct *task;
4 u64 qseq;
5 u64 dsq_id;
6 u64 enq_flags;
7};
8
9static u32 dispatch_max_batch;
10static struct dispatch_buf_ent __percpu *dispatch_buf;
11static DEFINE_PER_CPU(u32, dispatch_buf_cursor);dispatch_buf大概的初始化为:
1dispatch_buf = __alloc_percpu(sizeof(dispatch_buf[0]) * dispatch_max_batch,
2 __alignof__(dispatch_buf[0]));dispatch_buf[0]实际是一个dispatch_buf_ent结构体的类型, 尽管还没有初始化, 但是可以用于计算sizeof, 这一点值得学习. 使用一个结构体指针即可统一的实现malloc, 而不需要在malloc内部关注指针指向的类型..
consume_ctx
1/* consume context */
2struct consume_ctx {
3 struct rq *rq;
4 struct rq_flags *rf;
5};
6
7static DEFINE_PER_CPU(struct consume_ctx, consume_ctx);[core]scx_bpf_dispatch
1/**
2 * scx_bpf_dispatch - Dispatch a task to a dsq
3 * @p: task_struct to dispatch
4 * @dsq_id: dsq to dispatch to
5 * @slice: duration @p can run for in nsecs
6 * @enq_flags: SCX_ENQ_*
7 *
8 * Dispatch @p to the dsq identified by @dsq_id. It is safe to call this
9 * function spuriously. Can be called from ops.enqueue() and ops.dispatch().
10 *
11 * When called from ops.enqueue(), it's for direct dispatch and @p must match
12 * the task being enqueued. Also, %SCX_DSQ_LOCAL_ON can't be used to target the
13 * local dsq of a CPU other than the enqueueing one. Use ops.select_cpu() to be
14 * on the target CPU in the first place.
15 *
16 * When called from ops.dispatch(), there are no restrictions on @p or @dsq_id
17 * and this function can be called upto ops.dispatch_max_batch times to dispatch
18 * multiple tasks. scx_bpf_dispatch_nr_slots() returns the number of the
19 * remaining slots.
20 *
21 * @p is allowed to run for @slice. The scheduling path is triggered on slice
22 * exhaustion. If zero, the current residual slice is maintained. If
23 * %SCX_SLICE_INF, @p never expires and the BPF scheduler must kick the CPU with
24 * scx_bpf_kick_cpu() to trigger scheduling.
25 */
26void scx_bpf_dispatch(struct task_struct *p, u64 dsq_id, u64 slice,
27 u64 enq_flags)
28{
29 struct task_struct *ddsp_task;
30 int idx;
31
32 lockdep_assert_irqs_disabled();
33
34 if (unlikely(!p)) {
35 scx_ops_error("called with NULL task");
36 return;
37 }
38
39 if (unlikely(enq_flags & __SCX_ENQ_INTERNAL_MASK)) {
40 scx_ops_error("invalid enq_flags 0x%llx", enq_flags);
41 return;
42 }
43
44 if (slice)
45 p->scx.slice = slice;
46 else
47 p->scx.slice = p->scx.slice ?: 1;
48
49 ddsp_task = __this_cpu_read(direct_dispatch_task);
50 if (ddsp_task) {
51 direct_dispatch(ddsp_task, p, dsq_id, enq_flags);
52 return;
53 }
54
55 idx = __this_cpu_read(dispatch_buf_cursor);
56 if (unlikely(idx >= dispatch_max_batch)) {
57 scx_ops_error("dispatch buffer overflow");
58 return;
59 }
60
61 this_cpu_ptr(dispatch_buf)[idx] = (struct dispatch_buf_ent){
62 .task = p,
63 .qseq = atomic64_read(&p->scx.ops_state) & SCX_OPSS_QSEQ_MASK,
64 .dsq_id = dsq_id,
65 .enq_flags = enq_flags,
66 };
67 __this_cpu_inc(dispatch_buf_cursor);
68}总的来说, 该函数将指定的任务分发到指定的每CPU的dsq队列中, 同时维护每CPU结构和每任务结构的双向连接关系, 当任务开启了preempt标志后还会手动地触发一次rq的重调度. 下面对其具体的细节进行说明:
-
内核有死锁检测的功能lockdep, 该功能由CONFIG_PROVE_LOCKING内核选项定义, 具体的细节不予深究.
lockdep_assert_irqs_disabled是一个与此有关的宏函数. 当开启了内核死锁检测后, 该函数将执行:c1#define lockdep_assert_irqs_disabled() \ 2do { \ 3 WARN_ON_ONCE(__lockdep_enabled && this_cpu_read(hardirqs_enabled)); \ 4} while (0)可以认为该函数其实就是个assert, 保证此时中断是关闭的.
-
随后做一些基本的检查, 比如p是否为空, 以及是否设置了非法的enq_flags
-
结合
sched_ext_entity的slice字段的内容可知, 该字段如果为0则意味着其被%SCX_KICK_PREEMPT抢占, 此时该字段应该无意义; 而如果此时dispatch方法传入的slice为0, 则按理该保持其状态不变, 但是当其原状态的slice为0时则应该置为一个非零的值, 原因在于? Todos: 如果传入的slice为0, 则其原本的slice状态将被保持. 不过由于结合sched_ext_entity的slice字段的内容可知, 该字段如果为0则意味着其被带有%SCX_KICK_PREEMPT标志的任务抢占, 此时该字段不能用于决定当前任务能够执行多久; 因而将其修改为一个非零结果. -
随后读一个当前CPU的每CPU变量
direct_dispatch_task, 如果不空, 则说明要进行直接分发, 进而执行direct_dispatch函数.- 该变量其实只是一个标志位, 其在
direct_dispatch中写为一个非法的地址, 或者在do_enqueue_task中被设置为一个task_struct的内容(Todo), 并在scx_bpf_dispatch中被读取, 有关该变量的使用, 还需要调研do_enqueue_task的内容. Todo
c1/* 2 * Direct dispatch marker. 3 * 4 * Non-NULL values are used for direct dispatch from enqueue path. A valid 5 * pointer points to the task currently being enqueued. An ERR_PTR value is used 6 * to indicate that direct dispatch has already happened. 7 */ 8static DEFINE_PER_CPU(struct task_struct *, direct_dispatch_task); - 该变量其实只是一个标志位, 其在
-
如果为空, 则Todo. 首先读一个
dispatch_buf_cursor变量, 这是一个每CPU的u32类型, 指向当前cpu对应的buffer idx. 相关的定义参考 dispatch_buf_ent. 对该idx做一些检查后, 访问对应的buffer内容, 并将当前任务和dsq写入该buffer. 在写完buffer后会对idx自增, 当buffer表项用光后则报错, 同时其余代码部分貌似就没有对idx的操作了. Todo: 该idx什么时候初始化的? 为什么需要这样一块buffer结构?
direct_dispatch
1static void direct_dispatch(struct task_struct *ddsp_task, struct task_struct *p,
2 u64 dsq_id, u64 enq_flags)
3{
4 struct scx_dispatch_q *dsq;
5
6 /* @p must match the task which is being enqueued */
7 if (unlikely(p != ddsp_task)) {
8 if (IS_ERR(ddsp_task))
9 scx_ops_error("%s[%d] already direct-dispatched",
10 p->comm, p->pid);
11 else
12 scx_ops_error("enqueueing %s[%d] but trying to direct-dispatch %s[%d]",
13 ddsp_task->comm, ddsp_task->pid,
14 p->comm, p->pid);
15 return;
16 }
17
18 /*
19 * %SCX_DSQ_LOCAL_ON is not supported during direct dispatch because
20 * dispatching to the local dsq of a different CPU requires unlocking
21 * the current rq which isn't allowed in the enqueue path. Use
22 * ops.select_cpu() to be on the target CPU and then %SCX_DSQ_LOCAL.
23 */
24 if (unlikely((dsq_id & SCX_DSQ_LOCAL_ON) == SCX_DSQ_LOCAL_ON)) {
25 scx_ops_error("SCX_DSQ_LOCAL_ON can't be used for direct-dispatch");
26 return;
27 }
28
29 dsq = find_dsq_for_dispatch(task_rq(p), dsq_id, p);
30 dispatch_enqueue(dsq, p, enq_flags | SCX_ENQ_CLEAR_OPSS);
31
32 /*
33 * Mark that dispatch already happened by spoiling direct_dispatch_task
34 * with a non-NULL value which can never match a valid task pointer.
35 */
36 __this_cpu_write(direct_dispatch_task, ERR_PTR(-ESRCH));
37}-
该函数首先做检查, ddsp必须和p一致, Todo: 这两个有啥区别, 谁传进来的, 传进来的什么, 以及why
-
不允许
%SCX_DSQ_LOCAL_ON发生直接分发, 原因是在enqueue内核路径上不允许解锁rq, 因而无法向其他CPU的本地dsq分发任务, Todo: 啥是rq, 以及rq如何和dsq相关? -
task_rq将获取p任务所在的CPU的rq队列(具体代码未读, 猜测如此), 将rq队列传入给find_dsq_for_dispatch获取dsq队列指针.c1#define task_rq(p) cpu_rq(task_cpu(p)) -
调用
dispatch_enqueue将p插入到对应的dsq中, 并带有SCX_ENQ_CLEAR_OPSS标志. Todo -
最后写
direct_dispatch_task指针, 写入一个非法的位置, 表示直接分发已经发生过了. 与该函数在开头校验该指针是否合法相对应.
find_dsq_for_dispatch
1static struct scx_dispatch_q *find_dsq_for_dispatch(struct rq *rq, u64 dsq_id,
2 struct task_struct *p)
3{
4 struct scx_dispatch_q *dsq;
5
6 if (dsq_id == SCX_DSQ_LOCAL)
7 return &rq->scx.local_dsq;
8
9 dsq = find_non_local_dsq(dsq_id);
10 if (unlikely(!dsq)) {
11 scx_ops_error("non-existent dsq 0x%llx for %s[%d]",
12 dsq_id, p->comm, p->pid);
13 return &scx_dsq_global;
14 }
15
16 return dsq;
17}-
本地DSQ则直接返回, 不然根据
dsq_id调用函数find_non_local_dsq获取对应的dsq指针 -
如果
dsq_id对应的dsq烂了, 则缺省返回全局dsq
find_non_local_dsq
1static struct scx_dispatch_q *find_non_local_dsq(u64 dsq_id)
2{
3 lockdep_assert(rcu_read_lock_any_held());
4
5 if (dsq_id == SCX_DSQ_GLOBAL)
6 return &scx_dsq_global;
7 else
8 return rhashtable_lookup_fast(&dsq_hash, &dsq_id,
9 dsq_hash_params);
10}全局DSQ则直接返回, 不然查Hash表返回dsq_id对应的dsq.
Todo: 谁会对这个hash表增删改查?
rhashtable_lookup_fast
1/**
2 * rhashtable_lookup_fast - search hash table, without RCU read lock
3 * @ht: hash table
4 * @key: the pointer to the key
5 * @params: hash table parameters
6 *
7 * Computes the hash value for the key and traverses the bucket chain looking
8 * for a entry with an identical key. The first matching entry is returned.
9 *
10 * Only use this function when you have other mechanisms guaranteeing
11 * that the object won't go away after the RCU read lock is released.
12 *
13 * Returns the first entry on which the compare function returned true.
14 */
15static inline void *rhashtable_lookup_fast(
16 struct rhashtable *ht, const void *key,
17 const struct rhashtable_params params)
18{
19 void *obj;
20
21 rcu_read_lock();
22 obj = rhashtable_lookup(ht, key, params);
23 rcu_read_unlock();
24
25 return obj;
26}快速哈希表查询函数, 不上RCU读锁.
dispatch_enqueue
1static void dispatch_enqueue(struct scx_dispatch_q *dsq, struct task_struct *p,
2 u64 enq_flags)
3{
4 bool is_local = dsq->id == SCX_DSQ_LOCAL;
5
6 WARN_ON_ONCE(p->scx.dsq || !list_empty(&p->scx.dsq_node));
7
8 if (!is_local) {
9 raw_spin_lock(&dsq->lock);
10 if (unlikely(dsq->id == SCX_DSQ_INVALID)) {
11 scx_ops_error("attempting to dispatch to a destroyed dsq");
12 /* fall back to the global dsq */
13 raw_spin_unlock(&dsq->lock);
14 dsq = &scx_dsq_global;
15 raw_spin_lock(&dsq->lock);
16 }
17 }
18
19 if (enq_flags & (SCX_ENQ_HEAD | SCX_ENQ_PREEMPT))
20 list_add(&p->scx.dsq_node, &dsq->fifo);
21 else
22 list_add_tail(&p->scx.dsq_node, &dsq->fifo);
23 dsq->nr++;
24 p->scx.dsq = dsq;
25
26 /*
27 * We're transitioning out of QUEUEING or DISPATCHING. store_release to
28 * match waiters' load_acquire.
29 */
30 if (enq_flags & SCX_ENQ_CLEAR_OPSS)
31 atomic64_set_release(&p->scx.ops_state, SCX_OPSS_NONE);
32
33 if (is_local) {
34 struct rq *rq = container_of(dsq, struct rq, scx.local_dsq);
35 bool preempt = false;
36
37 if ((enq_flags & SCX_ENQ_PREEMPT) && p != rq->curr &&
38 rq->curr->sched_class == &ext_sched_class) {
39 rq->curr->scx.slice = 0;
40 preempt = true;
41 }
42
43 if (preempt || sched_class_above(&ext_sched_class,
44 rq->curr->sched_class))
45 resched_curr(rq);
46 } else {
47 raw_spin_unlock(&dsq->lock);
48 }
49}这是一个static内部函数, 做的工作主要是将task_struct对应的进程插入到dsq中:
-
如果该dsq不是一个CPU本地的dsq, 则需要上锁避免多CPU的竞争; 同时检查一下其是否还有效, 因为可能被其他的CPU进程销毁了, 如果已经失效则缺省变为全局dsq.
-
检查入队标志, 据此决定是否插入到队头或队尾, 并维护
dsq和task_struct数据结构中的一些字段内容, 使得每CPU变量struct scx_dispatch_q中的fifo链表可以与任务描述符中的scx.dsq_node相关联 -
随后根据
SCX_ENQ_CLEAR_OPSS与ops_state做了原子写, 写入SCX_OPSS_NONE, 完全不知道这是干啥. Todo -
如果dsq是全局dsq释放锁后即可返回
-
如果是CPU本地dsq, 则根据
container_of宏获取包含该dsq字段的rq结构体的指针. 如果设置了SCX_ENQ_PREEMPT标志且p不是rq正在运行的进程且调度类选中了sched_ext类, 则设置slice为0, 同时设置preempt标志为True.sched_class_above用于比较调度类的优先级, 如果第一个拥有更高的优先级则返回1, 这种情况下也将启用preempt标志. preempt意味着执行resched_curr原生内核函数.resched_curr内核函数不会立刻进行进程切换, 其只是简单的在当前rq的任务上设置TIF_NEED_RESCHED标志, 调度器后续才会进一步调用. 参考问题: <c -resched_currin does not reschedule the current task instantly - Stack Overflow>
[core]scx_bpf_consume
1/**
2 * scx_bpf_consume - Transfer a task from a dsq to the current CPU's local dsq
3 * @dsq_id: dsq to consume
4 *
5 * Consume a task from the dsq identified by @dsq_id and transfer it to the
6 * current CPU's local dsq for execution. Can only be called from
7 * ops.consume[_final]().
8 *
9 * Returns %true if a task has been consumed, %false if there isn't any task to
10 * consume.
11 */
12bool scx_bpf_consume(u64 dsq_id)
13{
14 struct consume_ctx *cctx = this_cpu_ptr(&consume_ctx);
15 struct scx_dispatch_q *dsq;
16
17 dsq = find_non_local_dsq(dsq_id);
18 if (unlikely(!dsq)) {
19 scx_ops_error("invalid dsq_id 0x%016llx", dsq_id);
20 return false;
21 }
22
23 return consume_dispatch_q(cctx->rq, cctx->rf, dsq);
24}该函数将从指定dsq_id的dsq中取任务到本地dsq:
-
cctx是一个每CPU变量
struct consume_ctx, 其中有一个struct rq和一个struct rq_flags; Todo: 为什么需要单独开一份每CPU变量, 而不是直接取自己的rq? -
通过
dsq_id以及find_non_local_dsq获取dsq队列, 如果hash查表失败则报错, 不然进一步执行consume_dispatch_q
consume_dispatch_q
1static bool consume_dispatch_q(struct rq *rq, struct rq_flags *rf,
2 struct scx_dispatch_q *dsq)
3{
4 struct scx_rq *scx_rq = &rq->scx;
5 struct task_struct *p;
6 struct rq *task_rq;
7 bool moved = false;
8retry:
9 if (list_empty(&dsq->fifo))
10 return false;
11
12 raw_spin_lock(&dsq->lock);
13 list_for_each_entry(p, &dsq->fifo, scx.dsq_node) {
14 task_rq = task_rq(p);
15 if (rq == task_rq)
16 goto this_rq;
17 if (likely(rq->online) && !is_migration_disabled(p) &&
18 cpumask_test_cpu(cpu_of(rq), p->cpus_ptr))
19 goto remote_rq;
20 }
21 raw_spin_unlock(&dsq->lock);
22 return false;
23
24this_rq:
25 /* @dsq is locked and @p is on this rq */
26 WARN_ON_ONCE(p->scx.holding_cpu >= 0);
27 list_move_tail(&p->scx.dsq_node, &scx_rq->local_dsq.fifo);
28 dsq->nr--;
29 scx_rq->local_dsq.nr++;
30 p->scx.dsq = &scx_rq->local_dsq;
31 raw_spin_unlock(&dsq->lock);
32 return true;
33
34remote_rq:
35#ifdef CONFIG_SMP
36 /*
37 * @dsq is locked and @p is on a remote rq. @p is currently protected by
38 * @dsq->lock. We want to pull @p to @rq but may deadlock if we grab
39 * @task_rq while holding @dsq and @rq locks. As dequeue can't drop the
40 * rq lock or fail, do a little dancing from our side. See
41 * move_task_to_local_dsq().
42 */
43 WARN_ON_ONCE(p->scx.holding_cpu >= 0);
44 list_del_init(&p->scx.dsq_node);
45 dsq->nr--;
46 p->scx.holding_cpu = raw_smp_processor_id();
47 raw_spin_unlock(&dsq->lock);
48
49 rq_unpin_lock(rq, rf);
50 double_lock_balance(rq, task_rq);
51 rq_repin_lock(rq, rf);
52
53 moved = move_task_to_local_dsq(rq, p);
54
55 double_unlock_balance(rq, task_rq);
56#endif /* CONFIG_SMP */
57 if (likely(moved))
58 return true;
59 goto retry;
60}-
队列为空, 无法consume, 返回false
-
所有的dsq_node应该都是用一个双向链表连接起来的, 关于双向链表可以参考 <ULK 进程 - rqdmap | blog>,
dsq->fifo应该存储了该链表的表头, 因而list_for_each_entry宏遍历task_struct的scx.dsq_node成员,scx实际就是sched_ext_entity结构体类型; 随后一直循环访问到了&dsq->fifo为止结束, 暴露出p指针为每次遍历的结果, 此时的p正是该dsq中的某个任务的指针. -
通过
task_rq获取当前任务所对应的rq, 如果该rq与CPU本地dsq(传入的rq和rf都是CPU本地dsq结构内的内容)所对应的rq一致则跳转到this_rq代码段进一步执行; 不然则做一些检查后进入remote_rq代码段. -
对于
this_rq而言, 将p对应的节点移动到当前运行队列的dsq队列中, 同时维护一些数据字段即可. -
对于
remote_rq而言, (显然必须考虑带有SMP配置的时候)由于需要把一个非本CPU的任务p移动到本地dsq中, 由于p被dsq的锁所保护, 因而争取该锁可能会导致死锁, Todo: why? 由于dequeue不会放弃锁或者失败, 因而可以使用一些小小的trick, 即move_task_to_local_dsq函数, 不过这里暂时不深究了. Todo
[core]scx_bpf_kick_cpu
1/**
2 * scx_bpf_kick_cpu - Trigger reschedule on a CPU
3 * @cpu: cpu to kick
4 * @flags: SCX_KICK_* flags
5 *
6 * Kick @cpu into rescheduling. This can be used to wake up an idle CPU or
7 * trigger rescheduling on a busy CPU. This can be called from any online
8 * scx_ops operation and the actual kicking is performed asynchronously through
9 * an irq work.
10 */
11void scx_bpf_kick_cpu(s32 cpu, u64 flags)
12{
13 if (!ops_cpu_valid(cpu)) {
14 scx_ops_error("invalid cpu %d", cpu);
15 return;
16 }
17#ifdef CONFIG_SMP
18 {
19 struct rq *rq;
20
21 preempt_disable();
22 rq = this_rq();
23
24 /*
25 * Actual kicking is bounced to kick_cpus_irq_workfn() to avoid
26 * nesting rq locks. We can probably be smarter and avoid
27 * bouncing if called from ops which don't hold a rq lock.
28 */
29 cpumask_set_cpu(cpu, rq->scx.cpus_to_kick);
30 if (flags & SCX_KICK_PREEMPT)
31 cpumask_set_cpu(cpu, rq->scx.cpus_to_preempt);
32 if (flags & SCX_KICK_WAIT)
33 cpumask_set_cpu(cpu, rq->scx.cpus_to_wait);
34
35 irq_work_queue(&rq->scx.kick_cpus_irq_work);
36 preempt_enable();
37 }
38#endif
39}该函数会唤醒一个闲置的CPU或者触发一个忙碌CPU重新进行调度. 其可以被任意执行中的scx_ops调用, 实际的kick并不立刻执行, 而是通过irq异步的执行:
-
函数内部首先检查cpu号是否合法, 随后关闭内核抢占, 获取当前CPU的rq, 并将该CPU打上rq内部的
cpus_to_kick标志. 再根据flags的内容为CPU打上几个其余的标志后, 将cpumask_var_t传给irq工作队列, 最后打开内核抢占即可. -
关于
kick_cpus_irq_work, 这是一个struct irq_work类型的成员, 大概长这样, 有关irq_work的也不多去关注了.c1struct irq_work { 2 struct __call_single_node node; 3 void (*func)(struct irq_work *); 4 struct rcuwait irqwait; 5};
ops_cpu_valid
1/**
2 * ops_cpu_valid - Verify a cpu number
3 * @cpu: cpu number which came from a BPF ops
4 *
5 * @cpu is a cpu number which came from the BPF scheduler and can be any value.
6 * Verify that it is in range and one of the possible cpus.
7 */
8static bool ops_cpu_valid(s32 cpu)
9{
10 return likely(cpu >= 0 && cpu < nr_cpu_ids && cpu_possible(cpu));
11}[help]scx_bpf_dsq_nr_queued
1/**
2 * scx_bpf_dsq_nr_queued - Return the number of queued tasks
3 * @dsq_id: id of the dsq
4 *
5 * Return the number of tasks in the dsq matching @dsq_id. If not found,
6 * -%ENOENT is returned. Can be called from any non-sleepable online scx_ops
7 * operations.
8 */
9s32 scx_bpf_dsq_nr_queued(u64 dsq_id)
10{
11 struct scx_dispatch_q *dsq;
12
13 lockdep_assert(rcu_read_lock_any_held());
14
15 if (dsq_id == SCX_DSQ_LOCAL) {
16 return this_rq()->scx.local_dsq.nr;
17 } else if ((dsq_id & SCX_DSQ_LOCAL_ON) == SCX_DSQ_LOCAL_ON) {
18 s32 cpu = dsq_id & SCX_DSQ_LOCAL_CPU_MASK;
19
20 if (ops_cpu_valid(cpu))
21 return cpu_rq(cpu)->scx.local_dsq.nr;
22 } else {
23 dsq = find_non_local_dsq(dsq_id);
24 if (dsq)
25 return dsq->nr;
26 }
27 return -ENOENT;
28}返回指定dsq_id中入队任务的数量, 主要的if-else分支是用于处理不同种类的dsq, 代码内容比较简单:
-
如果查询本地dsq的话, 则直接通过rq的内部数据结构逐渐访问到
scx_dispatch_q结构体内容, 获取其中的nr字段即可 -
不然, 则进一步判断是不是一个带有
SCX_DSQ_LOCAL_ON标志的dsq_id, Todo: 该标志是什么时候会带上? 根据后续的mask猜测, 这表示这是某个其他CPU的本地dsq, 根据获取的cpu号读取该cpu下rq的对应数据结构. -
最后, 说明这不是一个CPU本地的dsq结构, 则通过
find_non_local_dsq获取dsq的指针, 并读取其中的nr内容.
[help]scx_bpf_find_task_by_pid
1struct task_struct *scx_bpf_find_task_by_pid(s32 pid)
2{
3 return find_task_by_pid_ns(pid, &init_pid_ns);
4}内核eBPF支持机制
bpf_struct_ops
1struct bpf_struct_ops {
2 const struct bpf_verifier_ops *verifier_ops;
3 int (*init)(struct btf *btf);
4 int (*check_member)(const struct btf_type *t,
5 const struct btf_member *member,
6 struct bpf_prog *prog);
7 int (*init_member)(const struct btf_type *t,
8 const struct btf_member *member,
9 void *kdata, const void *udata);
10 int (*reg)(void *kdata);
11 void (*unreg)(void *kdata);
12 const struct btf_type *type;
13 const struct btf_type *value_type;
14 const char *name;
15 struct btf_func_model func_models[BPF_STRUCT_OPS_MAX_NR_MEMBERS];
16 u32 type_id;
17 u32 value_id;
18};scx_ops_enable_state
1enum scx_ops_enable_state {
2 SCX_OPS_PREPPING,
3 SCX_OPS_ENABLING,
4 SCX_OPS_ENABLED,
5 SCX_OPS_DISABLING,
6 SCX_OPS_DISABLED,
7};scx_ent_flags
1/* scx_entity.flags */
2enum scx_ent_flags {
3 SCX_TASK_QUEUED = 1 << 0, /* on ext runqueue */
4 SCX_TASK_BAL_KEEP = 1 << 1, /* balance decided to keep current */
5 SCX_TASK_ENQ_LOCAL = 1 << 2, /* used by scx_select_cpu_dfl() to set SCX_ENQ_LOCAL */
6
7 SCX_TASK_OPS_PREPPED = 1 << 3, /* prepared for BPF scheduler enable */
8 SCX_TASK_OPS_ENABLED = 1 << 4, /* task has BPF scheduler enabled */
9
10 SCX_TASK_WATCHDOG_RESET = 1 << 5, /* task watchdog counter should be reset */
11
12 SCX_TASK_CURSOR = 1 << 6, /* iteration cursor, not a task */
13};scx_exit_*
1enum scx_exit_type {
2 SCX_EXIT_NONE,
3 SCX_EXIT_DONE,
4
5 SCX_EXIT_UNREG = 64, /* BPF unregistration */
6 SCX_EXIT_SYSRQ, /* requested by 'S' sysrq */
7
8 SCX_EXIT_ERROR = 1024, /* runtime error, error msg contains details */
9 SCX_EXIT_ERROR_BPF, /* ERROR but triggered through scx_bpf_error() */
10 SCX_EXIT_ERROR_STALL, /* watchdog detected stalled runnable tasks */
11};
12
13/*
14 * scx_exit_info is passed to ops.exit() to describe why the BPF scheduler is
15 * being disabled.
16 */
17struct scx_exit_info {
18 /* %SCX_EXIT_* - broad category of the exit reason */
19 enum scx_exit_type type;
20 /* textual representation of the above */
21 char reason[SCX_EXIT_REASON_LEN];
22 /* number of entries in the backtrace */
23 u32 bt_len;
24 /* backtrace if exiting due to an error */
25 unsigned long bt[SCX_EXIT_BT_LEN];
26 /* extra message */
27 char msg[SCX_EXIT_MSG_LEN];
28};
29
30
31static atomic_t scx_exit_type = ATOMIC_INIT(SCX_EXIT_DONE);
32static struct scx_exit_info scx_exit_info;sched_enq_and_set_ctx
1struct sched_enq_and_set_ctx {
2 struct task_struct *p;
3 int queue_flags;
4 bool queued;
5 bool running;
6};[core]bpf_sched_ext_ops
1/* "extern" to avoid sparse warning, only used in this file */
2extern struct bpf_struct_ops bpf_sched_ext_ops;
3
4struct bpf_struct_ops bpf_sched_ext_ops = {
5 .verifier_ops = &bpf_scx_verifier_ops,
6 .reg = bpf_scx_reg,
7 .unreg = bpf_scx_unreg,
8 .check_member = bpf_scx_check_member,
9 .init_member = bpf_scx_init_member,
10 .init = bpf_scx_init,
11 .name = "sched_ext_ops",
12};根据 <sched_ext机制研究 - rqdmap | blog>中的内容所说, 该结构体应该是实际上与bpf机制交互的结构体.
下面我们考虑研究一下其中具体的几个函数.
[core]bpf_scx_reg
该函数本质调用了bpf_ops_enable, 啥也没干:
1static int bpf_scx_reg(void *kdata)
2{
3 return scx_ops_enable(kdata);
4}而enable函数则干了很多事情:
1static int scx_ops_enable(struct sched_ext_ops *ops)
2{
3 struct scx_task_iter sti;
4 struct task_struct *p;
5 int i, ret;
6
7 mutex_lock(&scx_ops_enable_mutex);
8
9 if (!scx_ops_helper) {
10 WRITE_ONCE(scx_ops_helper,
11 scx_create_rt_helper("sched_ext_ops_helper"));
12 if (!scx_ops_helper) {
13 ret = -ENOMEM;
14 goto err_unlock;
15 }
16 }
17
18 if (scx_ops_enable_state() != SCX_OPS_DISABLED) {
19 ret = -EBUSY;
20 goto err_unlock;
21 }
22
23 ret = rhashtable_init(&dsq_hash, &dsq_hash_params);
24 if (ret)
25 goto err_unlock;
26
27 /*
28 * Set scx_ops, transition to PREPPING and clear exit info to arm the
29 * disable path. Failure triggers full disabling from here on.
30 */
31 scx_ops = *ops;
32
33 WARN_ON_ONCE(scx_ops_set_enable_state(SCX_OPS_PREPPING) !=
34 SCX_OPS_DISABLED);
35
36 memset(&scx_exit_info, 0, sizeof(scx_exit_info));
37 atomic_set(&scx_exit_type, SCX_EXIT_NONE);
38 warned_zero_slice = false;
39
40 atomic64_set(&scx_nr_rejected, 0);
41
42 /*
43 * Keep CPUs stable during enable so that the BPF scheduler can track
44 * online CPUs by watching ->on/offline_cpu() after ->init().
45 */
46 cpus_read_lock();
47
48 scx_switch_all_req = false;
49 if (scx_ops.init) {
50 ret = scx_ops.init();
51
52 if (ret) {
53 ret = ops_sanitize_err("init", ret);
54 goto err_disable;
55 }
56
57 /*
58 * Exit early if ops.init() triggered scx_bpf_error(). Not
59 * strictly necessary as we'll fail transitioning into ENABLING
60 * later but that'd be after calling ops.prep_enable() on all
61 * tasks and with -EBUSY which isn't very intuitive. Let's exit
62 * early with success so that the condition is notified through
63 * ops.exit() like other scx_bpf_error() invocations.
64 */
65 if (atomic_read(&scx_exit_type) != SCX_EXIT_NONE)
66 goto err_disable;
67 }
68
69 WARN_ON_ONCE(dispatch_buf);
70 dispatch_max_batch = ops->dispatch_max_batch ?: SCX_DSP_DFL_MAX_BATCH;
71 dispatch_buf = __alloc_percpu(sizeof(dispatch_buf[0]) * dispatch_max_batch,
72 __alignof__(dispatch_buf[0]));
73 if (!dispatch_buf) {
74 ret = -ENOMEM;
75 goto err_disable;
76 }
77
78 task_runnable_timeout_ms = SCX_MAX_RUNNABLE_TIMEOUT;
79 if (ops->timeout_ms) {
80 /*
81 * Excessively large timeouts should have been rejected in
82 * bpf_scx_init_member().
83 */
84 WARN_ON_ONCE(ops->timeout_ms > SCX_MAX_RUNNABLE_TIMEOUT);
85 task_runnable_timeout_ms = ops->timeout_ms;
86 }
87
88 last_timeout_check = jiffies;
89 queue_delayed_work(system_unbound_wq, &check_timeout_work,
90 task_runnable_timeout_ms / 2);
91
92 /*
93 * Lock out forks, cgroup on/offlining and moves before opening the
94 * floodgate so that they don't wander into the operations prematurely.
95 */
96 percpu_down_write(&scx_fork_rwsem);
97 scx_cgroup_lock();
98
99 for (i = 0; i < SCX_NR_ONLINE_OPS; i++)
100 if (((void (**)(void))ops)[i])
101 static_branch_enable_cpuslocked(&scx_has_op[i]);
102
103 if (ops->flags & SCX_OPS_ENQ_LAST)
104 static_branch_enable_cpuslocked(&scx_ops_enq_last);
105
106 if (ops->flags & SCX_OPS_ENQ_EXITING)
107 static_branch_enable_cpuslocked(&scx_ops_enq_exiting);
108 if (scx_ops.cpu_acquire || scx_ops.cpu_release)
109 static_branch_enable_cpuslocked(&scx_ops_cpu_preempt);
110
111 if (!ops->update_idle || (ops->flags & SCX_OPS_KEEP_BUILTIN_IDLE)) {
112 reset_idle_masks();
113 static_branch_enable_cpuslocked(&scx_builtin_idle_enabled);
114 } else {
115 static_branch_disable_cpuslocked(&scx_builtin_idle_enabled);
116 }
117
118 /*
119 * All cgroups should be initialized before letting in tasks. cgroup
120 * on/offlining and task migrations are already locked out.
121 */
122 ret = scx_cgroup_init();
123 if (ret)
124 goto err_disable_unlock;
125
126 static_branch_enable_cpuslocked(&__scx_ops_enabled);
127
128 /*
129 * Enable ops for every task. Fork is excluded by scx_fork_rwsem
130 * preventing new tasks from being added. No need to exclude tasks
131 * leaving as sched_ext_free() can handle both prepped and enabled
132 * tasks. Prep all tasks first and then enable them with preemption
133 * disabled.
134 */
135 spin_lock_irq(&scx_tasks_lock);
136
137 scx_task_iter_init(&sti);
138 while ((p = scx_task_iter_next_filtered(&sti))) {
139 get_task_struct(p);
140 spin_unlock_irq(&scx_tasks_lock);
141
142 ret = scx_ops_prepare_task(p, task_group(p));
143 if (ret) {
144 put_task_struct(p);
145 spin_lock_irq(&scx_tasks_lock);
146 scx_task_iter_exit(&sti);
147 spin_unlock_irq(&scx_tasks_lock);
148 pr_err("sched_ext: ops.prep_enable() failed (%d) for %s[%d] while loading\n",
149 ret, p->comm, p->pid);
150 goto err_disable_unlock;
151 }
152
153 put_task_struct(p);
154 spin_lock_irq(&scx_tasks_lock);
155 }
156 scx_task_iter_exit(&sti);
157
158 /*
159 * All tasks are prepped but are still ops-disabled. Ensure that
160 * %current can't be scheduled out and switch everyone.
161 * preempt_disable() is necessary because we can't guarantee that
162 * %current won't be starved if scheduled out while switching.
163 */
164 preempt_disable();
165
166 /*
167 * From here on, the disable path must assume that tasks have ops
168 * enabled and need to be recovered.
169 */
170 if (!scx_ops_tryset_enable_state(SCX_OPS_ENABLING, SCX_OPS_PREPPING)) {
171 preempt_enable();
172 spin_unlock_irq(&scx_tasks_lock);
173 ret = -EBUSY;
174 goto err_disable_unlock;
175 }
176
177 /*
178 * We're fully committed and can't fail. The PREPPED -> ENABLED
179 * transitions here are synchronized against sched_ext_free() through
180 * scx_tasks_lock.
181 */
182 WRITE_ONCE(scx_switching_all, scx_switch_all_req);
183
184 scx_task_iter_init(&sti);
185 while ((p = scx_task_iter_next_filtered_locked(&sti))) {
186 if (READ_ONCE(p->__state) != TASK_DEAD) {
187 const struct sched_class *old_class = p->sched_class;
188 struct sched_enq_and_set_ctx ctx;
189
190 sched_deq_and_put_task(p, DEQUEUE_SAVE | DEQUEUE_MOVE,
191 &ctx);
192 scx_ops_enable_task(p);
193
194 __setscheduler_prio(p, p->prio);
195 check_class_changing(task_rq(p), p, old_class);
196
197 sched_enq_and_set_task(&ctx);
198
199 check_class_changed(task_rq(p), p, old_class, p->prio);
200 } else {
201 scx_ops_disable_task(p);
202 }
203 }
204 scx_task_iter_exit(&sti);
205
206 spin_unlock_irq(&scx_tasks_lock);
207 preempt_enable();
208 scx_cgroup_unlock();
209 percpu_up_write(&scx_fork_rwsem);
210
211 if (!scx_ops_tryset_enable_state(SCX_OPS_ENABLED, SCX_OPS_ENABLING)) {
212 ret = -EBUSY;
213 goto err_disable_unlock;
214 }
215
216 if (scx_switch_all_req)
217 static_branch_enable_cpuslocked(&__scx_switched_all);
218
219 cpus_read_unlock();
220 mutex_unlock(&scx_ops_enable_mutex);
221
222 scx_cgroup_config_knobs();
223
224 return 0;
225
226err_unlock:
227 mutex_unlock(&scx_ops_enable_mutex);
228 return ret;
229
230err_disable_unlock:
231 scx_cgroup_unlock();
232 percpu_up_write(&scx_fork_rwsem);
233err_disable:
234 cpus_read_unlock();
235 mutex_unlock(&scx_ops_enable_mutex);
236 /* must be fully disabled before returning */
237 scx_ops_disable(SCX_EXIT_ERROR);
238 kthread_flush_work(&scx_ops_disable_work);
239 return ret;
240}-
首先检查一下
scx_ops_helper, 这是一个struct kthread_worker类型的东西,kthread_worker是 Linux 内核中的一个机制, 用于实现内核线程的创建和管理. 它是一个轻量级的工作队列, 可以在内核中创建多个线程, 以异步方式执行一些需要长时间运行的任务, 而不会阻塞其他进程或线程.c1struct kthread_worker { 2 unsigned int flags; 3 raw_spinlock_t lock; 4 struct list_head work_list; 5 struct list_head delayed_work_list; 6 struct task_struct *task; 7 struct kthread_work *current_work; 8}; 9 10static struct kthread_worker *scx_ops_helper;如果这是空的话, 则调用
scx_create_rt_helper函数创建一个该类型的元素, 将对应的返回指针写进去.这个指针还在
sysrq_handle_sched_ext_reset以及schedule_scx_ops_disable_work中出现过. -
随后通过
static enum scx_ops_enable_state scx_ops_enable_state读目前的运行状态, 该枚举变量被初始化为SCX_OPS_DISABLED, 如果不是被禁用的状态则继续推进. -
初始化哈希表, 绑定
scx_ops结构, 该元素定义为:c1static struct sched_ext_ops scx_ops; -
初始化一些字段以及统计值.
-
随后调用用户自定义的
init函数函数, 判断一些返回值, 并进行可能的错误处理. -
初始化
dispatch_buf的CPU空间, 如果用户规定了大小则使用不然则使用缺省的最大大小. -
初始化
task_runnable_timeout_msc1/* 2 * The maximum amount of time that a task may be runnable without being 3 * scheduled on a CPU. If this timeout is exceeded, it will trigger 4 * scx_ops_error(). 5 */ 6unsigned long task_runnable_timeout_ms; -
初始化
last_timeout_check, 貌似是用于解决一些irq的问题c1/* 2 * The last time the delayed work was run. This delayed work relies on 3 * ksoftirqd being able to run to service timer interrupts, so it's possible 4 * that this work itself could get wedged. To account for this, we check that 5 * it's not stalled in the timer tick, and trigger an error if it is. 6 */ 7unsigned long last_timeout_check = INITIAL_JIFFIES; -
使用
percpu_down_write操作每CPU信号量, 该信号量是一个每CPU的读写锁, 该函数的作用是获取一个该信号量的写锁. 下面这种语法不知道是定义在哪里的, 但是根据对注释的分析我认为这种语法(以下面的为例)就是为fork系统调用加了个读写锁?c1DEFINE_STATIC_PERCPU_RWSEM(scx_fork_rwsem);通过获取这个写锁, 就不会有新的进程被创建, 后续的prepare等阶段就可以顺利进行
-
scx_cgroup_lock用于保护进程控制组(cgroup), 具体cgroup是什么东西还没研究.. -
遍历所有可能的函数指针位置, 并且更新
scx_has_op的内容, 这是一个数组, 其类型如下所示:c1struct static_key_false scx_has_op[SCX_NR_ONLINE_OPS] = 2 { [0 ... SCX_NR_ONLINE_OPS-1] = STATIC_KEY_FALSE_INIT };有关该数组的类型, 其实涉及到内核同步的相关知识.
static_branch_enable是一个宏, 它用于在编译时确定是否启用静态分支. 静态分支是一种在运行时根据条件跳转到不同代码路径的技术. 启用静态分支可以提高代码执行效率, 因为它可以避免在运行时进行条件判断, 而带上lock则意味着要还要锁定该CPU. -
随后根据flags标志位再额外启用/禁用一些函数指针.
-
启用
__scx_ops_enabled? 这个变量也是一个DEFINE_STATIC_KEY_FALSE定义的变量, 其在scx_ops_disable_workfn被disable, 具体的原因暂时不考. -
scx_tasks_lock是一个自旋锁, 用于保护scx_tasks队列的操作, 该队列在scx_task_iter_*系列函数中被使用. 据注释所说, 这是由于在退出阶段的任务可能会在失去自己PID的情况下被调度(?), 所以当禁用bpf调度器时应该保证所有状态下的进程均被正常退出, 所以用一个task list链起来.c1/* 2 * During exit, a task may schedule after losing its PIDs. When disabling the 3 * BPF scheduler, we need to be able to iterate tasks in every state to 4 * guarantee system safety. Maintain a dedicated task list which contains every 5 * task between its fork and eventual free. 6 */ 7static DEFINE_SPINLOCK(scx_tasks_lock); 8static LIST_HEAD(scx_tasks); -
scx_task_iter_init初始化一个迭代器sti, 随后不断调用scx_task_iter_next_filtered获取下一个非空闲的任务描述符p. 对于每一个任务描述符来说:-
调用
get_task_struct, 其实好像只是做个了引用计时器+1, 具体的原因不明, 可能是为了防止别人把他删掉吧c1static inline struct task_struct *get_task_struct(struct task_struct *t) 2{ 3 refcount_inc(&t->usage); 4 return t; 5} -
由于已经取到了任务描述符, 释放
&scx_tasks_lock锁 -
调用
scx_ops_prepare_task初始化任务的一些状态标志, 如果装载用户自定义的函数后失败了, 则:-
put_task_struct, 与get_task_struct对应, 引用计数-1 -
加锁后调用
scx_task_iter_exit, 销毁该任务迭代器, jump到错误处理代码中进一步收尾
-
-
不然, 同样执行
put_task_struct, 感觉这本质上不会就是个锁吧..?? -
所有任务迭代完成后销毁当前迭代器
-
-
在prepare阶段, 所有的相关进程都已经准备就绪, 但是还未开启
enable, 所以当前的进程不会被调度出去. 同时由于fork写锁已被获取, 因而保证不会有新的进程加入进来. 不过scx机制允许进程离开, 这是因为sched_ext_free既可以处理prepped又可以处理enable状态的任务. (感觉对于fork读写锁的认识又不到位了…? 他到底是锁了什么操作 Todo) -
prepare完成后, 禁用抢占, 防止当前进程由于调度的原因被饿死
-
调用
scx_ops_tryset_enable_state将所有的就绪状态转换为启用状态, 因为随后全部假设任务的功能函数已经启用并且需要recover? Todo: 啥是Recover -
使用
WRITE_ONCE将scx_switch_all_req的布尔值写入到scx_switching_all中. -
初始化一个迭代器, 使用
scx_task_iter_next_filtered_locked获取下一个非空闲的任务描述符p, 同时将其所处的运行队列上锁后再开始遍历任务描述符:-
如果该任务是DEAD状态的任务, 则直接调用
scx_ops_disable_task禁用所有的任务即可 -
不然, 调用
sched_deq_and_put_task: 初始化sched_enq_and_set_ctx实体内容, 并根据需求间接执行调度类接口的dequeue_task以及put_prev_task函数 -
使用
scx_ops_enable_task启用task功能 -
使用
__setscheduler_prio修改进程的调度策略 -
使用
check_class_changing检查是否发生了调度策略的变化, 如果变化了, 则还要使用调度类暴露的接口函数switching_to -
当上述对于进程的操作完成后, 使用
sched_enq_and_set_task再把该进程塞回去.- 事实上. 由于sched_deq_and_put_task 函数将任务从原先的队列中取出, 并且该函数是在任务锁定的情况下执行的, 因此在这段时间内任务不会被调度. 接下来, sched_enq_and_set_task 函数将任务放入新的队列中, 由于这些操作都是在任务未被调度的情况下完成的, 因此只有当这些操作全部完成后, 才能够使任务重新进入调度器并重新开始调度. 用这种方式能够确保任务能够正确地被取出和重新插入到队列中, 并且能够避免并发操作引起的冲突和错误.
-
执行
check_class_changed(为什么要这一对函数?), 进一步处理一些切换工作
-
-
本轮迭代完成后, 该函数的大部分工作均完成, 将一些锁释放后即可
scx_create_rt_helper
1static struct kthread_worker *scx_create_rt_helper(const char *name)
2{
3 struct kthread_worker *helper;
4
5 helper = kthread_create_worker(0, name);
6 if (helper)
7 sched_set_fifo(helper->task);
8 return helper;
9}sysrq_handle_sched_ext_reset
1static void sysrq_handle_sched_ext_reset(int key)
2{
3 if (scx_ops_helper)
4 scx_ops_disable(SCX_EXIT_SYSRQ);
5 else
6 pr_info("sched_ext: BPF scheduler not yet used\n");
7}Todo.
schedule_scx_ops_disable_work
1static void schedule_scx_ops_disable_work(void)
2{
3 struct kthread_worker *helper = READ_ONCE(scx_ops_helper);
4
5 /*
6 * We may be called spuriously before the first bpf_sched_ext_reg(). If
7 * scx_ops_helper isn't set up yet, there's nothing to do.
8 */
9 if (helper)
10 kthread_queue_work(helper, &scx_ops_disable_work);
11}Todo.
[help]scx_task_iter_*
这里介绍一族函数, 主要用于Todo
1struct scx_task_iter {
2 struct sched_ext_entity cursor;
3 struct task_struct *locked;
4 struct rq *rq;
5 struct rq_flags rf;
6}; 1/**
2 * scx_task_iter_init - Initialize a task iterator
3 * @iter: iterator to init
4 *
5 * Initialize @iter. Must be called with scx_tasks_lock held. Once initialized,
6 * @iter must eventually be exited with scx_task_iter_exit().
7 *
8 * scx_tasks_lock may be released between this and the first next() call or
9 * between any two next() calls. If scx_tasks_lock is released between two
10 * next() calls, the caller is responsible for ensuring that the task being
11 * iterated remains accessible either through RCU read lock or obtaining a
12 * reference count.
13 *
14 * All tasks which existed when the iteration started are guaranteed to be
15 * visited as long as they still exist.
16 */
17static void scx_task_iter_init(struct scx_task_iter *iter)
18{
19 lockdep_assert_held(&scx_tasks_lock);
20
21 iter->cursor = (struct sched_ext_entity){ .flags = SCX_TASK_CURSOR };
22 list_add(&iter->cursor.tasks_node, &scx_tasks);
23 iter->locked = NULL;
24}初始化函数:
-
调用时必须持有指定的锁, 可以通过
lockdep机制检查 -
cursor指向一个sched_ext_entity类型的元素, 其flags字段为SCX_TASK_CURSOR, 根据注释可知这表示其是一个遍历指针, 而不是一个任务. -
添加链表元素, 链头是
ext.c定义的一个元素scx_tasks, 不确定这个链头是个什么类型的元素? 是per-cpu还是啥别的, 其至少应该是一个static的变量.. 但是和per-cpu的关系我确实不太确定.. Todo -
把
locked指针置空
1/**
2 * scx_task_iter_exit - Exit a task iterator
3 * @iter: iterator to exit
4 *
5 * Exit a previously initialized @iter. Must be called with scx_tasks_lock held.
6 * If the iterator holds a task's rq lock, that rq lock is released. See
7 * scx_task_iter_init() for details.
8 */
9static void scx_task_iter_exit(struct scx_task_iter *iter)
10{
11 struct list_head *cursor = &iter->cursor.tasks_node;
12
13 lockdep_assert_held(&scx_tasks_lock);
14
15 if (iter->locked) {
16 task_rq_unlock(iter->rq, iter->locked, &iter->rf);
17 iter->locked = NULL;
18 }
19
20 if (list_empty(cursor))
21 return;
22
23 list_del_init(cursor);
24}退出(/销毁?)一个之前初始化过的迭代器(就这么叫吧!):
-
确保持有锁
-
如果持有运行队列的锁也需要释放一下, 并将locked置空, 可能是为了防止后续有人继续使用iter访问到该任务造成破坏.
-
判断链表是否空, 如果不空则调用
list_del_init, 具体有关双向链表什么初始化的不管了, 有点忘记了c1/** 2 * list_del_init - deletes entry from list and reinitialize it. 3 * @entry: the element to delete from the list. 4 */ 5static inline void list_del_init(struct list_head *entry)
1/**
2 * scx_task_iter_next - Next task
3 * @iter: iterator to walk
4 *
5 * Visit the next task. See scx_task_iter_init() for details.
6 */
7static struct task_struct *scx_task_iter_next(struct scx_task_iter *iter)
8{
9 struct list_head *cursor = &iter->cursor.tasks_node;
10 struct sched_ext_entity *pos;
11
12 lockdep_assert_held(&scx_tasks_lock);
13
14 list_for_each_entry(pos, cursor, tasks_node) {
15 if (&pos->tasks_node == &scx_tasks)
16 return NULL;
17 if (!(pos->flags & SCX_TASK_CURSOR)) {
18 list_move(cursor, &pos->tasks_node);
19 return container_of(pos, struct task_struct, scx);
20 }
21 }
22
23 /* can't happen, should always terminate at scx_tasks above */
24 BUG();
25}遍历task链表:
-
确保持有锁
-
调用
list_for_each_entry, pos是暴露出来的遍历指针, cursor是链表头, tasks_node是链表中list_head字段的名字.-
如果pos访问到了
scx_tasks了, 说明遍历到头了, 返回空 -
不然, 往后找第一个不是CURSOR标志的task, 执行list_move, 将
cursor放到&pos->tasks_node后面(不太确定) Why? Todo -
返回对应的
task_struct结构
-
-
按道理一定会终止, 所以大胆加上BUG()
1/**
2 * scx_task_iter_next_filtered - Next non-idle task
3 * @iter: iterator to walk
4 *
5 * Visit the next non-idle task. See scx_task_iter_init() for details.
6 */
7static struct task_struct *
8scx_task_iter_next_filtered(struct scx_task_iter *iter)
9{
10 struct task_struct *p;
11
12 while ((p = scx_task_iter_next(iter))) {
13 if (!is_idle_task(p))
14 return p;
15 }
16 return NULL;
17}返回后面的第一个非空闲的任务, 封装了一层scx_task_iter_next即可.
1/**
2 * scx_task_iter_next_filtered_locked - Next non-idle task with its rq locked
3 * @iter: iterator to walk
4 *
5 * Visit the next non-idle task with its rq lock held. See scx_task_iter_init()
6 * for details.
7 */
8static struct task_struct *
9scx_task_iter_next_filtered_locked(struct scx_task_iter *iter)
10{
11 struct task_struct *p;
12
13 if (iter->locked) {
14 task_rq_unlock(iter->rq, iter->locked, &iter->rf);
15 iter->locked = NULL;
16 }
17
18 p = scx_task_iter_next_filtered(iter);
19 if (!p)
20 return NULL;
21
22 iter->rq = task_rq_lock(p, &iter->rf);
23 iter->locked = p;
24 return p;
25}返回后面的第一个非空闲的任务, 不过要把其运行队列上锁后再返回, 进一步封装scx_task_iter_next_filtered
[help]scx_ops_*_task
这里有3个函数, 用于控制任务的启用、禁用与初始化等工作.
1static int scx_ops_prepare_task(struct task_struct *p, struct task_group *tg)
2{
3 int ret;
4
5 WARN_ON_ONCE(p->scx.flags & SCX_TASK_OPS_PREPPED);
6
7 p->scx.disallow = false;
8
9 if (SCX_HAS_OP(prep_enable)) {
10 struct scx_enable_args args = { .cgroup = tg_cgrp(tg) };
11
12 ret = scx_ops.prep_enable(p, &args);
13 if (unlikely(ret)) {
14 ret = ops_sanitize_err("prep_enable", ret);
15 return ret;
16 }
17 }
18
19 if (p->scx.disallow) {
20 struct rq *rq;
21 struct rq_flags rf;
22
23 rq = task_rq_lock(p, &rf);
24
25 /*
26 * We're either in fork or load path and @p->policy will be
27 * applied right after. Reverting @p->policy here and rejecting
28 * %SCHED_EXT transitions from scx_check_setscheduler()
29 * guarantees that if ops.prep_enable() sets @p->disallow, @p
30 * can never be in SCX.
31 */
32 if (p->policy == SCHED_EXT) {
33 p->policy = SCHED_NORMAL;
34 atomic64_inc(&scx_nr_rejected);
35 }
36
37 task_rq_unlock(rq, p, &rf);
38 }
39
40 p->scx.flags |= (SCX_TASK_OPS_PREPPED | SCX_TASK_WATCHDOG_RESET);
41 return 0;
42}-
设置
disallow字段为false, 允许该任务参与scx调度系统中 -
检查
sched_ext_ops是否有自定义的prep_enable函数, 有的话则调用之, 判断一下返回值, 并且认为失败是小概率事件 -
如果在
prep_enable中启用了disallow标志, 则不允许其参与scx调度系统, 加锁rq, 将policy设置为NORMAL, 同时更新一些统计量 -
更新
p->scx的flags, 表示程序已经准备好被bpf调度器enable了, 同时指明watchdog couter应该被重置. Todo: 啥是watchdog, 在哪里用, 有啥用
1static void scx_ops_enable_task(struct task_struct *p)
2{
3 lockdep_assert_rq_held(task_rq(p));
4 WARN_ON_ONCE(!(p->scx.flags & SCX_TASK_OPS_PREPPED));
5
6 if (SCX_HAS_OP(enable)) {
7 struct scx_enable_args args =
8 { .cgroup = tg_cgrp(p->sched_task_group) };
9 scx_ops.enable(p, &args);
10 }
11 p->scx.flags &= ~SCX_TASK_OPS_PREPPED;
12 p->scx.flags |= SCX_TASK_OPS_ENABLED;
13}-
使用lockdep验证对锁的持有, 同时检查是否已经prepare好了
-
如果有自定义的
enable则执行. -
设置标志, 清
SCX_TASK_OPS_PREPPED标志, 设置SCX_TASK_OPS_ENABLED表示已经enabled了
1static void scx_ops_disable_task(struct task_struct *p)
2{
3 lockdep_assert_rq_held(task_rq(p));
4
5 if (p->scx.flags & SCX_TASK_OPS_PREPPED) {
6 if (SCX_HAS_OP(cancel_enable)) {
7 struct scx_enable_args args =
8 { .cgroup = tg_cgrp(task_group(p)) };
9 scx_ops.cancel_enable(p, &args);
10 }
11 p->scx.flags &= ~SCX_TASK_OPS_PREPPED;
12 } else if (p->scx.flags & SCX_TASK_OPS_ENABLED) {
13 if (SCX_HAS_OP(disable))
14 scx_ops.disable(p);
15 p->scx.flags &= ~SCX_TASK_OPS_ENABLED;
16 }
17}-
使用lockdep验证对锁的持有
-
查看任务是只prepare过了还是已经enable了, 分别处理:
-
如果只prepare了, 调用对应的关闭函数为
cancel_enable -
如果enable了, 调用对应的禁止函数
disable
-
[help]sched_deq_and_put_task
再说明一组用于Todo的函数, 其位于kernel/sched/core.c中, 由CONFIG_SCHED_CLASS_EXT控制条件编译.
1#ifdef CONFIG_SCHED_CLASS_EXT
2void sched_deq_and_put_task(struct task_struct *p, int queue_flags,
3 struct sched_enq_and_set_ctx *ctx)
4{
5 struct rq *rq = task_rq(p);
6
7 lockdep_assert_rq_held(rq);
8
9 *ctx = (struct sched_enq_and_set_ctx){
10 .p = p,
11 .queue_flags = queue_flags | DEQUEUE_NOCLOCK,
12 .queued = task_on_rq_queued(p),
13 .running = task_current(rq, p),
14 };
15
16 update_rq_clock(rq);
17 if (ctx->queued)
18 dequeue_task(rq, p, queue_flags);
19 if (ctx->running)
20 put_prev_task(rq, p);
21}在sched_deq_and_put_task中:
-
获取任务描述符的运行队列, 使用lockdep机制进行锁的检查, 将ctx指针的4个字段全部填充
-
queue_flags中或上DEQUEUE_NOCLOCK标志, 其用于指示在没有锁定同步机制的情况下执行dequeue操作. 其在不需要同步保证的情况下允许进行快速操作, 但必须确保并发线程安全性. -
.queued是一个布尔结果, 该函数返回值表示给定的进程在运行队列中是否处于已排队状态(即TASK_ON_RQ_QUEUED). 如果返回值为 true, 则意味着该任务已经在运行队列中, 否则意味着该任务未被添加到运行队列中.c1static inline int task_on_rq_queued(struct task_struct *p) 2{ 3 return p->on_rq == TASK_ON_RQ_QUEUED; 4} -
.running也是一个布尔结果:c1static inline int task_current(struct rq *rq, struct task_struct *p) 2{ 3 return rq->curr == p; 4} -
update_rq_clock是 Linux 操作系统中的一个函数, 它被用来更新系统运行队列的时钟. -
dequeue_task和put_prev_task都是static的函数, 本质是一些调度类接口函数的封装
-
dequeue_task
1static inline void dequeue_task(struct rq *rq, struct task_struct *p, int flags)
2{
3 if (sched_core_enabled(rq))
4 sched_core_dequeue(rq, p, flags);
5
6 if (!(flags & DEQUEUE_NOCLOCK))
7 update_rq_clock(rq);
8
9 if (!(flags & DEQUEUE_SAVE)) {
10 sched_info_dequeue(rq, p);
11 psi_dequeue(p, flags & DEQUEUE_SLEEP);
12 }
13
14 uclamp_rq_dec(rq, p);
15 p->sched_class->dequeue_task(rq, p, flags);
16}-
根据一些标志执行一些函数
-
随后执行调度类中的
dequeue_task函数, 实际上就是对这些调度类提供的接口函数做了一层封装而已
put_prev_task
1static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
2{
3 WARN_ON_ONCE(rq->curr != prev);
4 prev->sched_class->put_prev_task(rq, prev);
5}类似的, 做了一些封装, 用于将进程加入到执行队列中
[help]sched_enq_and_set_task
1void sched_enq_and_set_task(struct sched_enq_and_set_ctx *ctx)
2{
3 struct rq *rq = task_rq(ctx->p);
4
5 lockdep_assert_rq_held(rq);
6
7 if (ctx->queued)
8 enqueue_task(rq, ctx->p, ctx->queue_flags);
9 if (ctx->running)
10 set_next_task(rq, ctx->p);
11}sched_class
1struct sched_class {
2
3#ifdef CONFIG_UCLAMP_TASK
4 int uclamp_enabled;
5#endif
6
7 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
8 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
9 void (*yield_task) (struct rq *rq);
10 bool (*yield_to_task)(struct rq *rq, struct task_struct *p);
11
12 void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
13
14 struct task_struct *(*pick_next_task)(struct rq *rq);
15
16 void (*put_prev_task)(struct rq *rq, struct task_struct *p);
17 void (*set_next_task)(struct rq *rq, struct task_struct *p, bool first);
18
19#ifdef CONFIG_SMP
20 int (*balance)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
21 int (*select_task_rq)(struct task_struct *p, int task_cpu, int flags);
22
23 struct task_struct * (*pick_task)(struct rq *rq);
24
25 void (*migrate_task_rq)(struct task_struct *p, int new_cpu);
26
27 void (*task_woken)(struct rq *this_rq, struct task_struct *task);
28
29 void (*set_cpus_allowed)(struct task_struct *p,
30 const struct cpumask *newmask,
31 u32 flags);
32
33 void (*rq_online)(struct rq *rq, enum rq_onoff_reason reason);
34 void (*rq_offline)(struct rq *rq, enum rq_onoff_reason reason);
35
36 struct rq *(*find_lock_rq)(struct task_struct *p, struct rq *rq);
37#endif
38
39 void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
40 void (*task_fork)(struct task_struct *p);
41 void (*task_dead)(struct task_struct *p);
42
43 /*
44 * The switched_from() call is allowed to drop rq->lock, therefore we
45 * cannot assume the switched_from/switched_to pair is serialized by
46 * rq->lock. They are however serialized by p->pi_lock.
47 */
48 void (*switching_to) (struct rq *this_rq, struct task_struct *task);
49 void (*switched_from)(struct rq *this_rq, struct task_struct *task);
50 void (*switched_to) (struct rq *this_rq, struct task_struct *task);
51 void (*reweight_task)(struct rq *this_rq, struct task_struct *task,
52 int newprio);
53 void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
54 int oldprio);
55
56 unsigned int (*get_rr_interval)(struct rq *rq,
57 struct task_struct *task);
58
59 void (*update_curr)(struct rq *rq);
60
61#ifdef CONFIG_FAIR_GROUP_SCHED
62 void (*task_change_group)(struct task_struct *p);
63#endif
64};__setscheduler_prio
1void __setscheduler_prio(struct task_struct *p, int prio)
2{
3 if (dl_prio(prio))
4 p->sched_class = &dl_sched_class;
5 else if (rt_prio(prio))
6 p->sched_class = &rt_sched_class;
7#ifdef CONFIG_SCHED_CLASS_EXT
8 else if (task_on_scx(p))
9 p->sched_class = &ext_sched_class;
10#endif
11 else
12 p->sched_class = &fair_sched_class;
13
14 p->prio = prio;
15}内核中, prio越小, 优先级越高; 其通过prio的大小优先选择截止期限调度策略(<0)或实时调度策略(<100), 随后再根据是否使用了scx决定是否是使用scx还是cfs.
check_class_change
1/*
2 * ->switching_to() is called with the pi_lock and rq_lock held and must not
3 * mess with locking.
4 */
5void check_class_changing(struct rq *rq, struct task_struct *p,
6 const struct sched_class *prev_class)
7{
8 if (prev_class != p->sched_class && p->sched_class->switching_to)
9 p->sched_class->switching_to(rq, p);
10}
11
12/*
13 * switched_from, switched_to and prio_changed must _NOT_ drop rq->lock,
14 * use the balance_callback list if you want balancing.
15 *
16 * this means any call to check_class_changed() must be followed by a call to
17 * balance_callback().
18 */
19void check_class_changed(struct rq *rq, struct task_struct *p,
20 const struct sched_class *prev_class,
21 int oldprio)
22{
23 if (prev_class != p->sched_class) {
24 if (prev_class->switched_from)
25 prev_class->switched_from(rq, p);
26
27 p->sched_class->switched_to(rq, p);
28 } else if (oldprio != p->prio || dl_task(p))
29 p->sched_class->prio_changed(rq, p, oldprio);
30}这两个内核函数都涉及到调度器(scheduler)中不同任务(task)的调度策略和切换过程。
check_class_changing()函数用于检查一个进程(p)是否需要根据其新的调度类别(sched_class)进行切换, 如果需要, 就会调用新的调度类别的switching_to()函数来执行切换操作
check_class_changed()函数则用于在进程切换或优先级改变时检查其调度类别是否发生了变化. 当进程从一个调度类别切换到另一个类别时, 该函数会首先调用原调度类别的switched_from()函数来完成任务的清理工作, 然后再调用新的调度类别的switched_to()函数来完成切换操作. 同时, 如果进程的优先级(prio)发生了改变, 则会调用当前调度类别的prio_changed()函数来更新其调度相关参数.
不过其实并不太清楚这两个函数具体的区别以及实际的应用场景..
数据结构关系图
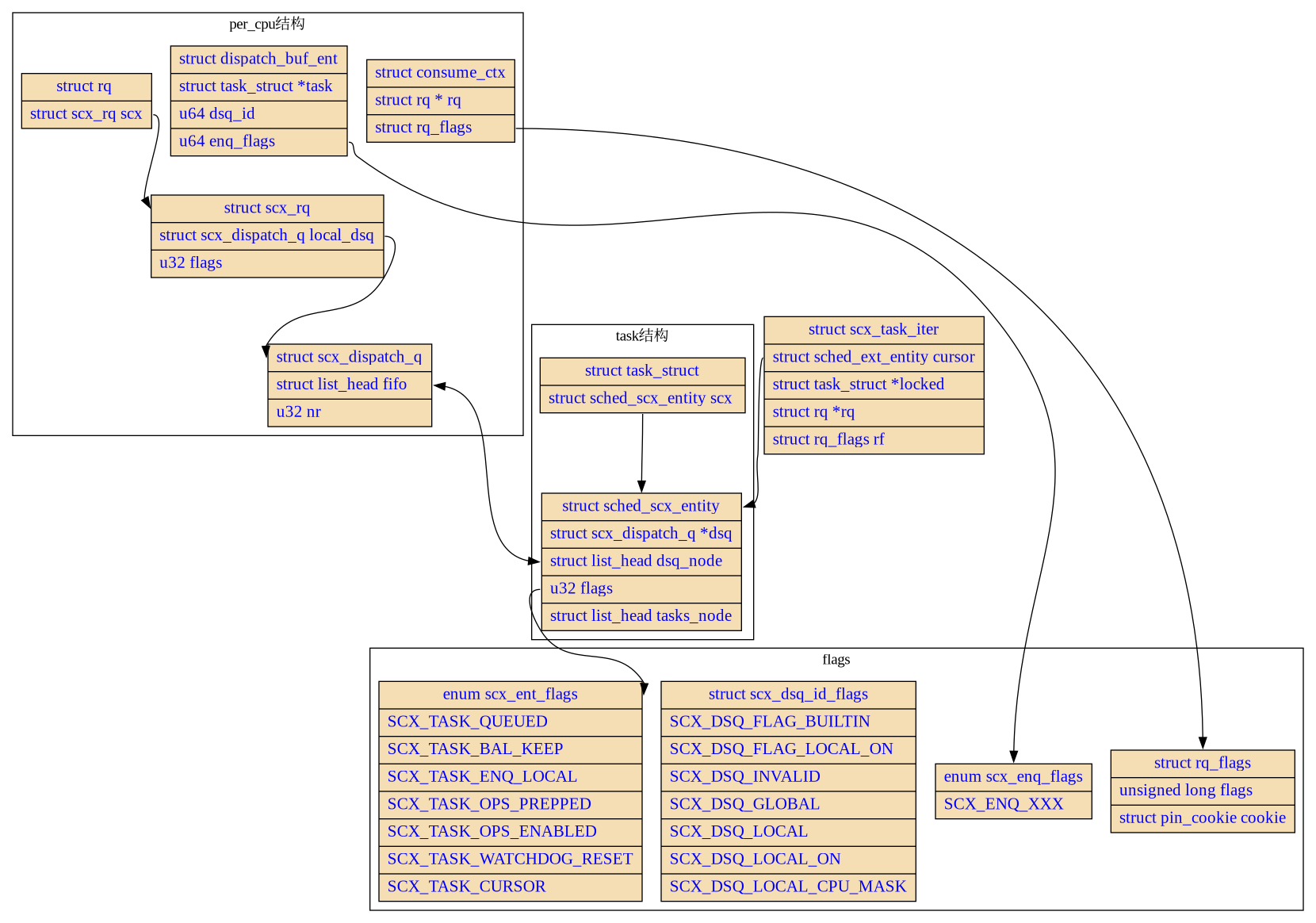
相关的源文件在 sched.dot
eBPF调度器实例
下面就结合代码看一下具体是怎么操作的.
tools/sched_ext/scx_common.bpf.h
1#define BPF_STRUCT_OPS(name, args...) \
2SEC("struct_ops/"#name) \
3BPF_PROG(name, ##args)scx_example_dummy.bpf.c
1/*
2 * A minimal dummy scheduler.
3 *
4 * In terms of scheduling, this behaves the same as not specifying any ops at
5 * all - a global FIFO. The only things it adds are the following niceties:
6 *
7 * - Statistics tracking how many are queued to local and global dsq's.
8 * - Termination notification for userspace.
9 * - Support for switch_all.
10 */1struct {
2 __uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
3 __uint(key_size, sizeof(u32));
4 __uint(value_size, sizeof(u64));
5 __uint(max_entries, 2); /* [local, global] */
6} stats SEC(".maps");这段代码定义了一个 BPF_MAP_TYPE_PERCPU_ARRAY 类型的 map,用于存储一组 key-value 对:
-
key 的大小为 sizeof(u32)
-
value 的大小为 sizeof(u64)
-
最大 entry 数量为 2, 分别为 local 和 global
-
该 map 被定义为 SEC(".maps"),用于在 eBPF 程序中引用该 map。
1static void stat_inc(u32 idx)
2{
3 u64 *cnt_p = bpf_map_lookup_elem(&stats, &idx);
4 if (cnt_p)
5 (*cnt_p)++;
6}
7
8s32 BPF_STRUCT_OPS(dummy_init)
9{
10 if (switch_all)
11 scx_bpf_switch_all();
12 return 0;
13}
14
15void BPF_STRUCT_OPS(dummy_enqueue, struct task_struct *p, u64 enq_flags)
16{
17 if (enq_flags & SCX_ENQ_LOCAL) {
18 stat_inc(0);
19 scx_bpf_dispatch(p, SCX_DSQ_LOCAL, SCX_SLICE_DFL, enq_flags);
20 } else {
21 stat_inc(1);
22 scx_bpf_dispatch(p, SCX_DSQ_GLOBAL, SCX_SLICE_DFL, enq_flags);
23 }
24}
25
26void BPF_STRUCT_OPS(dummy_exit, struct scx_exit_info *ei)
27{
28 uei_record(&uei, ei);
29}
30
31SEC(".struct_ops")
32struct sched_ext_ops dummy_ops = {
33 .enqueue = (void *)dummy_enqueue,
34 .init = (void *)dummy_init,
35 .exit = (void *)dummy_exit,
36 .name = "dummy",
37};这段代码是一个 eBPF 程序,其中定义了三个函数:stat_inc、dummy_init 和 dummy_enqueue,以及一个结构体 dummy_ops。
stat_inc 函数用于对 stats map 中指定下标的值进行自增操作。
dummy_init 函数是一个初始化函数,在 switch_all 标志位为真时会调用 scx_bpf_switch_all 函数。
dummy_enqueue 函数是一个任务调度函数,用于将任务放入本地队列或全局队列,并调用 stat_inc 函数对 stats map 进行计数操作。
dummy_exit 函数用于处理任务退出信息,其中 uei_record 函数是一个用户自定义函数,用于记录任务退出信息。
dummy_ops 结构体中包含了三个函数指针和一个字符串,分别对应任务调度、初始化和退出操作,以及该结构体的名称。这个结构体在 SEC(".struct_ops") 中定义,可能是用于在 eBPF 程序中引用这些操作函数。
scx_example_central.bpf.c
调度策略简介:
-
由一个CPU来决定所有的调度策略, 当其余的CPU完成所有任务后必须通知中心CPU来分发任务. 在该策略下, 有一个全局的BPF队列, 中心CPU通过
dispatch()分发全局队列的任务都每个CPU的局部dsq. -
无时钟操作: 所有任务都使用无限切片进行分派, 这允许使用适当的nohz_full参数停止运行在CONFIG_NO_HZ_FULL内核上的时钟. 无时钟操作可以通过/proc/interrupts观察到. 周期性的切换则由一个周期性的时钟来来完成, 不过BPF timer目前无法指定某一个CPU来做这件事情, 因而目前无法指定该任务由中心CPU完成.
b. Tickless operation
All tasks are dispatched with the infinite slice which allows stopping the ticks on CONFIG_NO_HZ_FULL kernels running with the proper nohz_full parameter. The tickless operation can be observed through /proc/interrupts.
Periodic switching is enforced by a periodic timer checking all CPUs and preempting them as necessary. Unfortunately, BPF timer currently doesn’t have a way to pin to a specific CPU, so the periodic timer isn’t pinned to the central CPU.
什么是一个tickless kernel?
<operating system - what is a tickless OS? - Stack Overflow>
A ’tick’ in OS terms is an interval after which the OS will wake up to process any pending events.
So, if you have a 100Hz tick, then 100 times a second, the OS will wake up, check to see whether any timers have expired, execute their actions if there are, then go to sleep again. On a tick-less system, rather than waking up 100 times a second to see if anything is ready to process, the OS will look at when the next timer is due to expire and then sleep until that time.
Note that when the CPU is active, it’s obviously not going to go into any kind of sleep mode, and the kernel will set up an interrupt for scheduling purposes. It’s only tickless (as the comment points out) when there’s nothing running on the CPU or (in very modern Linux kernels) when only one process is running.
Linux can run with or without ticks, with a compile-time switch. I don’t know about any other systems.
- Preemption: 内核进程Kthreads总是无条件地被排到指定本地dsq的头部, 这保证了内核进程总是比用户进程拥有更高的优先级. 比如, 如果周期性时钟运行在ksoftirqd上, 并且由于用户进程的运行使其发生了饥饿, 那么就再也没有其他的内核进程可以来将这个用户进程腾出去CPU了.
c. Preemption
Kthreads are unconditionally queued to the head of a matching local dsq and dispatched with SCX_DSQ_PREEMPT. This ensures that a kthread is always prioritized over user threads, which is required for ensuring forward progress as e.g. the periodic timer may run on a ksoftirqd and if the ksoftirqd gets starved by a user thread, there may not be anything else to vacate that user thread.
SCX_KICK_PREEMPT is used to trigger scheduling and CPUs to move to the next tasks.
下面看一下具体的几个功能实现, 此处需要结合内核提供的接口一起看, 之前已经列出了所有的函数接口, 这里就只看一下调度策略实现的内容:
central_select_cpu
1s32 BPF_STRUCT_OPS(central_select_cpu, struct task_struct *p,
2 s32 prev_cpu, u64 wake_flags)
3{
4 /*
5 * Steer wakeups to the central CPU as much as possible to avoid
6 * disturbing other CPUs. It's safe to blindly return the central cpu as
7 * select_cpu() is a hint and if @p can't be on it, the kernel will
8 * automatically pick a fallback CPU.
9 */
10 return central_cpu;
11}- 选择中心服务器, 该选择可能并非是最终运行的CPU; 当该CPU不可用时内核也会自动进行fallback.
central_enqueue
1void BPF_STRUCT_OPS(central_enqueue, struct task_struct *p, u64 enq_flags)
2{
3 s32 pid = p->pid;
4
5 __sync_fetch_and_add(&nr_total, 1);
6
7 /*
8 * Push per-cpu kthreads at the head of local dsq's and preempt the
9 * corresponding CPU. This ensures that e.g. ksoftirqd isn't blocked
10 * behind other threads which is necessary for forward progress
11 * guarantee as we depend on the BPF timer which may run from ksoftirqd.
12 */
13 if ((p->flags & PF_KTHREAD) && p->nr_cpus_allowed == 1) {
14 __sync_fetch_and_add(&nr_locals, 1);
15 scx_bpf_dispatch(p, SCX_DSQ_LOCAL, SCX_SLICE_INF,
16 enq_flags | SCX_ENQ_PREEMPT);
17 return;
18 }
19
20 if (bpf_map_push_elem(¢ral_q, &pid, 0)) {
21 __sync_fetch_and_add(&nr_overflows, 1);
22 scx_bpf_dispatch(p, FALLBACK_DSQ_ID, SCX_SLICE_INF, enq_flags);
23 return;
24 }
25
26 __sync_fetch_and_add(&nr_queued, 1);
27
28 if (!scx_bpf_task_running(p))
29 scx_bpf_kick_cpu(central_cpu, SCX_KICK_PREEMPT);
30}按照sched_ext_ops注释所说, sched_ext_ops.enqueue 应当是将一个任务送入BPF调度器中, 随后再通过dispatch的方式从BPF调度器中取任务分发到dsq中. 但是在central调度策略中可以看到, enqueue直接将进行了分发! Todo: 应该是这样吧
下面看一下dispatch方法又实现了什么呢?
central_dispatch
1void BPF_STRUCT_OPS(central_dispatch, s32 cpu, struct task_struct *prev)
2{
3 /* if out of tasks to run, gimme more */
4 if (!scx_bpf_dsq_nr_queued(FALLBACK_DSQ_ID)) {
5 bool *gimme = MEMBER_VPTR(cpu_gimme_task, [cpu]);
6 if (gimme)
7 *gimme = true;
8 }
9
10 if (cpu == central_cpu) {
11 /* we're the scheduling CPU, dispatch for every CPU */
12 __sync_fetch_and_add(&nr_dispatches, 1);
13 bpf_loop(nr_cpu_ids, dispatch_to_one_cpu_loopfn, NULL, 0);
14 } else {
15 /*
16 * Force dispatch on the scheduling CPU so that it finds a task
17 * to run for us.
18 */
19 scx_bpf_kick_cpu(central_cpu, SCX_KICK_PREEMPT);
20 }
21}该函数实现了 Todo… :
-
首先通过
scx_bpf_dsq_nr_queued读取FALLBACK_DSQ_ID作为dsq_id的任务数量, 该枚举常量定义为:c1enum { 2 FALLBACK_DSQ_ID = 0, 3 MAX_CPUS = 4096, 4 MS_TO_NS = 1000LLU * 1000, 5 TIMER_INTERVAL_NS = 1 * MS_TO_NS, 6};Todo: 为什么使用
FALLBACK_DSQ_ID呢? -
再看一个example中自行实现的宏
MEMBER_VPTR. 其用于获取一个检查过的指针指向的结构体或数组成员. 编译器通常可能会打乱指令执行的顺序, 而该宏强制编译器产生一段先计算字节偏移量检查是否越界, 再实际计算偏移后的地址来产生成员的实际指针.c1/** 2 * MEMBER_VPTR - Obtain the verified pointer to a struct or array member 3 * @base: struct or array to index 4 * @member: dereferenced member (e.g. ->field, [idx0][idx1], ...) 5 * 6 * The verifier often gets confused by the instruction sequence the compiler 7 * generates for indexing struct fields or arrays. This macro forces the 8 * compiler to generate a code sequence which first calculates the byte offset, 9 * checks it against the struct or array size and add that byte offset to 10 * generate the pointer to the member to help the verifier. 11 * 12 * Ideally, we want to abort if the calculated offset is out-of-bounds. However, 13 * BPF currently doesn't support abort, so evaluate to NULL instead. The caller 14 * must check for NULL and take appropriate action to appease the verifier. To 15 * avoid confusing the verifier, it's best to check for NULL and dereference 16 * immediately. 17 * 18 * vptr = MEMBER_VPTR(my_array, [i][j]); 19 * if (!vptr) 20 * return error; 21 * *vptr = new_value; 22 */ 23#define MEMBER_VPTR(base, member) (typeof(base member) *)({ \ 24 u64 __base = (u64)base; \ 25 u64 __addr = (u64)&(base member) - __base; \ 26 asm volatile ( \ 27 "if %0 <= %[max] goto +2\n" \ 28 "%0 = 0\n" \ 29 "goto +1\n" \ 30 "%0 += %1\n" \ 31 : "+r"(__addr) \ 32 : "r"(__base), \ 33 [max]"i"(sizeof(base) - sizeof(base member))); \ 34 __addr; \ 35}) -
其传入的
cpu_gimme_task其实就是一个bool数组, 每个CPU占一个元素. 如果指针非空, 则设置gimme内容为true.c1/* can't use percpu map due to bad lookups */ 2static bool cpu_gimme_task[MAX_CPUS]; -
检查将要分发的CPU是不是中心服务器, 如果是的话调用
bpf_loop.c1/* 2 * bpf_loop 3 * 4 * for **nr_loops**, call **callback_fn** function 5 * with **callback_ctx** as the context parameter. 6 * the **callback_fn** should be a static function and 7 * the **callback_ctx** should be a pointer to the stack. 8 * the **flags** is used to control certain aspects of the helper. 9 * currently, the **flags** must be 0. currently, nr_loops is 10 * limited to 1 << 23 (~8 million) loops. 11 * 12 * long (\*callback_fn)(u32 index, void \*ctx); 13 * 14 * where **index** is the current index in the loop. the index 15 * is zero-indexed. 16 * 17 * if **callback_fn** returns 0, the helper will continue to the next 18 * loop. if return value is 1, the helper will skip the rest of 19 * the loops and return. other return values are not used now, 20 * and will be rejected by the verifier. 21 * 22 * 23 * returns 24 * the number of loops performed, **-einval** for invalid **flags**, 25 * **-e2big** if **nr_loops** exceeds the maximum number of loops. 26 */ 27static long (*bpf_loop)(__u32 nr_loops, void *callback_fn, void *callback_ctx, __u64 flags) = (void *) 181;这段代码定义了一个名为 “bpf_loop” 的 bpf 助手函数. 该函数有四个参数:
-
nr_loops:给定函数应该循环执行的次数
-
callback_fn:指向一个静态函数的指针,该函数将在循环中执行
-
callback_ctx:指向上下文参数的指针,该参数将传递给回调函数
-
flags:一个当前未使用的参数
回调函数应该具有以下签名:
c1long (*callback_fn)(u32 index, void *ctx);index 参数表示循环中的当前索引, ctx 是传递给 bpf_loop 函数的上下文参数.
如果成功, bpf_loop 函数返回执行的循环次数, 如果 flags 无效则返回 -einval, 如果 nr_loops 超过最大循环次数则返回 -e2big.
-
-
通过
bpf_loop循环执行若干次dispatch_to_one_cpu_loopfn代码, 传入NULL.c1static int dispatch_to_one_cpu_loopfn(u32 idx, void *data) 2{ 3 s32 cpu = idx; 4 5 if (cpu >= 0 && cpu < MAX_CPUS) { 6 bool *gimme = MEMBER_VPTR(cpu_gimme_task, [cpu]); 7 if (gimme && !*gimme) 8 return 0; 9 } 10 11 bpf_loop(1 << 23, dispatch_a_task_loopfn, &cpu, 0); 12 return 0; 13}-
该代码中,
idx为bpf_loop时的索引, 即为CPU号. -
检查对应CPU是否有
gimme标志, 如果没有设置的话, 对于该CPU的loop即可return 0 -
不然, 则进一步使用
bpf_loop循环调用dispatch_a_task_loopfn, 传入当前CPU的指针作为参数.
c1static int dispatch_a_task_loopfn(u32 idx, void *data) 2{ 3 s32 cpu = *(s32 *)data; 4 s32 pid; 5 struct task_struct *p; 6 bool *gimme; 7 8 if (bpf_map_pop_elem(¢ral_q, &pid)) 9 return 1; 10 11 __sync_fetch_and_sub(&nr_queued, 1); 12 13 p = scx_bpf_find_task_by_pid(pid); 14 if (!p) { 15 __sync_fetch_and_add(&nr_lost_pids, 1); 16 return 0; 17 } 18 19 /* 20 * If we can't run the task at the top, do the dumb thing and bounce it 21 * to the fallback dsq. 22 */ 23 if (!scx_bpf_cpumask_test_cpu(cpu, p->cpus_ptr)) { 24 __sync_fetch_and_add(&nr_mismatches, 1); 25 scx_bpf_dispatch(p, FALLBACK_DSQ_ID, SCX_SLICE_INF, 0); 26 return 0; 27 } 28 29 /* dispatch to the local and mark that @cpu doesn't need more tasks */ 30 scx_bpf_dispatch(p, SCX_DSQ_LOCAL_ON | cpu, SCX_SLICE_INF, 0); 31 32 if (cpu != central_cpu) 33 scx_bpf_kick_cpu(cpu, 0); 34 35 gimme = MEMBER_VPTR(cpu_gimme_task, [cpu]); 36 if (gimme) 37 *gimme = false; 38 39 return 1; 40}-
该函数首先通过
bpf_map_pop_elem从map中弹一个元素出来, 第一个参数为map的指针, 第二个为存储了结果的指针, 指针指向了在central_enqueue过程中加入到bpf映射表中的任务的pid -
通过
scx_bpf_find_task_by_pid根据pid获取任务描述符p, 进而获取cpus_ptr对cpu标志进行测试. 如果为0, 意味着Todo? 分发到默认的FALLBACK_DSQ_ID里去. -
不然则实际分发到对应的CPU本地dsq中. 同时, 如果该CPU不是中心CPU, 则应该手动kick一次敦促它进行一次调度. 由于分发了任务, 则可以将gimme清为False.
-
Todo. 不过, 为什么要执行
1 << 23次这么多次呢..
-
-
回到
dispatch方法中, 如果目标不是中心服务器的则踢中心服务器一下即可, 让它为我们统一分发任务
[Todo]sched_ext_ops
sched_ext_ops如何实际被使用?
该结构体仅在有限的几个地方被提及, 除了tool中的example最主要的就是kernel/sched/ext.c中.
1#define SCX_OP_IDX(op) (offsetof(struct sched_ext_ops, op) / sizeof(void (*)(void)))其中的offsetof是一个简单的辅助宏:
1#ifndef offsetof
2#define offsetof(TYPE, MEMBER) ((unsigned long)&((TYPE *)0)->MEMBER)
3#endifSCX_OP_IDX又进一步被SCX_HAS_OP宏包裹:
1#define SCX_HAS_OP(op) static_branch_likely(&scx_has_op[SCX_OP_IDX(op)])static_key_false 是 Linux 内核中的一个宏, 用于实现一种基于位图的轻量级键值系统. 这个宏定义了一个静态的、全局的、只包含一个位的变量, 用于表示一个特定的键是否被设置为“false”.
1struct static_key_false scx_has_op[SCX_NR_ONLINE_OPS] =
2 { [0 ... SCX_NR_ONLINE_OPS-1] = STATIC_KEY_FALSE_INIT };使用一些工具生成单文件的函数调用图:
1cflow -d 3 ~/SCX/sched_ext/kernel/sched/ext.c | tree2dotx | dot -Tpng -o ~/SCX/dot/ext.png
sched_ext机制实际部署
如何使用
kernel文档的这一节Documentation/scheduler/sched-ext.rst告诉了我们一些使用的方法:
1Switching to and from sched_ext
2===============================
3
4``CONFIG_SCHED_CLASS_EXT`` is the config option to enable sched_ext and
5``tools/sched_ext`` contains the example schedulers.
6
7sched_ext is used only when the BPF scheduler is loaded and running.
8
9If a task explicitly sets its scheduling policy to ``SCHED_EXT``, it will be
10treated as ``SCHED_NORMAL`` and scheduled by CFS until the BPF scheduler is
11loaded. On load, such tasks will be switched to and scheduled by sched_ext.
12
13The BPF scheduler can choose to schedule all normal and lower class tasks by
14calling ``scx_bpf_switch_all()`` from its ``init()`` operation. In this
15case, all ``SCHED_NORMAL``, ``SCHED_BATCH``, ``SCHED_IDLE`` and
16``SCHED_EXT`` tasks are scheduled by sched_ext. In the example schedulers,
17this mode can be selected with the ``-a`` option.
18
19Terminating the sched_ext scheduler program, triggering sysrq-S, or
20detection of any internal error including stalled runnable tasks aborts the
21BPF scheduler and reverts all tasks back to CFS.
22
23.. code-block:: none
24
25 # make -j16 -C tools/sched_ext
26 # tools/sched_ext/scx_example_dummy -a
27 local=0 global=3
28 local=5 global=24
29 local=9 global=44
30 local=13 global=56
31 local=17 global=72
32 ^CEXIT: BPF scheduler unregistered
33
34If ``CONFIG_SCHED_DEBUG`` is set, the current status of the BPF scheduler
35and whether a given task is on sched_ext can be determined as follows:
36
37.. code-block:: none
38
39 # cat /sys/kernel/debug/sched/ext
40 ops : dummy
41 enabled : 1
42 switching_all : 1
43 switched_all : 1
44 enable_state : enabled
45
46 # grep ext /proc/self/sched
47 ext.enabled : 1那么我们打开这些内核选项, 编译一个内核, 使用make编译ebpf程序.
遗憾的是并不如愿, 第一个问题在于make编译内核还必须要打开btf选项, 开启btf必须又要选择debugging的一个什么模式, 具体不复现了, 只是说明一下. Todo
第二个问题在于使用make尝试编译一下ebpf程序会G:
1make -j16 -C tools/sched_ext主要是rustc编译器报的错, 涉及到Makefile中的这个object:
1atropos: export RUSTFLAGS = -C link-args=-lzstd
2atropos: export ATROPOS_CLANG = $(CLANG)
3atropos: export ATROPOS_BPF_CFLAGS = $(BPF_CFLAGS)
4atropos: $(INCLUDE_DIR)/vmlinux.h
5 cargo build --manifest-path=atropos/Cargo.toml $(CARGOFLAGS)
具体是这个函数中, 说找不到libclang.a
1/// Finds a directory containing LLVM and Clang static libraries and returns the
2/// path to that directory.
3fn find() -> PathBuf {
4 let name = if target_os!("windows") {
5 "libclang.lib"
6 } else {
7 "libclang.a"
8 };
9
10 let files = common::search_libclang_directories(&[name.into()], "LIBCLANG_STATIC_PATH");
11 if let Some((directory, _)) = files.into_iter().next() {
12 directory
13 } else {
14 panic!("could not find any static libraries");
15 }
16}首要想法还是看看能不能关闭动态链接(但其实后来发现这个想法很蠢, 因而静态链接是为了移植到qemu中, 关了那肯定运行不了), 去sched_ext/tools/sched_ext/atropos/Cargo.toml L27 删除feature中的"static"参数即可:
1bindgen = { version = "0.61.0", features = ["logging"], default-features = false }补充: <bindgen - crates.io: Rust Package Registry> 这个rust库是用于构建绑定C/C++标准库的Rust EFI程序用的.
当时没想明白, 宿主机跑了一下动态编译出来的bpf程序, 报错:
1libbpf: Failed to bump RLIMIT_MEMLOCK (err = -1), you might need to do it explicitly!
2libbpf: Error in bpf_object__probe_loading():Operation not permitted(1). Couldn't load trivial BPF program. Make sure your kernel supports BPF (CONFIG_BPF_SYSCALL=y) and/or that RLIMIT_MEMLOCK is set to big enough value.
3libbpf: failed to load object 'scx_example_dummy'
4libbpf: failed to load BPF skeleton 'scx_example_dummy': -1
5scx_example_dummy: scx_example_dummy.c:79: main: Assertion `!scx_example_dummy__load(skel)' failed.
6zsh: IOT instruction (core dumped) tools/sched_ext/scx_example_dummy -a关于bump RLIMIT_MEMLOCK, chat了一下好像是这样:
“Locked-in-memory size” 是一个进程可以将物理内存锁定到其虚拟地址空间中的最大量。当内存被锁定时,操作系统的内存管理子系统会阻止其交换到磁盘上。
锁定内存可以提高需要快速访问大量数据的应用程序的性能。例如,数据库和其他高性能应用程序可能会受益于将内存锁定在RAM中以最小化数据访问延迟。
然而,锁定内存也具有一些潜在的缺点。如果一个进程锁定了过多的内存,而其他进程需要访问物理内存,则可能没有足够的内存可用,这可能会导致诸如系统不稳定甚至崩溃等问题。因此,管理员需要仔细管理“Locked-in-memory size”,以确保所有正在运行的进程有足够的可用内存。
不过其实问题的本质在于我的ArchLinux没有打开bpf啊, 肯定是不能在本机运行的… 需要进入qemu虚拟机跑patch过的内核才行, 这个时候我才意识到我干了件多么蠢的事情…
看起来在实际部署sched_ext之前, 还需要做不少准备工作.
准备工作
为了调试一个自编译的Linux内核, 使用现成的发行版甚至是LFS都是不太方便的, 很容易折腾了半天赔了夫人又折兵.. 感觉剩下的唯一一条路还是使用虚拟机的方式调试内核, 那么还是使用QEMU+Busybox套件… <基于QEMU搭建内核调试环境 - rqdmap | blog>
关于编译一个libclang.a的静态链接库, 这里有一篇Guide(
<在AArch64平台上静态编译链接eBPF相关的工具 | 点滴汇聚>), 但是使用的是2019年发布的llvm-8系列, 不知道什么原因, 最终make不成功, 我不想去花时间修一个5年前的套件所带来的一些问题.
不过可以从其中参考cmake的一些选项, 当安装了llvm-project-15.0.7的相关套件( <Releases · llvm/llvm-project>)后, 可以尝试使用这些选项编译一个llvm的子项目?
- 关于子项目, llvm的项目结构好像发生了很大的变化, 或者是因为我下载的是project系列, 总之在编译时需要指定子项目的目录, 所以下面的cmake才需要指定
llvm文件夹.
1mkdir build; cd build
2
3cmake ../llvm -DCMAKE_INSTALL_PREFIX=$HOME/SCX/clang/install -DBUILD_SHARED_LIBS=OFF \
4-DLLVM_BUILD_LLVM_DYLIB=ON -DLIBCLANG_BUILD_STATIC=ON \
5-DCMAKE_BUILD_TYPE=Release -DCLANG_BUILD_EXAMPLES=OFF -DCLANG_INCLUDE_DOCS=OFF \
6-DCLANG_INCLUDE_TESTS=OFF -DLLVM_APPEND_VC_REV=OFF -DLLVM_BUILD_DOCS=OFF \
7-DLLVM_BUILD_EXAMPLES=OFF -DLLVM_BUILD_TESTS=OFF \
8-DLLVM_BUILD_TOOLS=ON -DLLVM_ENABLE_ASSERTIONS=OFF -DLLVM_ENABLE_CXX1Y=ON \
9-DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_LIBCXX=OFF -DLLVM_ENABLE_PIC=ON \
10-DLLVM_ENABLE_RTTI=ON -DLLVM_ENABLE_SPHINX=OFF -DLLVM_ENABLE_TERMINFO=OFF \
11-DLLVM_INCLUDE_DOCS=OFF -DLLVM_INCLUDE_EXAMPLES=OFF -DLLVM_INCLUDE_GO_TESTS=OFF \
12-DLLVM_INCLUDE_TESTS=OFF -DLLVM_INCLUDE_TOOLS=ON -DLLVM_INCLUDE_UTILS=OFF \
13-DLLVM_PARALLEL_LINK_JOBS=1 -DLLVM_TARGETS_TO_BUILD="host;BPF"报黄黄的Warning:
1CMake Warning:
2 Manually-specified variables were not used by the project:
3
4 CLANG_BUILD_EXAMPLES
5 CLANG_INCLUDE_DOCS
6 CLANG_INCLUDE_TESTS
7 LIBCLANG_BUILD_STATIC
8 LLVM_ENABLE_CXX1Y发现有问题, 这个Warning至关重要, 因为LIBCLANG_BUILD_STATIC好像不被支持了, 那我这样接着搞半天也编译不出来libclang.a.
忽然意识到此时的子项目是llvm.. 但我其实需要的是libclang相关…
修改上述的llvm子项目为clang项目即可!
编译出来的目标文件树大概为这样:
1.
2├── bin
3├── include
4├── lib
5│ ├── clang
6│ ├── cmake
7│ ├── libclang.a
8│ ├── libclangAnalysis.a
9│ ├── libclangAnalysisFlowSensitive.a
10│ ├── libclangAnalysisFlowSensitiveModels.a
11│ ├── libclangAPINotes.a
12│ ├── libclangARCMigrate.a
13│ ├── libclangAST.a
14│ ├── ...
15│ ├── libclang.so -> libclang.so.15
16│ ├── libclang.so.15 -> libclang.so.15.0.7
17│ ├── libclang.so.15.0.7
18│ ├── ...
19│ ├── libear
20│ └── libscanbuild
21├── libexec
22└── share发现lib里面好像就已经有了我们想要的内容! 而且版本与本机是一致的, 都是15.0.7!
不过我发现libclang.a居然很小, 看了一下发现最大的居然是libclang.so..
1# ls -lh | awk '{print $5, $9}' | sort -hr
2
373M libclang-cpp.so.15
439M libclang.so.15.0.7
527M libclangSema.a
622M libclangStaticAnalyzerCheckers.a
717M libclangAST.a
816M libclangCodeGen.a
913M libclangBasic.a
1011M libclangDynamicASTMatchers.a
118.5M libclangStaticAnalyzerCore.a
127.0M libclangDriver.a
136.5M libclangARCMigrate.a
145.9M libclangTransformer.a
154.6M libclangAnalysis.a
164.3M libclangFrontend.a
173.8M libclangSerialization.a
183.7M libclangASTMatchers.a
192.6M libclangParse.a
201.9M libclangToolingRefactoring.a
211.9M libclangLex.a
221.9M libclangFormat.a
231.8M libclangTooling.a
241.5M libclangAnalysisFlowSensitiveModels.a
251.5M libclang.a我并不是很理解, 不过还是先放进去(放到了/usr/local/lib/里, 不要污染我本机的lib路径)看一下. 不过并不能成功编译, 报错少一些函数的实现. 那么感觉实际上clang是把不同的功能分散了多个.a文件中了, 因而如果想要静态编译还得把所有的静态库全部塞到路径里面去, 那么将该lib文件夹整体放到路径下, 再次编译, 又报下错:
1"kernel/bpf/btf.c:6403:2: error: #warning "btf argument scalar test nerfed" [-Werror=cpp]"bpf内部产生了Warning… 我其实并不很想直接关闭Warning, 因为产生该Warning意味着bpf内核代码执行到了开发者不曾设想的道路上, 可能会产生错误… 不过也只能关闭该内核编译参数了:
1# KBUILD_CFLAGS-$(CONFIG_WERROR) += -Werror
随后总算编译成功!
QEMU+Busybox启动
将编译出来的可执行文件塞到rootfs中, 生成rootfs镜像文件, 启动qemu!
在qemu中试图执行这几个scx可执行文件, 但是很奇怪的是…
为什么会显示可执行文件not found呢?…
其实最开始使用动态连接的时候也将当时编译好的程序塞进来过, 也是报这个错误, 而这几个程序在我的宿主机都能跑起来且能正常报错, 当时以为这是动态连接的问题, 结果现在还是出现该问题.
经过一些思考, 我感觉还是busybox太简朴了, 在网络上搜索时发现了buildroot套件, 应该可以理解为busybox的超集.
尝试使用buildroot做根文件系统吧!
Buildroot
Github仓库: <buildroot/buildroot>
参考( <eBPF_Summit_2020-Lightning-Lorenzo_Fontana-Debugging_the_BPF_Virtual_Machine.pdf>),
1git clone git://git.buildroot.net/buildroot /source/buildroot
2cd buildroot
3make menuconfig
4make -j16而如何配置menuconfig呢, 这篇微信推文居然给出了很好的答案(
<调试eBPF虚拟机>), 这里做一个整理:
最终结果:
MISC
eBPF
深入浅出eBPF
可以细读这一篇, 其对于eBPF如何与用户程序交互做了详细的说明: <深入浅出 BPF TCP 拥塞算法实现原理 | 深入浅出 eBPF>
下面对其内容进行学习.
考虑一个样例:
1SEC(".struct_ops")
2struct tcp_congestion_ops dctcp = {
3 .init = (void *)dctcp_init,
4 .in_ack_event = (void *)dctcp_update_alpha,
5 .cwnd_event = (void *)dctcp_cwnd_event,
6 .ssthresh = (void *)dctcp_ssthresh,
7 .cong_avoid = (void *)tcp_reno_cong_avoid,
8 .undo_cwnd = (void *)dctcp_cwnd_undo,
9 .set_state = (void *)dctcp_state,
10 .flags = TCP_CONG_NEEDS_ECN,
11 .name = "bpf_dctcp",
12};其中需要注意的是在 BPF 程序中定义的 tcp_congestion_ops 结构(也被称为 bpf-prg btf 类型), 该类型可以与内核中定义的结构体完全一致(被称为 btf_vmlinux btf 类型), 也可为内核结构中的部分必要字段, 结构体定义的顺序可以不需内核中的结构体一致, 但是名字, 类型或者函数声明必须一致(比如参数和返回值).
- 按照我的理解其实就是一个override? 所以任意的函数子集均可?
因此可能需要从 bpf-prg btf 类型到 btf_vmlinux btf 类型的一个翻译过程, 这个转换过程使用到的主要是 BTF 技术, 目前主要是通过成员名称、btf 类型和大小等信息进行查找匹配, 如果不匹配 libbpf 则会返回错误. 整个转换过程与 Go 语言类型中的反射机制类似, 主要实现在函数 bpf_map__init_kern_struct_ops
-
为什么需要转换技术? 可能是因为结构体字节排列的问题吗? 需要自己做一个查找并映射? 以及转换过程与反射机制, 具体实现?
-
bpf-prg以及btf_vmlinux? 以及vmlinux到底是啥
在 eBPF 程序中增加 section 名字声明为 .struct_ops, 用于 BPF 实现中识别要实现的 struct_ops 结构, 例如当前实现的 tcp_congestion_ops 结构. 在 SEC(".struct_ops") 下支持同时定义多个 struct_ops 结构. 每个 struct_ops 都被定义为 SEC(".struct_ops") 下的一个全局变量. libbpf 为每个变量创建了一个 map, map 的名字为定义变量的名字, 本例中为 bpf_dctcp_nouse 和 dctcp.
- 所以这个
.struct_ops是bpf预先定义好的, 还是自己取的? 以及bpf如何与之交互?
用户态的核心代码为:
1static void test_dctcp(void)
2{
3 struct bpf_dctcp *dctcp_skel;
4 struct bpf_link *link;
5
6 // 脚手架生成的函数
7 dctcp_skel = bpf_dctcp__open_and_load();
8 if (CHECK(!dctcp_skel, "bpf_dctcp__open_and_load", "failed\n"))
9 return;
10
11 // bpf_map__attach_struct_ops 增加了注册一个 struct_ops map 到内核子系统
12 // 这里为我们上面定义的 struct tcp_congestion_ops dctcp 变量
13 link = bpf_map__attach_struct_ops(dctcp_skel->maps.dctcp);
14 if (CHECK(IS_ERR(link), "bpf_map__attach_struct_ops", "err:%ld\n",
15 PTR_ERR(link))) {
16 bpf_dctcp__destroy(dctcp_skel);
17 return;
18 }
19
20 do_test("bpf_dctcp");
21
22 # 销毁相关的数据结构
23 bpf_link__destroy(link);
24 bpf_dctcp__destroy(dctcp_skel);
25}据其所说, 交互流程为:
-
在 bpf_object__open 阶段, libbpf 将寻找 SEC(".struct_ops") 部分, 并找出 struct_ops 所实现的 btf 类型. 需要注意的是, 这里的 btf-type 指的是 bpf_prog.o 的 btf 中的一个类型. “struct bpf_map” 像其他 map 类型一样, 通过 bpf_object__add_map() 进行添加. 然后 libbpf 会收集(通过 SHT_REL)bpf progs 的位置(使用 SEC(“struct_ops/xyz”) 定义的函数), 这些位置是 func ptrs 所指向的地方. 在 open 阶段并不需要 btf_vmlinux.
-
在 bpf_object__load 阶段, map 结构中的字段(赖于 btf_vmlinux) 通过 bpf_map__init_kern_struct_ops() 初始化. 在加载阶段, libbpf 还会设置 prog->type、prog->attach_btf_id 和 prog->expected_attach_type 属性. 因此, 程序的属性并不依赖于它的 section 名称.
-
然后, 所有 obj->maps 像往常一样被创建(在 bpf_object__create_maps()). 一旦 map 被创建, 并且 prog 的属性都被设置好了, libbpf 就会继续执行. libbpf 将继续加载所有的程序.
-
bpf_map__attach_struct_ops() 是用来注册一个 struct_ops map 到内核子系统中.
那么应该可以认为.struct_ops是libbpf定义好的专门存放结构体的位置, 随后在后续阶段该结构体中的对应函数将被依次执行.
上面是如何编写与加载一个bpf程序进入内核, 下面说明一下内核是如何支持这种能力的.
在这个TCP结构中, 内核中对应的操作对象结构(ops 结构)为bpf_tcp_congestion_ops, 定义在/net/ipv4/bpf_tcp_ca.c 文件中:
1/* Avoid sparse warning. It is only used in bpf_struct_ops.c. */
2extern struct bpf_struct_ops bpf_tcp_congestion_ops;
3
4struct bpf_struct_ops bpf_tcp_congestion_ops = {
5 .verifier_ops = &bpf_tcp_ca_verifier_ops,
6 .reg = bpf_tcp_ca_reg,
7 .unreg = bpf_tcp_ca_unreg,
8 .check_member = bpf_tcp_ca_check_member,
9 .init_member = bpf_tcp_ca_init_member,
10 .init = bpf_tcp_ca_init,
11 .name = "tcp_congestion_ops",
12};看到这里其实就发现sched_ext中也是遇到了这个结构, 但是不知道怎么分析所以才来网上又查了下bpf的具体装载过程; 有关sched_ext的先暂且搁置, 继续分析TCP的这个例子.
据作者说:
-
init() 函数将被首先调用, 以进行任何需要的全局设置;
-
init_member() 则验证该结构中任何字段的确切值. 特别是, init_member() 可以验证非函数字段(例如, 标志字段);
-
check_member() 确定目标结构的特定成员是否允许在 BPF 中实现;
-
reg() 函数在检查通过后实际注册了替换结构; 在拥塞控制的情况下, 它将把 tcp_congestion_ops 结构(带有用于函数指针的适当的 BPF 蹦床(trampolines ))安装在网络堆栈将使用它的地方;
-
unreg() 撤销注册;
-
verifier_ops 结构有一些函数, 用于验证各个替换函数是否可以安全执行;
最后,在kernel/bpf/bpf_struct_ops_types.h中添加一行:
1BPF_STRUCT_OPS_TYPE(tcp_congestion_ops)在bpf_struct_ops.c文件中包含bpf_struct_ops_types.h4次, 并分别设置 BPF_STRUCT_OPS_TYPE 宏, 实现了 map 中 value 值结构的定义和内核定义 ops 对象数组的管理功能, 同时也包括对应数据结构 BTF 中的定义.
- 居然是多次包含, 感觉很奇妙, 回头可以深究一下具体的原因
1/* bpf_struct_ops_##_name (e.g. bpf_struct_ops_tcp_congestion_ops) is
2 * the map's value exposed to the userspace and its btf-type-id is
3 * stored at the map->btf_vmlinux_value_type_id.
4 *
5 */
6#define BPF_STRUCT_OPS_TYPE(_name) \
7extern struct bpf_struct_ops bpf_##_name; \
8 \
9struct bpf_struct_ops_##_name { \
10 BPF_STRUCT_OPS_COMMON_VALUE; \
11 struct _name data ____cacheline_aligned_in_smp; \
12};
13#include "bpf_struct_ops_types.h" // ① 用于生成 bpf_struct_ops_tcp_congestion_ops 结构
14#undef BPF_STRUCT_OPS_TYPE
15
16enum {
17#define BPF_STRUCT_OPS_TYPE(_name) BPF_STRUCT_OPS_TYPE_##_name,
18#include "bpf_struct_ops_types.h" // ② 生成一个 enum 成员
19#undef BPF_STRUCT_OPS_TYPE
20 __NR_BPF_STRUCT_OPS_TYPE,
21};
22
23static struct bpf_struct_ops * const bpf_struct_ops[] = {
24#define BPF_STRUCT_OPS_TYPE(_name) \
25 [BPF_STRUCT_OPS_TYPE_##_name] = &bpf_##_name,
26#include "bpf_struct_ops_types.h" // ③ 生成一个数组中的成员 [BPF_STRUCT_OPS_TYPE_tcp_congestion_ops]
27 // = &bpf_tcp_congestion_ops
28#undef BPF_STRUCT_OPS_TYPE
29};
30
31void bpf_struct_ops_init(struct btf *btf, struct bpf_verifier_log *log)
32{
33/* Ensure BTF type is emitted for "struct bpf_struct_ops_##_name" */
34#define BPF_STRUCT_OPS_TYPE(_name) BTF_TYPE_EMIT(struct bpf_struct_ops_##_name);
35#include "bpf_struct_ops_types.h" // ④ BTF_TYPE_EMIT(struct bpf_struct_ops_tcp_congestion_ops btf 注册
36#undef BPF_STRUCT_OPS_TYPE
37
38 // ...
39}至此内核完成了 ops 结构的类型的生成、注册和 ops 对象数组的管理.
最后说明bpf_map__init_kern_struct_ops, 该过程涉及将 bpf 程序中定义的变量初始化为内核变量.
1/* Init the map's fields that depend on kern_btf */
2static int bpf_map__init_kern_struct_ops(struct bpf_map *map,
3 const struct btf *btf,
4 const struct btf *kern_btf)使用 bpf 程序结构初始化 map 结构变量的主要流程如下(摘录, 尚且未考):
bpf 程序加载过程中会识别出来定义的 BPF_MAP_TYPE_STRUCT_OPS map 对象;
获取到 struct ops 定义的变量类型(如 struct tcp_congestion_ops dctcp)中的 tcp_congestion_ops 类型, 使用获取到 tname/type/type_id 设置到 map 结构中的 st_ops 对象中;
通过上一步骤设置的 tname 属性在内核的 btf 信息表中查找内核中 tcp_congestion_ops 类型的 type_id 和 type 等信息, 同时也获取到 map 对象中 value 值类型 bpf_struct_ops_tcp_congestion_ops 的 vtype_id 和 vtype 类型;
至此已经拿到了 bpf 程序中定义的变量及 bpf_prog btf-type tcp_congestion_ops, 内核中定义的类型 tcp_congestion_ops 以及 map 值类型的 bpf_struct_ops_tcp_congestion_ops 等信息;
接下来的事情就是通过特定的 btf 信息规则(名称、调用参数、返回类型等)将 bpf_prog btf-type 变量初始化到 bpf_struct_ops_tcp_congestion_ops 变量中, 将内核中的变量初始化以后, 放入到 st_ops->kern_vdata 结构中(bpf_map__attach_struct_ops() 函数会使用 st_ops->kern_vdata 更新 map 的值, map 的 key 固定为 0 值(表示第一个位置);
然后设置 map 结构中的 btf_vmlinux_value_type_id 为 vtype_id 供后续检查和使用, map->btf_vmlinux_value_type_id = kern_vtype_id;
kernel/bpf/bpf_struct_ops_types.h:
1/* SPDX-License-Identifier: GPL-2.0 */
2/* internal file - do not include directly */
3
4#ifdef CONFIG_BPF_JIT
5#ifdef CONFIG_NET
6BPF_STRUCT_OPS_TYPE(bpf_dummy_ops)
7#endif
8#ifdef CONFIG_INET
9#include <net/tcp.h>
10BPF_STRUCT_OPS_TYPE(tcp_congestion_ops)
11#endif
12#ifdef CONFIG_SCHED_CLASS_EXT
13#include <linux/sched/ext.h>
14BPF_STRUCT_OPS_TYPE(sched_ext_ops)
15#endif
16#endif<A thorough introduction to eBPF [LWN.net]>
<使用C语言从头开发一个Hello World级别的eBPF程序 | Tony Bai>
<在AArch64平台上静态编译链接eBPF相关的工具 | 点滴汇聚>
LIBCLANG_STATIC_PATH
1git clone https://github.com/llvm/llvm-project.git
2# git clone --depth=1 https://github.com/llvm/llvm-project.git
3cd llvm-project
4git checkout release/13.x
5cd clang
6cd tools
7cd libclang
8
9mkdir build
10cd build
11cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release ..
12
13make libclang