关于本博客?
关于博客…根源是悠久的, 最初的 CSDN 博客 在这里, 而梦最开始的地方 在这里.
第二代博客用的是hexo + NexT主题, 感觉有些过于泯于众人的theme(关键博客内容也没有什么实质技术力), 后来换了些主题但是仍然不算很满意…
第三代尝试用hugo(看到大大的博客蛮不错), 结果折腾了一阵子好像主题的git子模块一直有问题, 就没再弄了, 完全在本地VsCode插件预览模式下看文章.
四代的 Hugo 主题使用看上去极简的Theme yinyang, 拿到后读了下源码, 0前端基础的情况下稍微用这个作为骨架魔改后用了一段时间, 学习了下hugo以及一些基础的前端内容..
不过由于yinyang里面有很多我不需要的内容, 之后便完全重写了自己的 blank 主题, 基于的也是一个超极简的hugo主题 blank , 这一代主题用了相当久的时间…
但是在24年秋招时期发现这坨主题怎么这么丑, 从 HTML & JS & CSS 的编码到 Hugo 模板的分包到样式的设计都是弄的一坨.. 特别是一想象到面试官有可能会打开简历上个人主页进行仔细的审查与拷打(虽然感觉几乎没有什么面试官真正看过就是了!).. 更加感觉这份门面有点过于不堪了, 因此忙里偷闲又迭代更新了一版: inkwell
目前的应该是第六代主题, 从前端样式到 Hugo 代码均进行了很大程度的升级. 由于改动较大, 不太想在老版的 blank 主题继续开发了(fork出来后也还一直没给自己的主题起名字!), 同时也已经几乎与最开始的骨架 blank 主题无关了, 因此新创建 Hugo 主题仓库, 希望能以此生根发芽变得更好用.
内容展示与前端样式
本节将展示博客前端的主要功能特性, 并简要说明其实现原理.
自动添加外链背景
使用 Markdown 语法添加 URL 链接 ([]()), 手动改写渲染的钩子模板, 自动检测目标 URL 是否为站内 URL, 并据此来动态添加 class 样式:

但是还是会有一些漏网之鱼, 比如 www.rqdmap.top, rqdmap.top, https://rqdmap.top 等其实不太容易区分, 但目前不打算实现特别通用但复杂的判断逻辑..
不过后续博客的默认遵守的规范是: 站内 URL 直接以相对路径(/path/to/post) 表示, 不再带有绝对 URL 了, 因此准确度应该还是可以的.
Hook 判断代码如下, 进而根据 Hugo 变量决定 CSS 类的变化:
1{{ $isExternalLink := false }}
2{{ if or (strings.HasPrefix .Destination "http://") (strings.HasPrefix .Destination "https://")}}
3 {{ if not (strings.HasPrefix .Destination "{{ .Site.Params.BaseURL }}") }}
4 {{ $isExternalLink = true }}
5 {{ end }}
6{{ end }}代码块
代码块目前将显示代码类型 Type, 并提供复制以及折叠两个功能.
1#include <bits/stdc++.h>
2
3class Base {
4public:
5 virtual Base& clone();
6 virtual Base self();
7};
8
9class Derived : public Base {
10public:
11
12 virtual Derived& clone();
13 virtual Derived self();
14};
15
16
17
18/**
19 1
20 2
21 3
22 4
23 5
24 6
25 7
26 8
27 9
28 10
29*/
30int main(void) {
31 Base().show();
32 Derived().show();
33 return 0;
34}目前折叠功能仅对不少于一定数量行的代码块启用, 过短的代码块则不支持折叠功能.
1$ echo 这是一个很短的代码块所以不会启用折叠功能使用时, 支持通过添加参数的方式决定是否默认启用折叠:
1 ```cpp{fold=true}
2 默认折叠的很长的代码段..
3 ...引用块
冲浪时发现维基百科有这样的一种样式, 设计非常的板正且复古, 模仿着实现为引用块的样式.
这是一段引用块
引用了一些名人名言
特殊高亮块
一些文中插入的特殊块, 用于提醒、补充一些内容, 并且为 GPT 生成式内容提供了专门的蓝色块以显示.
内容
内容
内容
内容
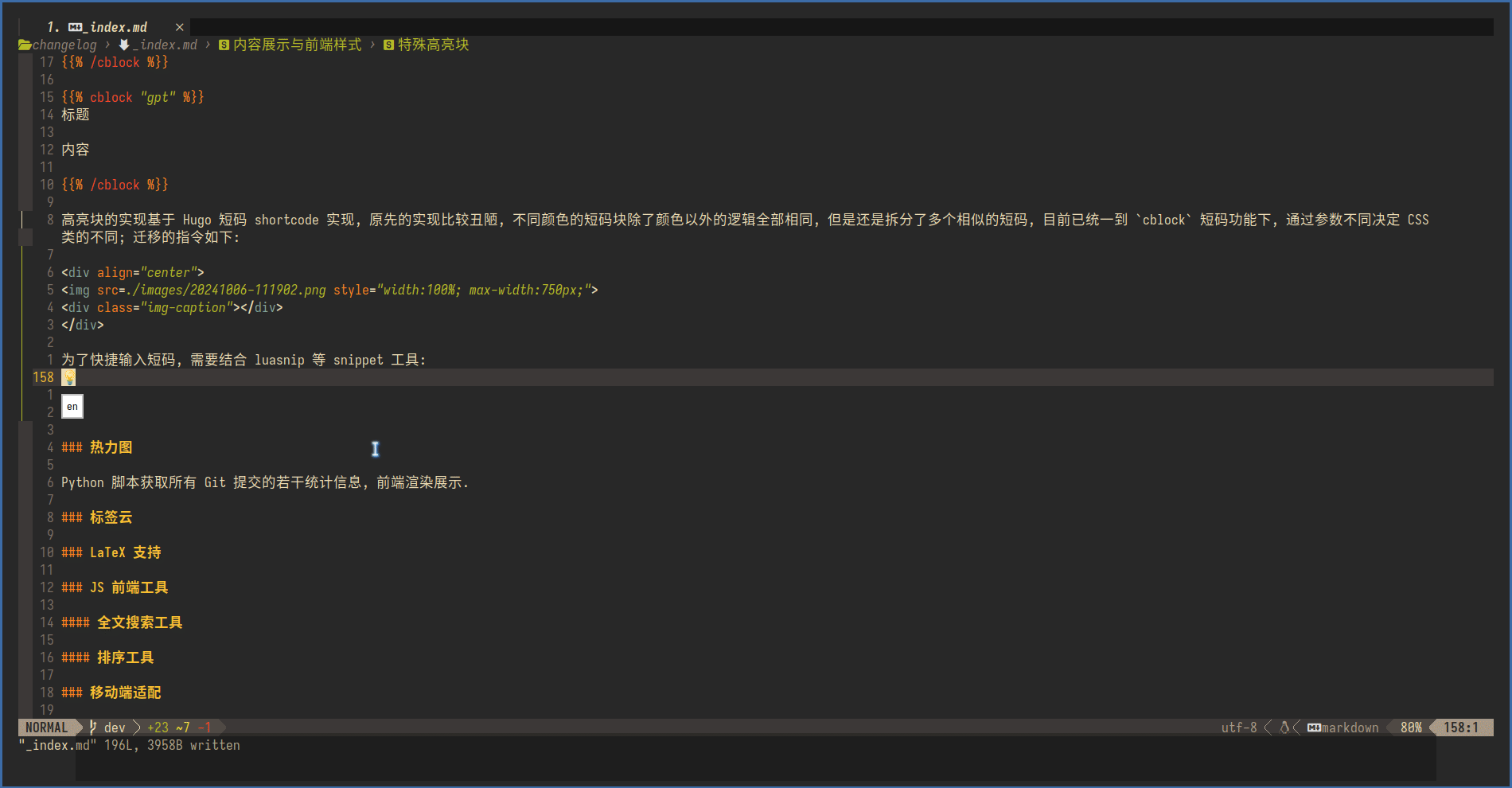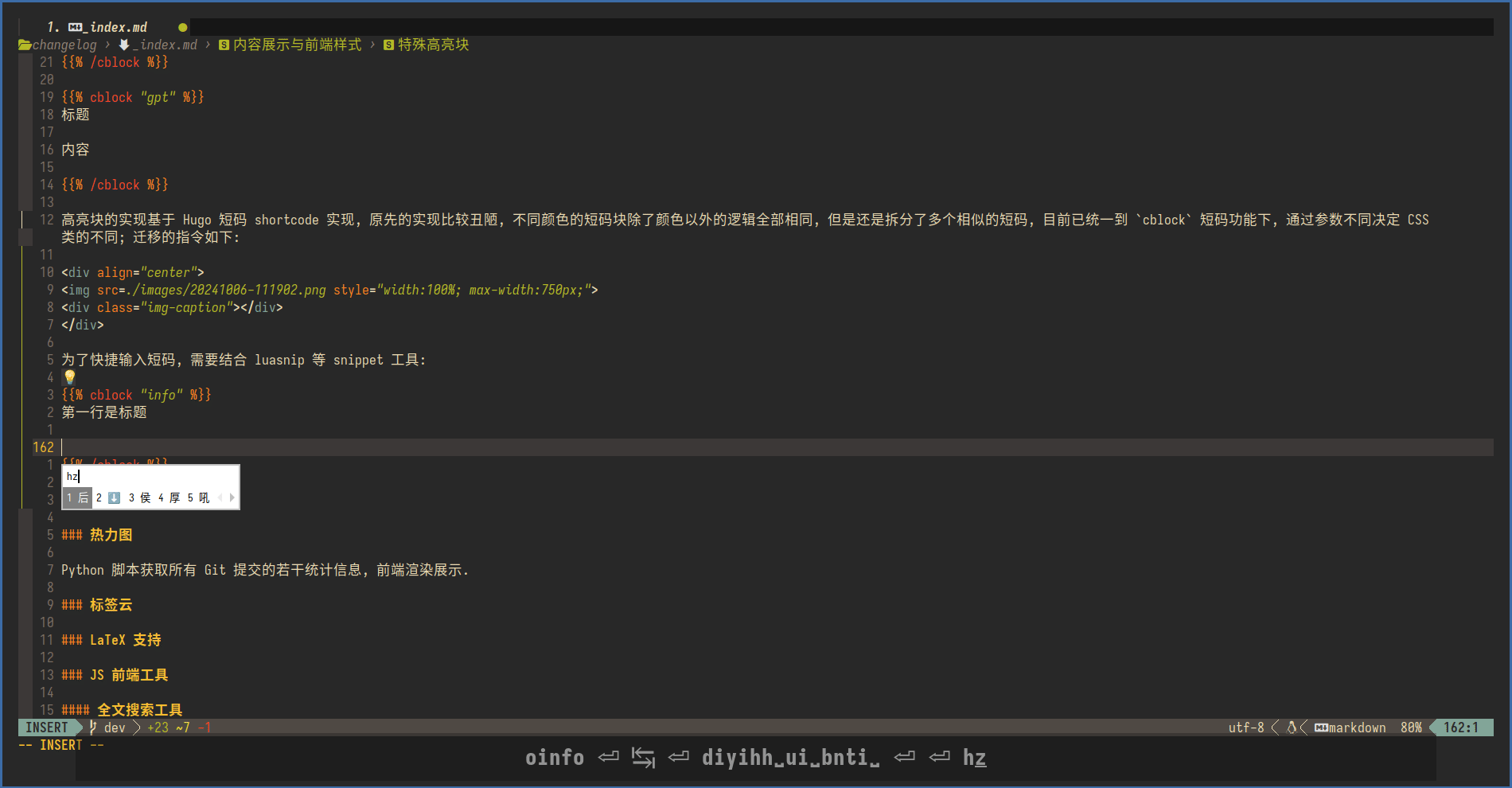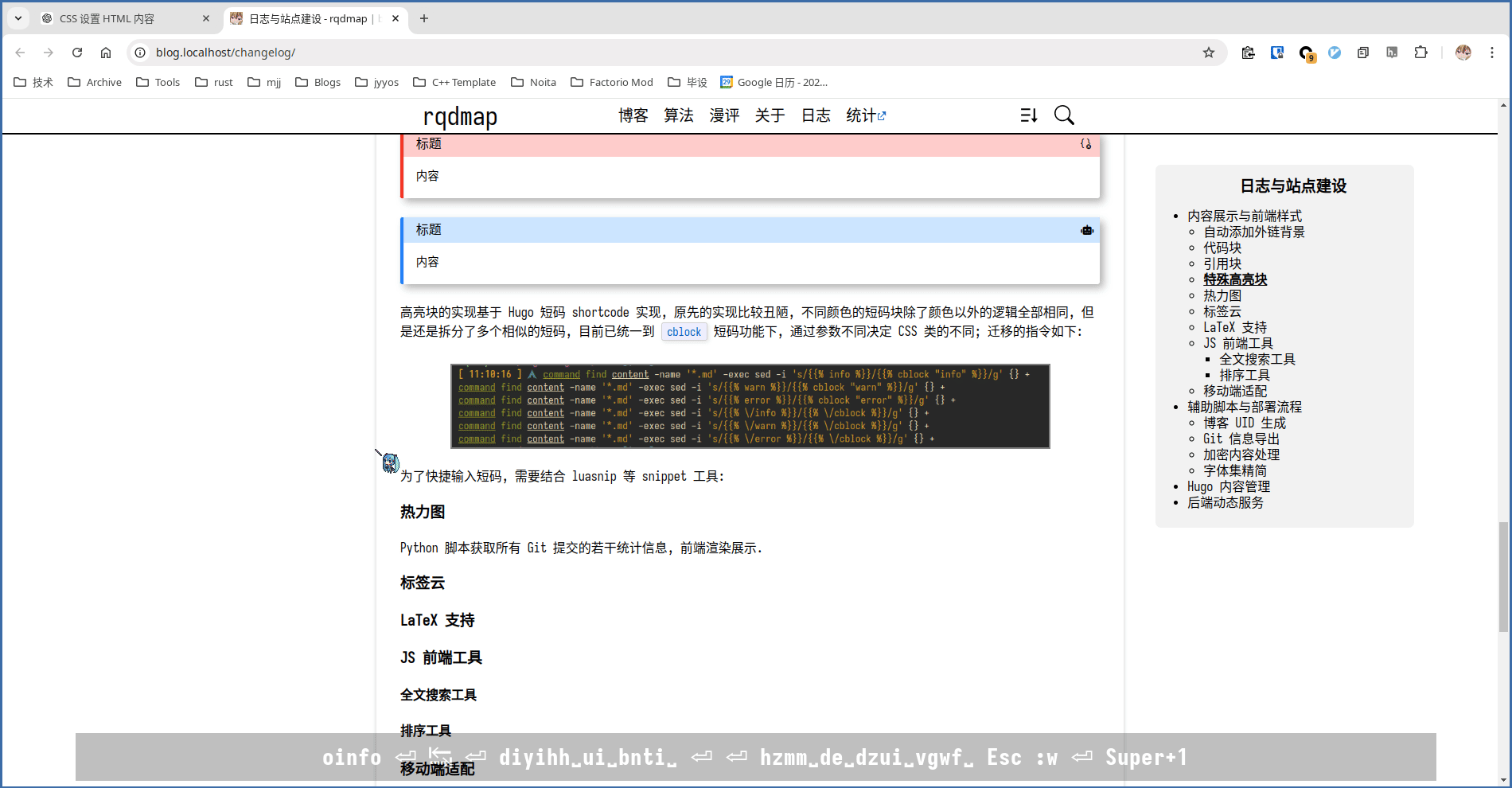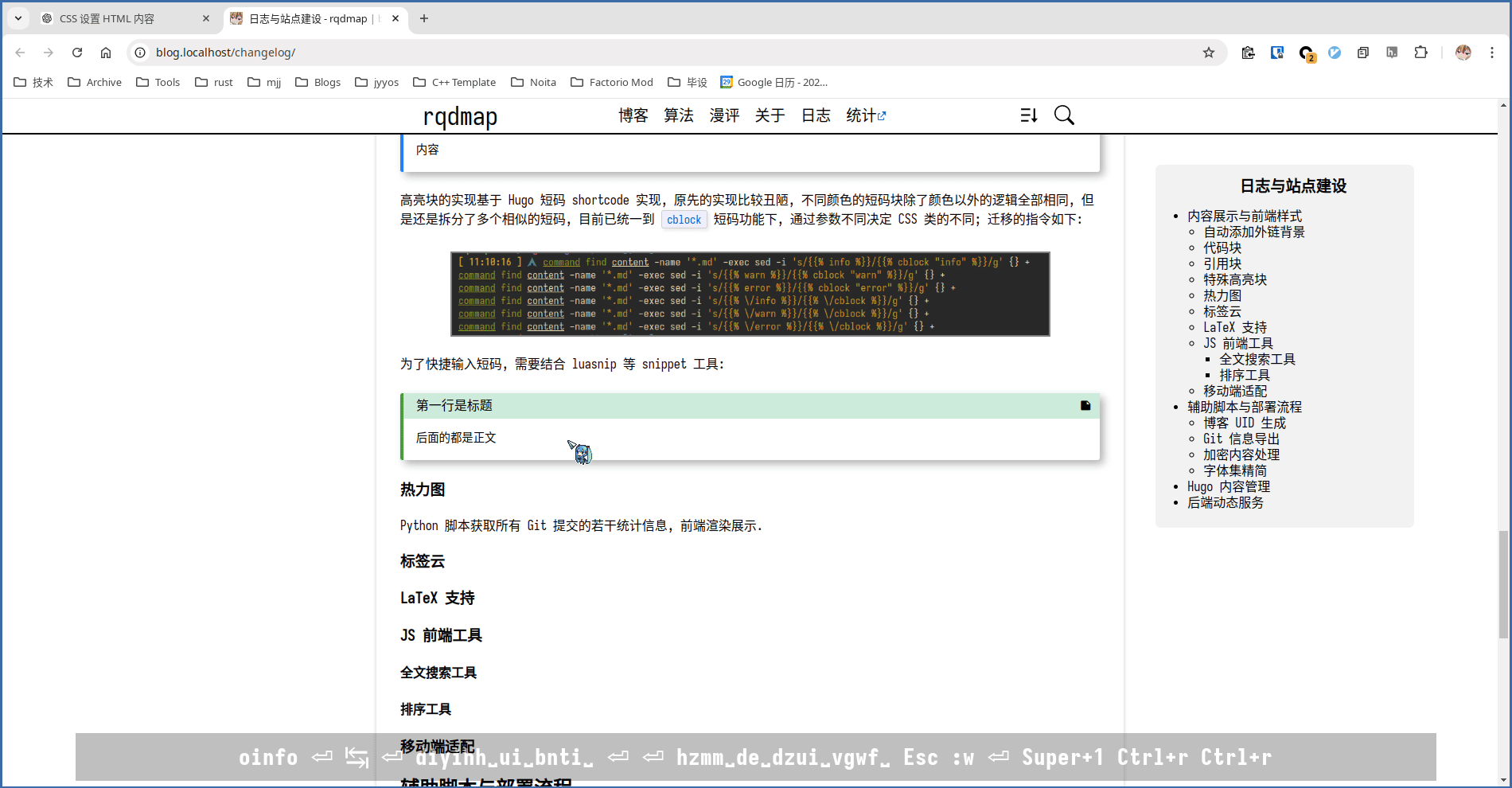
高亮块的实现基于 Hugo 短码 shortcode 实现, 原先的实现比较丑陋, 不同颜色的短码块除了颜色以外的逻辑全部相同, 但是还是拆分了多个相似的短码, 目前已统一到 cblock 短码功能下, 通过参数不同决定 CSS 类的不同; 迁移的指令如下:

- 短码在
```代码块中也会被 Hugo 当作模板进行渲染, 因此采用了截图的方式..
为了快捷输入短码, 需要结合 luasnip 等 snippet 工具:
TOC 滚动监控
当页面滚动时, 侧边的目录会自动高亮展示当前章节; 该功能并不是所有的 Hugo 主题支持, 因此自己搓一个简单的 JS 即可.
原本使用了限流函数, 这样当滚动页面时只会少量触发更新函数, 不过王老师体验了一下说这样会让人感觉卡卡的, 就直接实时监听滚动了.
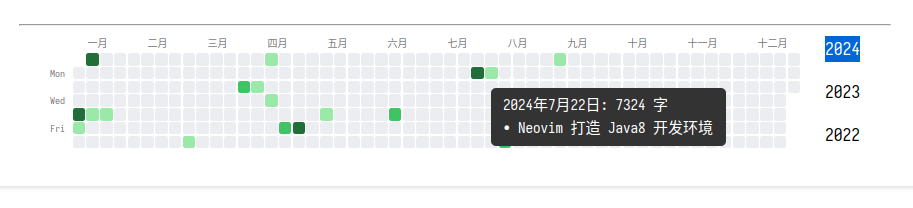
热力图
使用外部的 Python 脚本获取所有 Git 提交的统计信息(时间、变化的行数、变化的字数等), 前端渲染展示.
标签云
封装 tag-cloud 作为 Hugo partial 模板, 通过传递参数, 指定词云收集的列表项目所在位置:
1{{ .Scratch.Set "TargetPage" "/categories" }}
2{{ .Scratch.Set "weightFactor" "10" }}
3{{ partial "tag-cloud" . }}通过调控 weightFactor 可以调整不同数量级词云的字体大小.

LaTeX 公式支持
对于一些老的 ACM/ICPC 博文而言, LaTeX 数学公式支持是不可或缺的, 因此配备了 katex
但印象里好像 katex 还是比较重的, 包括 js 和对应的字体, 后续不确定会不会进行优化
- 此外, <Hugo博客添加LaTeX语法支持> 提到的三对大括号就会无法渲染的问题好像已经解决
JS 前端工具
实现了一些客户端侧的工具, 如内容列表排序、全局搜索等功能.
全文搜索工具
支持对全体文章标题与内容进行匹配搜索, 搜索逻辑个人手写, 暂不支持模糊搜索与更细粒度的筛选器(比如仅搜索某类别下的文章); 搜索界面前端的样式和风格我很满意, 感觉是很好看的.
虽然我写的这一坨 JS 代码实在是一次性产品, 不想看第二遍; anyway it works
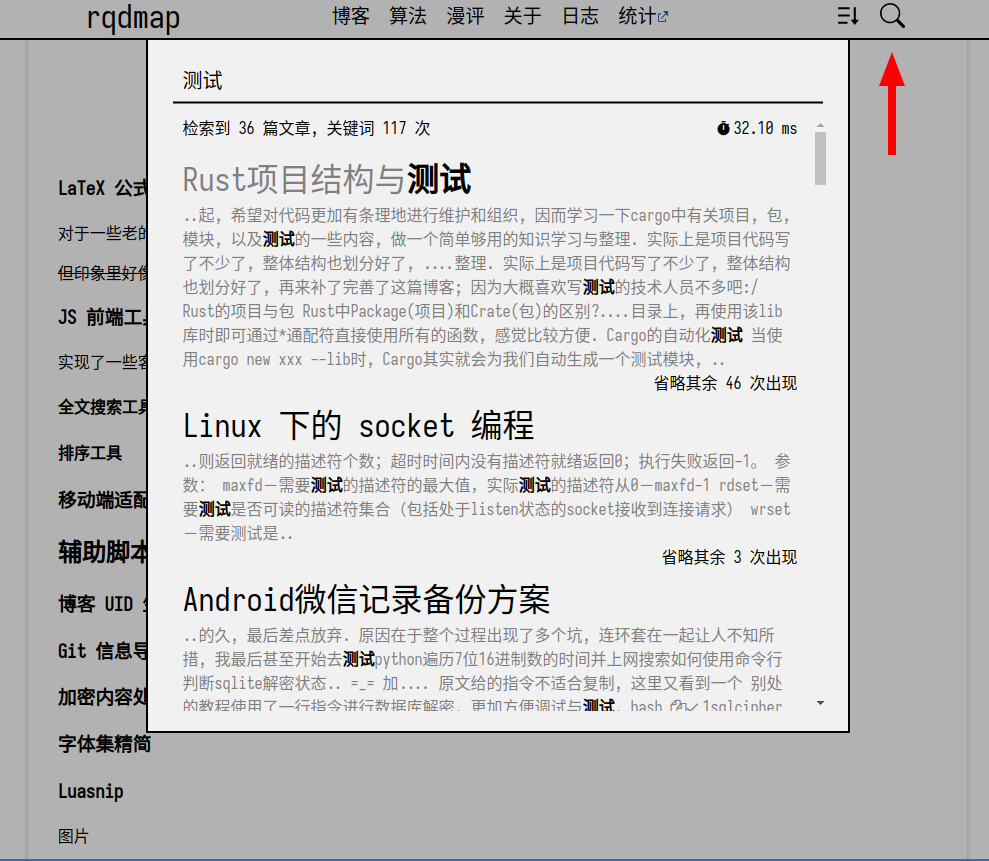
在搜索方案技术选型时, 考察过了一些更加成熟的方案, 比如第三方的模糊搜索库、动态接口查询方案等…
-
三方库隐约记得查询出来的结果不是很符合预期(不确定是不是 CJK 的原因或者是我用错了), 并且三方库的查询结果可能比较难与我预期的前端展示方案相配合, 还会引入一大坨别人的 JS 进来, 不是很好用, 遂放弃;
-
至于动态查询方案, 尽管其能力更强, 但总感觉为一个静态的博客类网站配置这么多动态内容是不好的, 而且服务器位于美西, 每次查询都将带来巨大的时延, 遂放弃
最终选用 Hugo 模板静态生成一个包含所有原始正文的 XML 文件, 当用户搜索时在该文件中做搜索即可.
-
懒加载 or 后台异步下载? 异步下载的好处在于用户实际点开搜索时几乎无延迟, 但缺点在于每一个访问我博客的访客都将请求一次全量的数据集合, 🤔目前月访客大概有2k, 数据文件大约2M(bzip进一步压缩后仅有500K!), 流量是不成问题的, 做成异步的感觉不错; 懒加载的话也还行, 因为看上去几乎没啥人使用我的搜索功能🤡, 500K 的流量请求时延也是可以接受的.
-
由于 bzip 压缩后流量确实比较小, 因此目前选用后台自动下载的方案以提高用户体验.
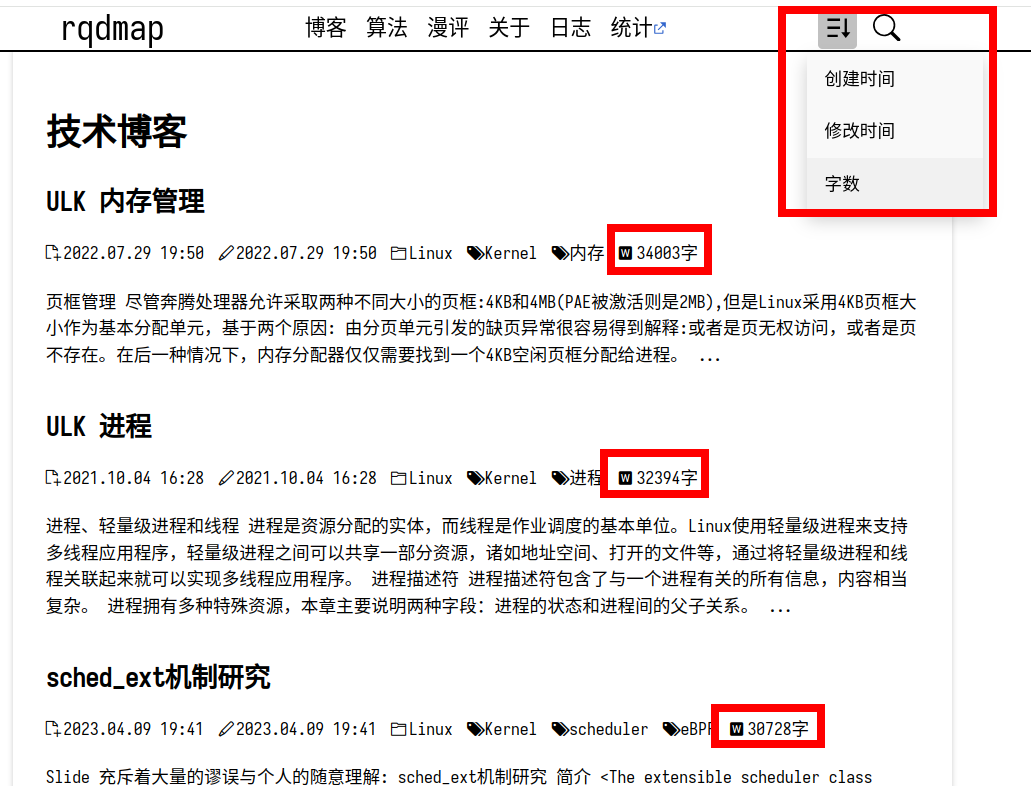
排序工具
自动收集特定 CSS Class 的内容, 排序后重新展示; 并且在 URL 中添加 GET 参数 sort, 持久化排序的结果.
文章修改日志
样式的话我实在不会设计, GPT 老师给出了一种方案, 看上去还行.
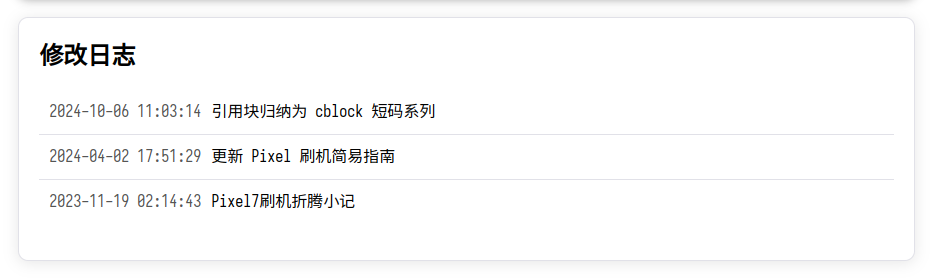
基于 Python 脚本生成所有文章的 Git 历史信息, Hugo 模板导入后渲染.
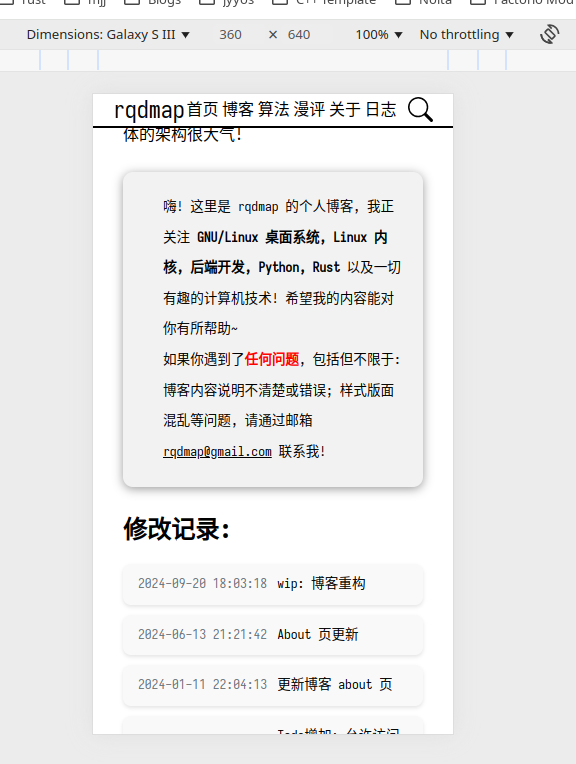
移动端适配
根据 umami 收集来的信息, 可以发现手机用户还是比较多的, 但是我实在是移动端设计苦手, 加上要把 CSS 设计得统一且优雅也很困难, 因此目前仅仅做了简单的适配.

移动端适配主要考虑屏幕的宽度, 经过测试, 总的来说宽度不低于360的屏幕基本上都能够显示的还行, 尽管样式还是相当丑..

辅助脚本与部署流程
脚本工作流程
Python 脚本与正文内容均私有 Git 管理, 部署脚本如下:
1#!/bin/zsh
2
3pkill -f 'hugo server'
4
5rm -rf public; hugo --enableGitInfo
6
7python3 ./scripts/add_post_id.py
8
9lazygit
10
11python3 ./scripts/gitinfo.py
12
13python3 ./scripts/minimize_font.py
14
15rm -rf public; hugo --enableGitInfo
16
17python3 ./scripts/encrypt.py
18
19# rsync to Nginx server
20# ...博客 UID 生成
在 Hugo 博客生成框架下, 源文件生成到目标网页后, 文件的名称可能发生变化, 比如大写变成小写等情况(ArchLinux -> archlinux), 我并没有找到标准的名称转换规则, 但是在一些场景下需要知道源文件与目标网页文件的映射关系, 因此使用 Python 脚本向源文件中内嵌一个唯一的标识符, 生成为网页后标识符也将存在于 HTML 的 head 段; 这样带来两个好处:
-
更加灵活的博客管理能力; 由于获取了双向的映射关系, 很多部署侧的脚本功能得以实现
-
更精简的访客统计能力; 将 Page UID 传递给后端即可, 而不需要传递一串长长的还可能包含 CJK 的百分号编码过来, 同时也简化了后端的字符串校验策略, 接口更加安全
同时由于博客内容本身基于 Git 管理, 因此在部署脚本中使用 Lazygit 交互式操作 Git 信息, 嵌入 UID 后再统一地进行 Git 信息的提交.
Git 信息导出
原生hugo只支持通过短码 {{ .gitInfo }}
<GitInfo | Hugo> 查看最近一次的git提交, 不符合要求..
因此使用 Python 脚本自行实现, 遍历所有的源文件, 查看 Git 日志详情:
1[
2 {
3 "id": "xxxxxxxxxx",
4 "log": [
5 {
6 "hash": "04f8e3619590f09ba0c74da2f7d8b3b8516aa0da",
7 "date": "2023-09-01 18:14:49",
8 "message": "单独划分ACM专题; 移动部分博客进入黑洞归档"
9 },
10 {
11 "hash": "bf5bcfaed05f6766d5d2967f438c1803d40ac2c4",
12 "date": "2023-05-29 23:05:14",
13 "message": "博客结构与操作脚本重构"
14 },
15 {
16 "hash": "5f63b96fbe0c5efa92d60904df9e9c43ea0c24b5",
17 "date": "2023-05-08 21:44:36",
18 "message": "博客架构修改升级"
19 },
20 {
21 "hash": "93a5b9e9bcdae073c7bf007beabc5cf2076622ed",
22 "date": "2022-11-16 01:27:34",
23 "message": "迁移老博客文章内容"
24 }
25 ]
26 },
27 ...同时, Git 信息也支持了热力图的展现, 因此以 Commit 为维度, 计算本次提交的字符以及行数的变化, 收集为 Json 文件:
1[
2 ...
3 {
4 "hash": "6fac1b53b0344505ecbe1a1b9615c25796168a7c",
5 "date": "2024-04-19 21:57:47",
6 "message": "前缀函数(KMP) 应用一例",
7 "change_files": 3,
8 "add_lines": 99,
9 "delete_lines": 1,
10 "char_diff": 2585
11 },
12 {
13 "hash": "9c78fb1a74b2d9f10b86432f255b5193be82f50c",
14 "date": "2024-04-10 19:27:27",
15 "message": "切换代码块为浅色主题(pygments)",
16 "change_files": 2,
17 "add_lines": 2,
18 "delete_lines": 2,
19 "char_diff": 1
20 },
21
22 ...博客加密处理
Markdown 源文件利用短码生成特定结构的 HTML 结构, 生成完静态文件后, 使用 Python Beautiful 三方库操作 HTML 元素, 进行 AES 对称加密, 修饰原本的 HTML 文件; 前端引入 CryptoJS, 根据用户传入的密钥进行 AES 解密.
字体集精简
参考: <网页字体精简方案 - rqdmap | blog>
后端接口服务
访客统计
前端 JS 脚本收集 UA 等信息发往后端, 后端根据 IP 限流: 单文章一分钟记录一次 PV, 全站一分钟至多记录 60 次 PV; 不过这也是君子协定, 单纯过滤掉一些无聊的人狂F5刷新网页造成PV数据统计失真, 真的有 IP 池还是能分分钟把我打爆.
接口返回 PV 和 UV 信息, 用于渲染网页相关的元素.
除了个人实现的简单访客统计接口外, 还接入了 umami 进行更易用且直观的数据分析.
Todo 下一步工作
参考文献收集
自动化收集文章中出现的参考文献, 并统一展示
图片自动化处理
目前的图片直接原图上传并显示, 后续希望能自动化收集并处理图片资源, 实现图片自动化大小压缩与水印添加功能.
批注功能
对于一些知识类的博客文章, 常常会引用一些别人的内容并提出自己的评论, 但基于 Markdown 的编排方式是单纯线性的, 因此希望引入批注功能, 将评论与知识体系本身抽离开发.
站点统计信息展示
介绍站点文章相关的统计信息, 可以考虑利用后端接口给出一些动态的内容.
Git 历史信息查看
待定; Bootstrap 的文档是基于 Hugo 生成的, 其支持历史提交查看, 可以参考进行实现; 但是不确定其对于资源的消耗, 以及敏感信息的露出等问题..
接入 bangumi 等三方网站
目前的漫评有点单薄, 希望接入 neodb 或者 bangumi 等外部网站; 具体策略还没想好.
