这是一个令人兴奋的想法! 其目的在于按需精简字体库, 以使得网页在保证显示效果的同时减少需要传输的数据量.
我个人使用的字体为思源黑的CJK+Iosevka的西文, 为了实现强制爱(x), 之前对于博客字体的处理方式都是用css指定本地的字体文件, 手动压一份woff2的Iosevka和思源黑的字体放在网站服务器上, 如果用户没有的话就去下载吧(导致加载缓慢), 而且由于缺省字体的存在, 会造成特别明显的FOUT(Flash Of Unstyled Text)问题, 特别是最近新加坡接连抽风, 不确定是不是被FireWall管控了, 流量被控制了, 经常出现字体根本下载不出来的情况.
目前中西文字体加起来接近2MB, 这可能比我整个博客网页其余所有的css+js等资源加起来还要多了! 因而心血来潮地想要仔细搞一搞字体的事情, One brick to build Roman.
朴素的考虑就是根据博客中所有已经出现的符号, 去除掉未使用的汉字、icon等, 进而达到精简字体包的效果. 事实证明, 这很有效.
手动解析TTF的尝试
为了精简TTF字体库, 那么至少得知道TTF文件的编码格式吧!
最初参考了文章: TTF字体格式入门 - 掘金, 尝试搞了一些解码器等, 并进一步练习了快乐的 Rust :)
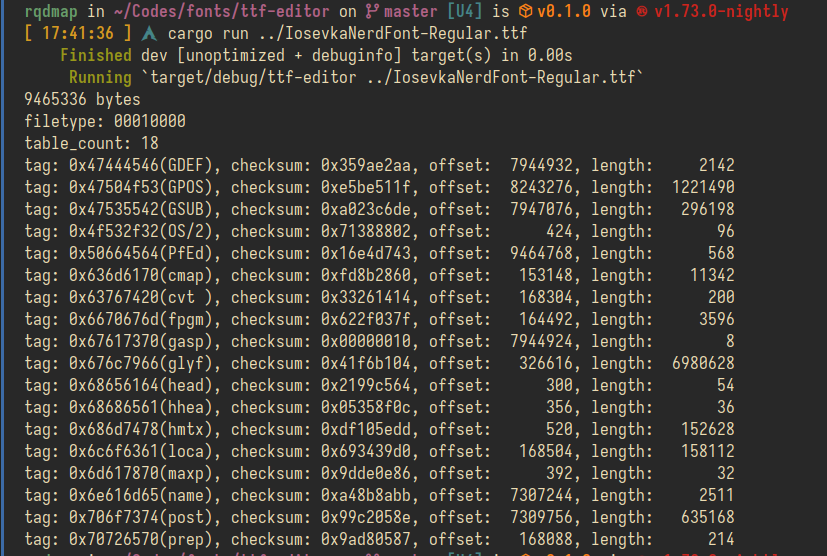
TTF文件总的来说分为目录和表两部分, 最开始的几个字节按顺序是:
-
u32, 文件类型, 0x00010000便是TTF格式
-
u16, tables数量
-
6个不知道干啥的字节, 已跳过
-
多个table的元数据, 每个元数据有4个u32的字段: (tag: u32, checksum:u32, offset:u32, length: u32)
这些其实都很好理解, 复杂的其实在于每个表都是干啥的. 稍微找了一圈网络好像没有看到quickstart的上手指南, 只有apple官方给的手册: Fonts - TrueType Reference Manual - Apple Developer. 尝试去看了下, 发现与其读这个我不如还是原地转行去做字体设计师吧..
另外有关表的内容, 上述掘金社区的博客的内容可以作为一些参考, glyf为字体的绘制方式, cmap为编码和glyf数字的映射, loacl解释的好像不对因为在iosevka中器长度远小于glyf, head为一些全局信息.
好了, 总之手动解析重复造轮子是吃力不讨好的事情, 加上我并不立志成为一名字体设计师, 对这些的原理没有那么感兴趣, 所以还是打算找找一些现成的工具.
字体选择
最开始使用的还是Iosevka+思源黑, 后来在查阅资料时发现有个叫 更纱黑体的字体恰好是思源黑的CJK+Iosevka的西文, 太符合我的要求了! 而且两套字体合一可以方便我对字体进行操作, 因而后续就考虑切换到更纱黑作为字体选择!
在下载字体的时候, 其实遇到了很多不同的型号.. 比如思源黑的Region Specified, Language Specified, 还是VF可变权重的版本.. Iosevka的Mono, Term, Slab(貌似是那种更厚的无衬线字体, 用于大标题等等)..
最终的选择是: sarasa-term-sc-regular
参考:
字符集准备
在写快速脚本方面, python确实是不错的. 由于博客下面存在了不少二进制的文件, 目前的策略是用扩展名来过滤, 只检查md, html, css, js, toml结尾的文件.
1import os
2
3# 获取当前目录
4current_dir = os.getcwd()
5
6chars = set()
7
8targets = [
9 # "./content",
10 # "./themes/blank"
11 "./"
12]
13
14accept = [
15 "md",
16 "html",
17 "js",
18 "css",
19 "toml",
20]
21
22def check_ext(file):
23 for i in accept:
24 if file.endswith(i):
25 return True
26 return False
27
28def solve_file(file):
29 with open(file, 'r') as file:
30 content = file.read()
31 for i in content:
32 chars.add(i)
33
34cnt = 0
35
36for target in targets:
37 for dirpath, dirnames, filenames in os.walk(target):
38 print(dirpath, dirnames, filenames)
39 for filename in filenames:
40 if check_ext(filename):
41 file = dirpath + '/' + filename
42
43 solve_file(file)
44
45listed_chars = list(chars)
46listed_chars.sort()
47print(len(listed_chars))
48print(listed_chars)
49
50with open('words', 'w+') as file:
51 file.write(' '.join(listed_chars))统计出来其实还是很震撼的:

看上去感觉不多, 这一面屏幕居然是我一百多篇博客1563957个字节(截至到2023-07-21 17:14:00)一共使用过的汉字. 不过实际上这面屏幕上只有2000个左右的汉字, 但是还是比预想的要少很多, 看来一些专家所说的能够流利对话与日常生活所需的词汇量的大小确实是有经过科学考据的.
font-carrier
最先看到的工具是掘金博客中提到的 font-carrier. Github的README说的是:
1var fontCarrier = require('font-carrier')
2var transFont = fontCarrier.transfer('./test/test.ttf')
3// 会自动根据当前的输入的文字过滤精简字体
4transFont.min('我是精简后的字体,我可以重复')
5transFont.output({
6 path: './min'
7})事实上确实将字符集与字体包填入后可以运行, 一路无报错, 令人安心, 而且生成的字体大小确实是根据字符集大小变化而变化..
不过坏消息是, 生成的字体放入博客中实际使用时无法渲染! 无论是iosevka还是思源黑, 经过测试均不行!
令人遗憾, 可能毕竟是一个两年前的项目了经久失修..
fontmin
又看到一个高star的活跃的字体精简方案, 十分的不错: Fontmin - 字体子集化方案
根据文档给出的api接口说明, 实例化一个Fontmin并run即可.
1const fs = require('fs')
2var text = fs.readFileSync('./words', 'utf8')
3// text = '️'
4console.log(text)
5
6var Fontmin = require('fontmin');
7
8var fontmin = new Fontmin()
9 .src('./FontPatcher/SarasaTermSCNerdFont-Regular.ttf')
10 .dest('build')
11 .use(Fontmin.glyph({
12 text: text,
13 hinting: false,
14 }));
15
16fontmin.run(function (err, files) {
17 if (err) {
18 throw err;
19 }
20 console.log(files[0]);
21});需要注意, 如果不禁用hinting, 则会产生奇怪的高度偏移:
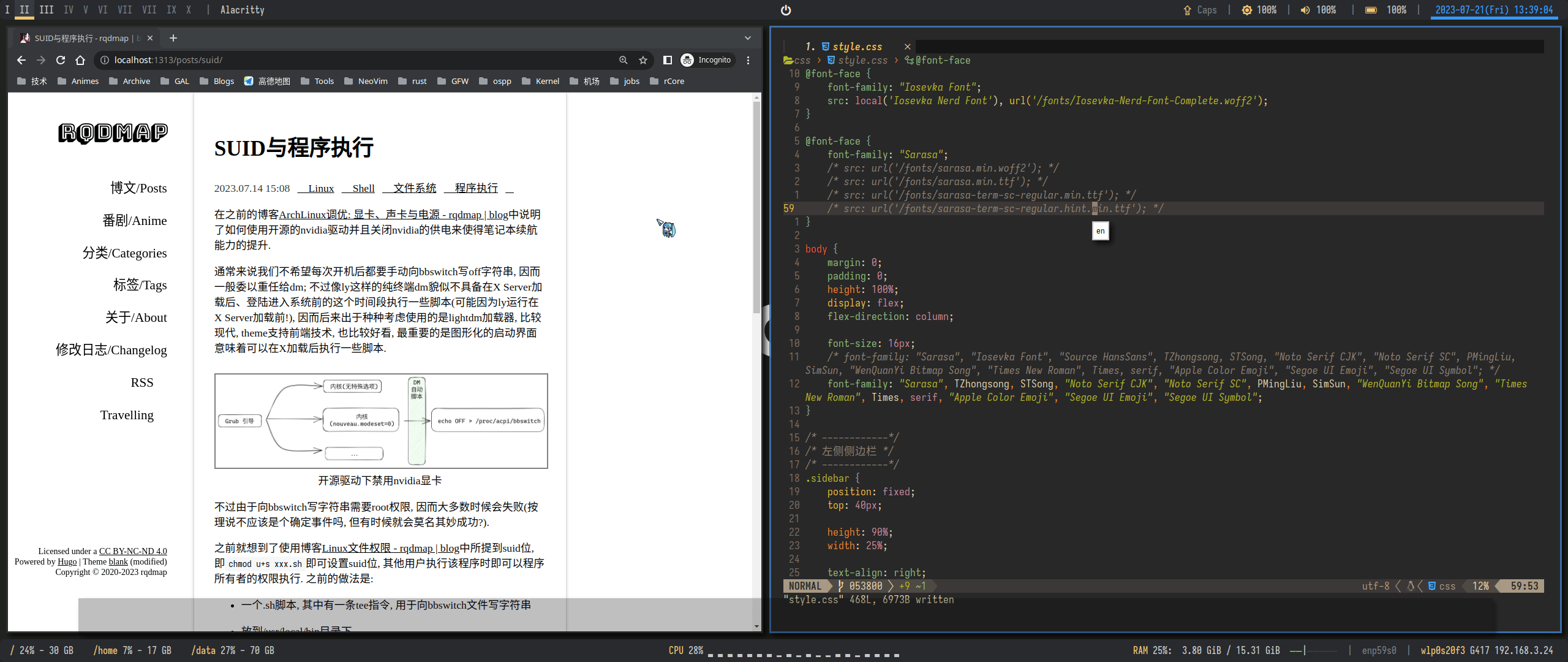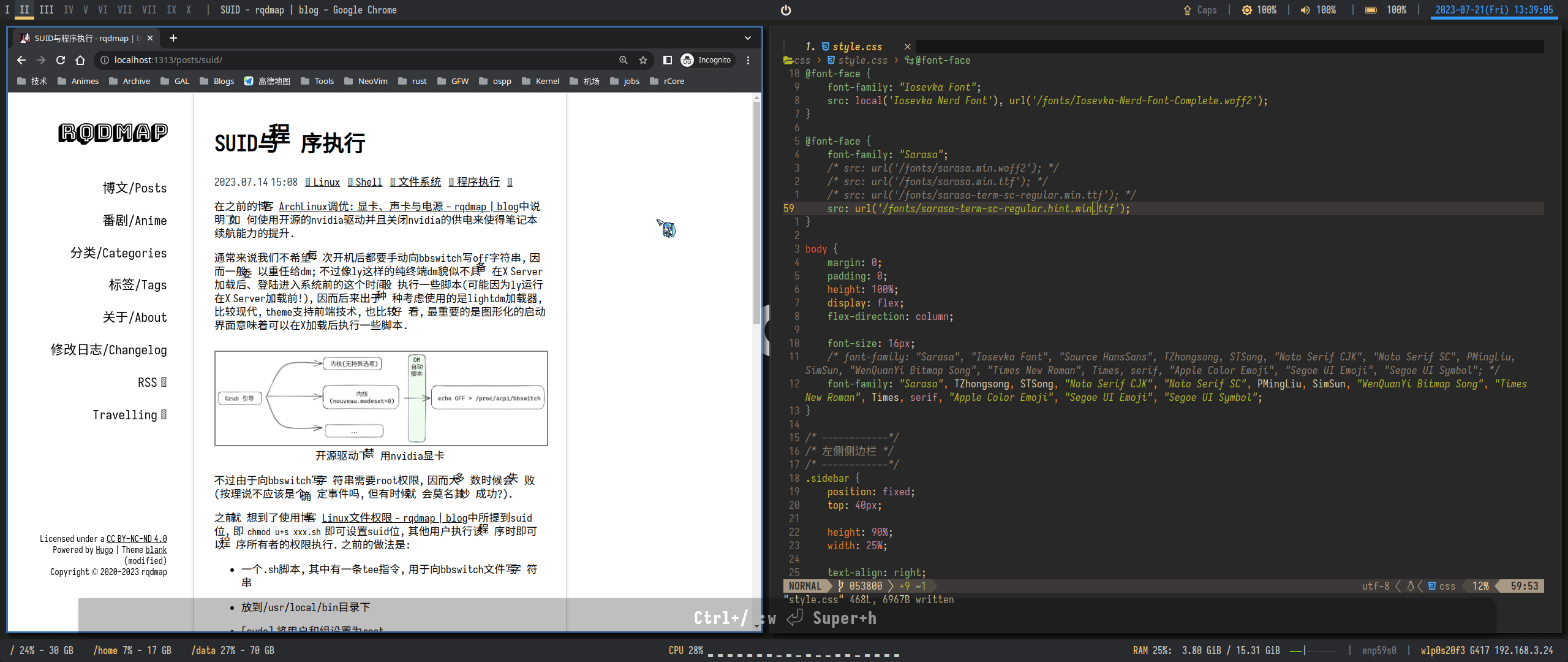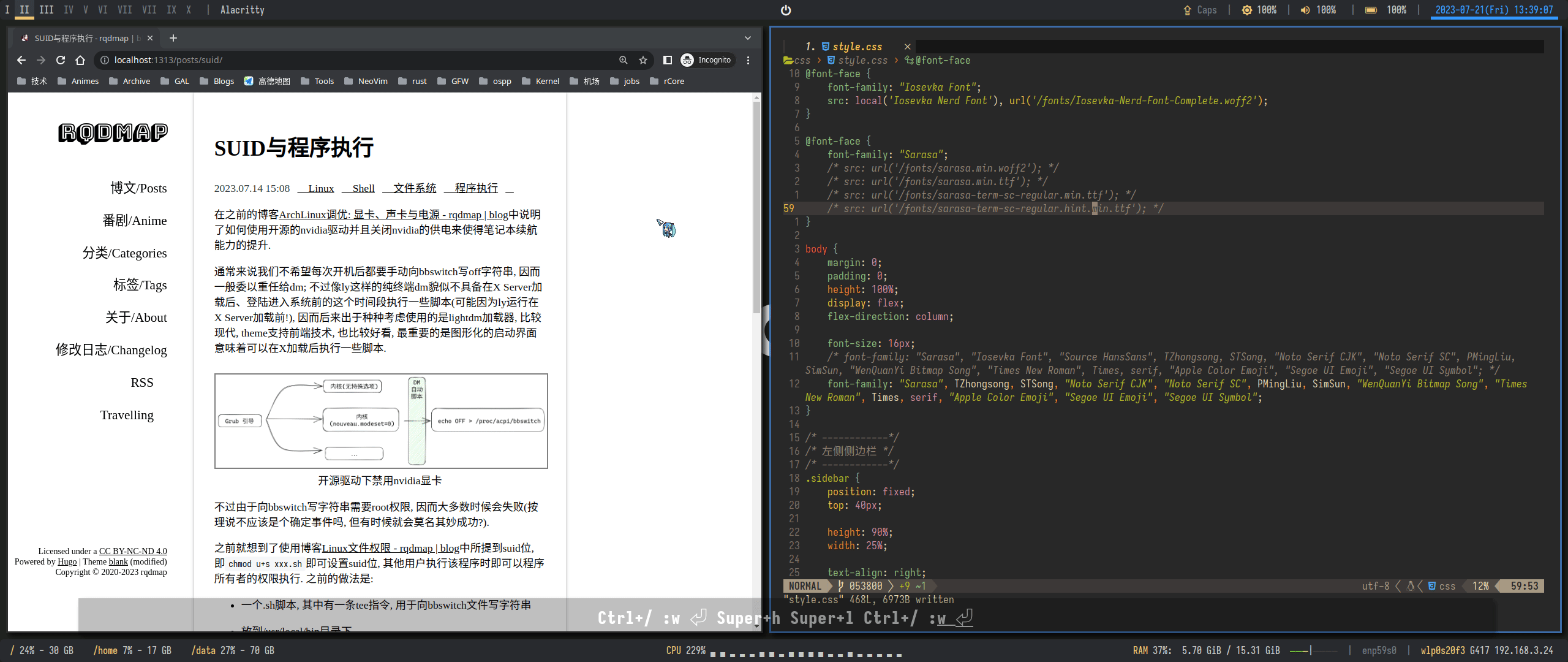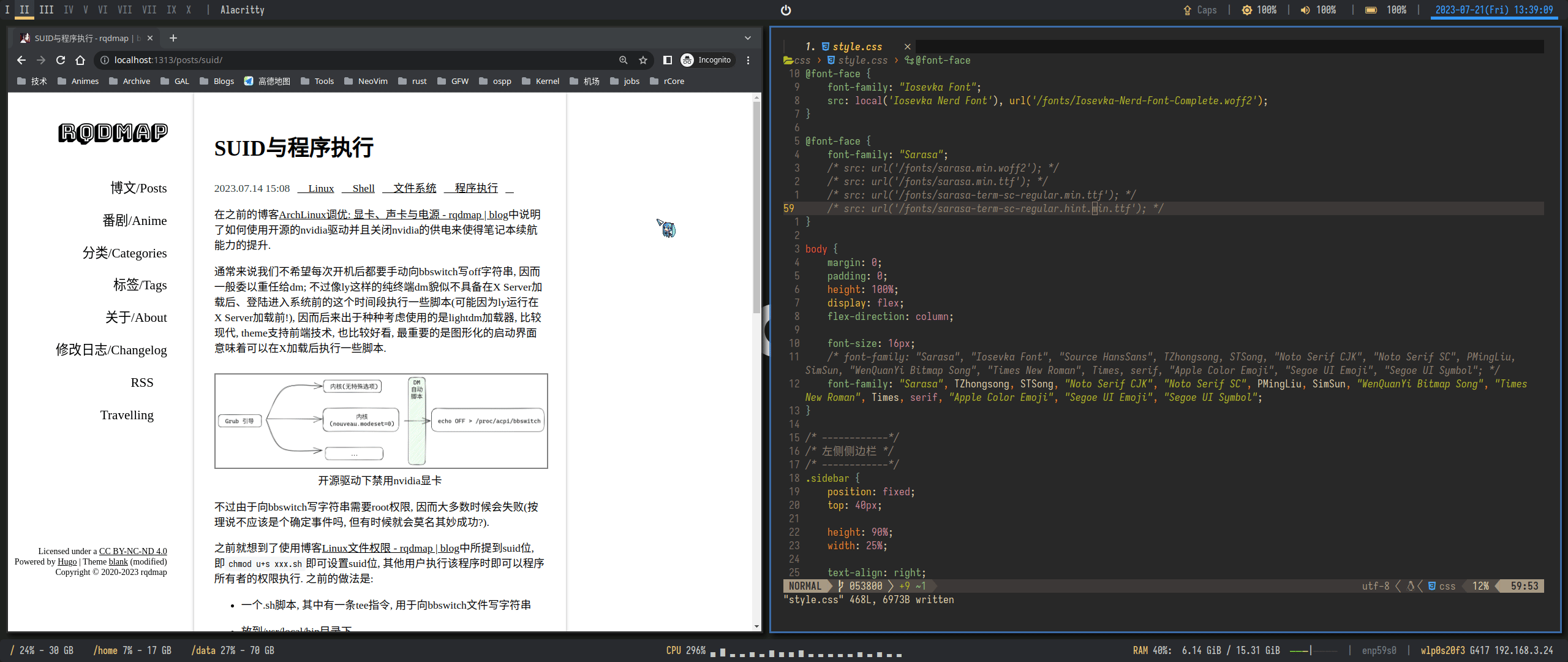
随意一调整hinting: false后居然就可以了! 而且看上去好像没有坏多少, 令人满意
还有一个问题是nerdfont. 正如上面的gif展示的, nerdfont全部变成豆腐了, 如何加入nerdfont字体呢?
nerdfont本质上貌似是对已有的字体包打补丁, 在一些没有被使用的编码上塞入一些icon这类, 所以我之前一直使用的iosevka-nerd-font其实就是这样搞出来的. 对于一些小众的字体, 并未有一些预先打上nerdfont补丁的字体包, 但官方给出了一种自己打包的方式: ryanoasis / nerd-fonts.
还需要安装fontforge, 之前貌似装过, 觉得太简朴了删了, 这会试用了下发现简才是真, 效果很好.

执行nerdfont的patcher指令:
1#!/bin/zsh
2./font-patcher --fontawesome --fontawesome --fontawesomeextension --fontlogos --octicons --codicons --powersymbols --pomicons --powerline --powerlineextra --material --weather ../fonts/sarasa-term-sc-regular.ttf打补丁的过程有一大堆Error/Warning,,让人一度怀疑是不是要失败了..:
1The glyph named ellipsis is mapped to U+EA7C.
2But its name indicates it should be mapped to U+2026.
3The glyph named heart is mapped to U+EB05.
4But its name indicates it should be mapped to U+2665.
5The glyph named home is mapped to U+EB06.
6...
7Lookup subtable contains unused glyph POWER making the whole subtable invalid
8Lookup subtable contains unused glyph POWER making the whole subtable invalid
9Lookup subtable contains unused glyph POWER making the whole subtable invalid
10Lookup subtable contains unused glyph POWER making the whole subtable invalid抛开过程不谈, 使用fontforge查看patch后的字体, 发现出现了很多的icon font! 那么就认为是成功了, 直接使用吧!
将处理好的塞到博客中, 非常的完美, 几乎看不出来和之前的有什么区别
那么我们获得了多大的改良呢? 使用woff2_compress压缩ttf为woff2格式, 最终可以达到生成一个包含中西文, nerdfont的269K的字体包! 这几乎是处理前的10%了, 字体压缩取得了优秀的效果!
部署自动化脚本
尽管整个一套下来流程看上去比较复杂, 但是计算机正精通于处理流程固定的事:)
将该流程其加入博客的部署流程中即可, 大约只会增加2-3s的操作时间, 十分的快速
