页框管理
尽管奔腾处理器允许采取两种不同大小的页框:4KB和4MB(PAE被激活则是2MB),但是Linux采用4KB页框大小作为基本分配单元,基于两个原因:
-
由分页单元引发的缺页异常很容易得到解释:或者是页无权访问,或者是页不存在。在后一种情况下,内存分配器仅仅需要找到一个4KB空闲页框分配给进程。
-
虽然4KB和4MB都是磁盘块大小的倍数,但是更小的数据块传输往往更高效。
页描述符
内核必须记录每个页框的状态,这类信息被存放在类型为page的页描述符中。
1/*
2 * Each physical page in the system has a struct page associated with
3 * it to keep track of whatever it is we are using the page for at the
4 * moment. Note that we have no way to track which tasks are using
5 * a page.
6 */
7struct page {
8 page_flags_t flags; /* Atomic flags, some possibly
9 * updated asynchronously */
10 atomic_t _count; /* Usage count, see below. */
11 atomic_t _mapcount; /* Count of ptes mapped in mms,
12 * to show when page is mapped
13 * & limit reverse map searches.
14 */
15 unsigned long private; /* Mapping-private opaque data:
16 * usually used for buffer_heads
17 * if PagePrivate set; used for
18 * swp_entry_t if PageSwapCache
19 * When page is free, this indicates
20 * order in the buddy system.
21 */
22 struct address_space *mapping; /* If low bit clear, points to
23 * inode address_space, or NULL.
24 * If page mapped as anonymous
25 * memory, low bit is set, and
26 * it points to anon_vma object:
27 * see PAGE_MAPPING_ANON below.
28 */
29 pgoff_t index; /* Our offset within mapping. */
30 struct list_head lru; /* Pageout list, eg. active_list
31 * protected by zone->lru_lock !
32 */
33 /*
34 * On machines where all RAM is mapped into kernel address space,
35 * we can simply calculate the virtual address. On machines with
36 * highmem some memory is mapped into kernel virtual memory
37 * dynamically, so we need a place to store that address.
38 * Note that this field could be 16 bits on x86 ... ;)
39 *
40 * Architectures with slow multiplication can define
41 * WANT_PAGE_VIRTUAL in asm/page.h
42 */
43#if defined(WANT_PAGE_VIRTUAL)
44 void *virtual; /* Kernel virtual address (NULL if
45 not kmapped, ie. highmem) */
46#endif /* WANT_PAGE_VIRTUAL */
47};其中:
-
_count字段为页的引用计数器。如果值为-1,意味着相应页框空闲,而大于等于0则意味着页框被分配给了一个或多个进程,或存放一些内核数据结构。page_cout()函数返回_count加1后的值,也就是页使用者的数量。 -
flags包含多个用来描述页框状态的标志。对于每个PG_xyz标志,内核都定义了一些操作宏。通常,PageXyz返回标志的值,而SetPageXyz和ClearPageXyz分别设置和清除相应的位。


所有的也描述符都被存放在mem_map数组中, 因为每个描述符长度为32 bytes, 所以mem_map需要的空间略小于整个RAM的1%(32字节的描述符可以描述4096字节的页框).
非统一内存访问(NUMA)
习惯上我们认为计算机内存是一种均匀、共享的资源,不管CPU位于何处,CPU对于内存单元的访问都需要的相同的时间。可惜,这种假设并不总是成立。
Linux2.6支持非统一内存访问模型,在这种模型中,给定CPU对不同内存单元的访问时间可能不同。物理内存被划分为几个节点(node),在一个节点内,任一给定CPU访问页面的时间都是相同的,但是对于不同CPU而言这个时间可能就不同。对于每个CPU,内核都试图把耗时节点的访问次数最少,这就要小心选择CPU最常使用的内核数据结构的存放位置。
每个节点都有一个类型为pg_data_t的描述符: (GFP全称为Get-Free-Page)
1/*
2 * The pg_data_t structure is used in machines with CONFIG_DISCONTIGMEM
3 * (mostly NUMA machines?) to denote a higher-level memory zone than the
4 * zone denotes.
5 *
6 * On NUMA machines, each NUMA node would have a pg_data_t to describe
7 * it's memory layout.
8 *
9 * Memory statistics and page replacement data structures are maintained on a
10 * per-zone basis.
11 */
12struct bootmem_data;
13typedef struct pglist_data {
14 struct zone node_zones[MAX_NR_ZONES];
15 struct zonelist node_zonelists[GFP_ZONETYPES];
16 int nr_zones;
17 struct page *node_mem_map;
18 struct bootmem_data *bdata;
19 unsigned long node_start_pfn;
20 unsigned long node_present_pages; /* total number of physical pages */
21 unsigned long node_spanned_pages; /* total size of physical page
22 range, including holes */
23 int node_id;
24 struct pglist_data *pgdat_next;
25 wait_queue_head_t kswapd_wait;
26 struct task_struct *kswapd;
27 int kswapd_max_order;
28} pg_data_t;所有的节点都放在一个单向链表中,第一个元素由pgdat_list变量指向。
在x86结构中使用统一访问内存(UMA)模型,因此并不真正需要NUMA的支持; 然而,即使NUMA的支持没有编译进内核,Linux还是为了兼容性使用节点,不过此时是一个单独的节点,包含了系统中所有的物理内存。因此此时,pgdat_list指向一个链表,该链表中仅有一个元素构成,这个元素是节点0的描述符,存放在contig_page_data变量中。
内存管理区
在理想的计算机系统中,一个页框可以干任何事情,任何种类的数据页都可以存放在任何页框中。
但是实际的计算机体系有硬件的约束,在8086结构下有两种约束:
-
ISA总线的DMA处理器只能对RAM的前16MB寻址
-
在具有大容量RAM的32位机器上,受限于线性地址空间太小,CPU不能直接访问所有的物理内存
为了应对这两种约束,Linux2.6把内存节点的物理内存划分为3个管理区(zone)。在80x86体系结构中的管理区为:
-
ZONE_DMA: 低于16MB的内核页框 -
ZONE_NORMAL: 高于16MB且低于896MB的内存页框 -
ZONE_HIGHMEM: 高于896MB的内存页框
DMA区域的页框可以由老式基于ISA的设备通过DMA使用。
前两个区域被线性地映射到线性地址空间的第4个GB,内核就可以进行直接访问; 相反,第三个区域的内存不能由内核直接访问,尽管他们也线性地映射到了线性地址空间的第4个GB(参见后续的 高端内存页框的内核映射)。在64位体系结构上,ZONE_HIGHMEM总是空的。
每个内存管理区都有自己的描述符,存储在include/linux/mmzone.h中,描述符中拥有许多字段用于回收页框,相关内容在第十七章描述。




为了节省空间,每个页描述符都将指向内存节点和节点内管理区的链接存放在flags字段的高位。由于描述页框的标志位是有限的,因而通过高位来白那么特定的内存节点和管理区号是可能的。
1#define MAX_NR_ZONES 3 /* Sync this with ZONES_SHIFT */
2#define ZONES_SHIFT 2 /* ceil(log2(MAX_NR_ZONES)) */
3
4#define NODEZONE_SHIFT (sizeof(page_flags_t)*8 - MAX_NODES_SHIFT - MAX_ZONES_SHIFT)
5
6struct zone;
7extern struct zone *zone_table[];
8
9static inline struct zone *page_zone(struct page *page)
10{
11 return zone_table[page->flags >> NODEZONE_SHIFT];
12}page_zone函数接受一个页描述符,读取flags字段的高位内容,然后通过查看zone_table数组来确定对应的管理区描述符地址。在系统启动时所有的内存节点的所有管理区都将用来初始化这个数组。
当内核调用内存分配函数时,必须指名请求页框所在的管理区。内核通过使用zonelist数据结构来表明其愿意使用什么管理区,该结构即为管理区描述符指针的数组。
保留的页框池
当请求内存时,如果没有足够的空闲内存,那么必须回收一些内存,并且将发起请求的内核控制路径阻塞,直到有空闲内存。但是一些内核控制路径不能被阻塞,比如在处理中断或是执行临界区代码时。在这种情况下,内核控制路径应该使用原子内存分配请求(使用GFP_ATOMIC标志),原子请求从不阻塞,只会失败。
尽管无法保证原子内存分配从不失败,但是内核通过为其保留一个页框池来尽可能减少失败的概率。页框池仅在内存不足时使用。
保留内存的数量存放在min_free_kbytes变量中,其初值在内核初始化时决定,并取决于直接映射到内核线性空间的物理内存的数量(即取决于ZONE_DMA和ZONE_NORMAL区的页框数量):
$$ \textrm{保留池的大小}=\lfloor \sqrt{16*\textrm{直接映射内存}}\rfloor \left(KB\right) $$
同时,该值不能小于128也不能大于65536。
ZONE_DMA和ZONE_NORMAL按照各自两者的大小比例成比例地贡献自己的页框给页框池。
管理区描述符的pages_min字段存储了区内保留页框的数目,在第十七章将看到该字段与pages_low,pages_high一同在页框回收中发挥作用。这两个值是回收页框的上下界,也被管理区分配器作为阈值使用,默认的值分别是pages_min的5/4和3/2。
需要区分一下管理区描述符中的lowmem_reserve和pages_min. lowmen_reserve是一个数组, 记录了当前管理区的内存可以分配多少给更高级的管理区, 而pages_min则完全就是保留页框池的参数, 记录了页框池中页框的数量:
1/*
2 * setup_per_zone_lowmem_reserve - called whenever
3 * sysctl_lower_zone_reserve_ratio changes. Ensures that each zone
4 * has a correct pages reserved value, so an adequate number of
5 * pages are left in the zone after a successful __alloc_pages().
6 */
7static void setup_per_zone_lowmem_reserve(void)
8{
9 struct pglist_data *pgdat;
10 int j, idx;
11
12 for_each_pgdat(pgdat) {
13 for (j = 0; j < MAX_NR_ZONES; j++) {
14 struct zone * zone = pgdat->node_zones + j;
15 unsigned long present_pages = zone->present_pages;
16
17 zone->lowmem_reserve[j] = 0;
18
19 for (idx = j-1; idx >= 0; idx--) {
20 struct zone * lower_zone = pgdat->node_zones + idx;
21
22 lower_zone->lowmem_reserve[j] = present_pages / sysctl_lowmem_reserve_ratio[idx];
23 present_pages += lower_zone->present_pages;
24 }
25 }
26 }
27}
28
29/*
30 * setup_per_zone_pages_min - called when min_free_kbytes changes. Ensures
31 * that the pages_{min,low,high} values for each zone are set correctly
32 * with respect to min_free_kbytes.
33 */
34static void setup_per_zone_pages_min(void)
35{
36 unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
37 unsigned long lowmem_pages = 0;
38 struct zone *zone;
39 unsigned long flags;
40
41 /* Calculate total number of !ZONE_HIGHMEM pages */
42 for_each_zone(zone) {
43 if (!is_highmem(zone))
44 lowmem_pages += zone->present_pages;
45 }
46
47 for_each_zone(zone) {
48 spin_lock_irqsave(&zone->lru_lock, flags);
49 if (is_highmem(zone)) {
50 /*
51 * Often, highmem doesn't need to reserve any pages.
52 * But the pages_min/low/high values are also used for
53 * batching up page reclaim activity so we need a
54 * decent value here.
55 */
56 int min_pages;
57
58 min_pages = zone->present_pages / 1024;
59 if (min_pages < SWAP_CLUSTER_MAX)
60 min_pages = SWAP_CLUSTER_MAX;
61 if (min_pages > 128)
62 min_pages = 128;
63 zone->pages_min = min_pages;
64 } else {
65 /* if it's a lowmem zone, reserve a number of pages
66 * proportionate to the zone's size.
67 */
68 zone->pages_min = (pages_min * zone->present_pages) /
69 lowmem_pages;
70 }
71
72 /*
73 * When interpreting these watermarks, just keep in mind that:
74 * zone->pages_min == (zone->pages_min * 4) / 4;
75 */
76 zone->pages_low = (zone->pages_min * 5) / 4;
77 zone->pages_high = (zone->pages_min * 6) / 4;
78 spin_unlock_irqrestore(&zone->lru_lock, flags);
79 }
80}
81
82static int __init init_per_zone_pages_min(void)
83{
84 unsigned long lowmem_kbytes;
85
86 lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
87
88 min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
89 if (min_free_kbytes < 128)
90 min_free_kbytes = 128;
91 if (min_free_kbytes > 65536)
92 min_free_kbytes = 65536;
93 setup_per_zone_pages_min();
94 setup_per_zone_lowmem_reserve();
95 return 0;
96}分区页框分配器
管理区分配器接受动态内存的分配和释放的请求,在每个管理区内,页框被名为伙伴系统的部分来处理。为了达到更好的系统性能,一小部分页框被保留在高速缓存中(参考 每CPU页框高速缓存)。
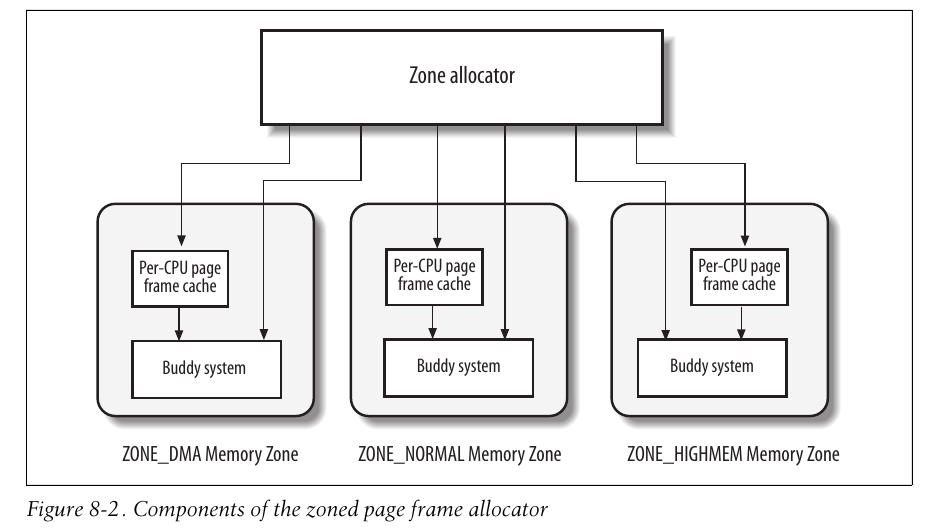
请求页框
可以通过6个稍有差别函数or宏来请求页框:
1/*
2 * UMA模型
3 */
4#define alloc_pages(gfp_mask, order) \
5 alloc_pages_node(numa_node_id(), gfp_mask, order)
6
7#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
8
9/*
10 * Common helper functions.
11 */
12fastcall unsigned long __get_free_pages(unsigned int gfp_mask, unsigned int order)
13{
14 struct page * page;
15 page = alloc_pages(gfp_mask, order);
16 if (!page)
17 return 0;
18 return (unsigned long) page_address(page);
19}
20
21#define __get_free_page(gfp_mask) \
22 __get_free_pages((gfp_mask),0)
23
24#define __get_dma_pages(gfp_mask, order) \
25 __get_free_pages((gfp_mask) | GFP_DMA,(order))
26
27fastcall unsigned long get_zeroed_page(unsigned int gfp_mask)
28{
29 struct page * page;
30
31 /*
32 * get_zeroed_page() returns a 32-bit address, which cannot represent
33 * a highmem page
34 */
35 BUG_ON(gfp_mask & __GFP_HIGHMEM);
36
37 page = alloc_pages(gfp_mask | __GFP_ZERO, 0);
38 if (page)
39 return (unsigned long) page_address(page);
40 return 0;
41}alloc_pages函数返回的是页框描述符的地址,而__get_free_pages则返回线性地址。
参数gfp_mask是一组标志,指明了如何寻找空闲的页框:

另外也有一组组合标志:
1/* if you forget to add the bitmask here kernel will crash, period */
2#define GFP_LEVEL_MASK (__GFP_WAIT|__GFP_HIGH|__GFP_IO|__GFP_FS| \
3 __GFP_COLD|__GFP_NOWARN|__GFP_REPEAT| \
4 __GFP_NOFAIL|__GFP_NORETRY|__GFP_NO_GROW|__GFP_COMP)
5
6#define GFP_ATOMIC (__GFP_HIGH)
7#define GFP_NOIO (__GFP_WAIT)
8#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
9#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
10#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS)
11#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HIGHMEM)分配页框的核心函数是__alloc_pages,存在于mm/page_alloc.c中。由于涉及到伙伴算法等其余知识,因而后续再进行详细说明。
释放页框
有4个函数or宏可以释放页框:
1fastcall void __free_pages(struct page *page, unsigned int order)
2{
3 if (!PageReserved(page) && put_page_testzero(page)) {
4 if (order == 0)
5 free_hot_page(page);
6 else
7 __free_pages_ok(page, order);
8 }
9}
10
11fastcall void free_pages(unsigned long addr, unsigned int order)
12{
13 if (addr != 0) {
14 BUG_ON(!virt_addr_valid((void *)addr));
15 __free_pages(virt_to_page((void *)addr), order);
16 }
17}
18
19#define __free_page(page) __free_pages((page), 0)
20#define free_page(addr) free_pages((addr),0)页框释放的算法也留至后续进行介绍。
高端内存页框的内核映射
直接映射内存的末端、高端内存的起始端对应的线性地址存放在high_memory变量中,它被设置为896MB。
由于高端内存页框并不映射到内核线性空间,因此内核不能访问他们,这也就意味着,返回线性地址的分配器函数不适用于高端内存。在64位架构中就不存在这样的问题,因为可寻址的线性空间远大于真实的RAM大小,因而这些架构下ZONE_HIGHMEN管理区总是空的。
在8086体系下,Linux采用如下方法:
-
高端内存页框只能通过
alloc_pages函数和alloc_page进行分配。这些函数返回的是页描述符的线性地址,这些地址总是存在的,因为一旦所有的页描述符被分配在低端内存中,内核初始化阶段中就不会再改变它。 -
没有线性地址的高端内存页框不能被内核访问,因此内核线性地址空间的最后128MB中有一部分专门用于映射这类页框。这种映射是暂时的,内核重复使用这些线性地址来访问高端内存,这也意味着内核没有办法同时对整个RAM寻址。
内核使用三种机制来将页框映射到高端内存: 永久内核映射、临时内核映射以及非连续内存分配。
当没有空闲页表项时,建立永久内核映射可能阻塞当前进程,因而不能在中断处理、可延迟程序中使用。
临时内核映射则要求内核控制路径永远不能被阻塞,不然其他的内核控制路径可能会使用同一个窗口来映射其他的高端内存页。
非连续内存分配将在稍后的小节( 非连续内存区管理)进行讨论.
永久内核映射
永久内核映射允许建立高端页框到内核地址的长期映射。其使用主内核页表中一个专门的表项,地址存放在pkmap_page_table中,表项数由LAST_PKMAP产生,根据是否激活PAE分别为512和1024项,因而最多寻址2MB和4MB.
该页表映射的高端线性地址从PKMAP_BASE开始.
1/*
2 * Ordering is:
3 *
4 * FIXADDR_TOP
5 * fixed_addresses
6 * FIXADDR_START
7 * temp fixed addresses
8 * FIXADDR_BOOT_START
9 * Persistent kmap area
10 * PKMAP_BASE
11 * VMALLOC_END
12 * Vmalloc area
13 * VMALLOC_START
14 * high_memory
15 */
16#define PKMAP_BASE ( (FIXADDR_BOOT_START - PAGE_SIZE*(LAST_PKMAP + 1)) & PMD_MASK )pkmap_count数组是一个"计数器", 页表中的每一项都有一个值:
1/*
2* Virtual_count is not a pure "count".
3* 0 means that it is not mapped, and has not been mapped
4* since a TLB flush - it is usable.
5* 1 means that there are no users, but it has been mapped
6* since the last TLB flush - so we can't use it.
7* n means that there are (n-1) current users of it.
8*/
9static int pkmap_count[LAST_PKMAP];为了记录高端内存页框和永久内核映射包含的线性地址的关系, 内核使用page_address_htable散列表, 该表包含page_address_map数据结构:
1/*
2 * Describes one page->virtual association
3 */
4struct page_address_map {
5 struct page *page;
6 void *virtual;
7 struct list_head list;
8};page_address()函数返回页框对应的线性地址:
1static inline unsigned long hash_ptr(void *ptr, unsigned int bits)
2{
3 return hash_long((unsigned long)ptr, bits);
4}
5
6
7/*
8 * Hash table bucket
9 */
10static struct page_address_slot {
11 struct list_head lh; /* List of page_address_maps */
12 spinlock_t lock; /* Protect this bucket's list */
13} ____cacheline_aligned_in_smp page_address_htable[1<<PA_HASH_ORDER];
14
15static struct page_address_slot *page_slot(struct page *page)
16{
17 return &page_address_htable[hash_ptr(page, PA_HASH_ORDER)];
18}
19
20void *page_address(struct page *page)
21{
22 unsigned long flags;
23 void *ret;
24 struct page_address_slot *pas;
25
26 if (!PageHighMem(page))
27 return lowmem_page_address(page);
28
29 pas = page_slot(page);
30 ret = NULL;
31 spin_lock_irqsave(&pas->lock, flags);
32 if (!list_empty(&pas->lh)) {
33 struct page_address_map *pam;
34
35 list_for_each_entry(pam, &pas->lh, list) {
36 if (pam->page == page) {
37 ret = pam->virtual;
38 goto done;
39 }
40 }
41 }
42done:
43 spin_unlock_irqrestore(&pas->lock, flags);
44 return ret;
45}kmap()函数用于建立永久内核映射:
1void *kmap(struct page *page)
2{
3 might_sleep();
4 if (!PageHighMem(page))
5 return page_address(page);
6 return kmap_high(page);
7}如果页框为高端内存, 则调用kmap_high函数:
1void fastcall *kmap_high(struct page *page)
2{
3 unsigned long vaddr;
4
5 /*
6 * For highmem pages, we can't trust "virtual" until
7 * after we have the lock.
8 *
9 * We cannot call this from interrupts, as it may block
10 */
11 spin_lock(&kmap_lock);
12 vaddr = (unsigned long)page_address(page);
13 if (!vaddr)
14 vaddr = map_new_virtual(page);
15 pkmap_count[PKMAP_NR(vaddr)]++;
16 if (pkmap_count[PKMAP_NR(vaddr)] < 2)
17 BUG();
18 spin_unlock(&kmap_lock);
19 return (void*) vaddr;
20}注意:
-
该函数通过自旋锁保护页表不被多处理器系统并发访问, 但是没有必要禁止中断, 这是因为中断处理程序和可延迟的函数不能调用kmap().
-
如果page尚未被映射, 那么调用map_new_virtual:
c1static inline unsigned long map_new_virtual(struct page *page) 2{ 3 unsigned long vaddr; 4 int count; 5 6start: 7 count = LAST_PKMAP; 8 /* Find an empty entry */ 9 for (;;) { 10 last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK; 11 if (!last_pkmap_nr) { 12 flush_all_zero_pkmaps(); 13 count = LAST_PKMAP; 14 } 15 if (!pkmap_count[last_pkmap_nr]) 16 break; /* Found a usable entry */ 17 if (--count) 18 continue; 19 20 /* 21 * Sleep for somebody else to unmap their entries 22 */ 23 { 24 DECLARE_WAITQUEUE(wait, current); 25 26 __set_current_state(TASK_UNINTERRUPTIBLE); 27 add_wait_queue(&pkmap_map_wait, &wait); 28 spin_unlock(&kmap_lock); 29 schedule(); 30 remove_wait_queue(&pkmap_map_wait, &wait); 31 spin_lock(&kmap_lock); 32 33 /* Somebody else might have mapped it while we slept */ 34 if (page_address(page)) 35 return (unsigned long)page_address(page); 36 37 /* Re-start */ 38 goto start; 39 } 40 } 41 vaddr = PKMAP_ADDR(last_pkmap_nr); 42 set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot)); 43 44 pkmap_count[last_pkmap_nr] = 1; 45 set_page_address(page, (void *)vaddr); 46 47 return vaddr; 48} 49 50 51#define PKMAP_ADDR(nr) (PKMAP_BASE + ((nr) << PAGE_SHIFT))-
函数执行循环, 搜索可用的页表项(即pkmap_count计数器为0). 当搜索到结尾后仍然未找到, 则阻塞当前进程(L23-L38), 直到某个其余进程释放了一个表项后(参考下面的kunmap函数), 当前进程再恢复执行. 这里有个问题, 为何引入count计数器. 经过仔细考虑…L17为假的情况当且仅当
LAST_PKMAP页表没有任何一项空闲, 那么last_pkmap_nr递增一次, count就会递减一次, 最终才可能运行到阻塞当前进程的代码段…那为何不引入一个flag就行了?… 或许是考虑到未来的重利用? 事实上在最新版的内核(5.18.15)中都保留着几乎一样的代码, 那么可能是我naive了, 不过我并不知道为什么要这样做. -
当
last_pkmap_nr重新从0开始搜索时, 首先需要调用flush_all_zero_pkmaps函数对页表进行一趟扫描, 将其中计数器为1的表项(空闲, 但不能使用)设置为0, 同时删除page_address_htable散列表中的元素以及刷新TLB. -
当搜索到一个空闲的表项后, 为其在
pkmap_page_table页表中创建项, 设置计数器为1, 同时通过set_page_address函数将其插入到散列表中.
这样, 对高端内存寻址的整体流程应该如下: (在此之前是否还有步骤? 通过页描述符还是什么进行访问?) 当内核希望访问某个高端页框时, 首先通过
page_address函数返回页描述符的线性地址(通过查找散列表, 对应L45), 即以PKMAP_BASE为基地址的若干偏移(对应L41); 然后对该线性地址的访问请求会发送到分页单元, 分页单元通过查看页表pkmap_page_table(对应L42), 正确读取页描述符的内容. 通过描述符链接指向的节点和区域信息, 计算描述符地址与zone_mem_map的差值, 再加上zone_start_pfn后即可得到该描述符对应的实际页框号, 最终访问到物理地址?.. -
-
kmap_high函数将计数器加1, 将调用该函数的新内核成分考虑在内.
-
最后释放自旋锁, 返回对该物理页映射后的线性地址.
kunmap用于撤销由kmap建立的永久内核映射:
1void kunmap(struct page *page)
2{
3 if (in_interrupt())
4 BUG();
5 if (!PageHighMem(page))
6 return;
7 kunmap_high(page);
8}
9
10#define PKMAP_NR(virt) ((virt-PKMAP_BASE) >> PAGE_SHIFT)
11
12void fastcall kunmap_high(struct page *page)
13{
14 unsigned long vaddr;
15 unsigned long nr;
16 int need_wakeup;
17
18 spin_lock(&kmap_lock);
19 vaddr = (unsigned long)page_address(page);
20 if (!vaddr)
21 BUG();
22 nr = PKMAP_NR(vaddr);
23
24 /*
25 * A count must never go down to zero
26 * without a TLB flush!
27 */
28 need_wakeup = 0;
29 switch (--pkmap_count[nr]) {
30 case 0:
31 BUG();
32 case 1:
33 /*
34 * Avoid an unnecessary wake_up() function call.
35 * The common case is pkmap_count[] == 1, but
36 * no waiters.
37 * The tasks queued in the wait-queue are guarded
38 * by both the lock in the wait-queue-head and by
39 * the kmap_lock. As the kmap_lock is held here,
40 * no need for the wait-queue-head's lock. Simply
41 * test if the queue is empty.
42 */
43 need_wakeup = waitqueue_active(&pkmap_map_wait);
44 }
45 spin_unlock(&kmap_lock);
46
47 /* do wake-up, if needed, race-free outside of the spin lock */
48 if (need_wakeup)
49 wake_up(&pkmap_map_wait);
50}计数器减1后如果等于1, 意味着当前没有进程正在使用该页, 那么该页表项可以分配给其余正在等待唤醒的进程(回收kmap中map_new_virtual函数的伏笔).
临时内核映射
临时内核映射比永久内核映射简单, 而且他们可以用在中断处理和可延迟函数的内部, 因为它们从不阻塞.
高端内存的任一页框都可以通过窗口映射到内核地址空间, 但是留给临时内核映射的窗口非常少, 每个CPU仅有13个窗口:
1enum km_type {
2D(0) KM_BOUNCE_READ,
3D(1) KM_SKB_SUNRPC_DATA,
4D(2) KM_SKB_DATA_SOFTIRQ,
5D(3) KM_USER0,
6D(4) KM_USER1,
7D(5) KM_BIO_SRC_IRQ,
8D(6) KM_BIO_DST_IRQ,
9D(7) KM_PTE0,
10D(8) KM_PTE1,
11D(9) KM_IRQ0,
12D(10) KM_IRQ1,
13D(11) KM_SOFTIRQ0,
14D(12) KM_SOFTIRQ1,
15D(13) KM_TYPE_NR
16};内核必须保证同一个窗口不会被两个而不同的控制路径同时使用.
最后一个符号本身并不表示一个线性地址, 而是用来产生不同的窗口数. enum fixed_addresses结构包含FIX_KMAP_BEGIN和FIX_KMAP_END, 通过KM_TYPE_NR来进行若干计算得到FIX_KMAP_END.
1#ifdef CONFIG_HIGHMEM
2 FIX_KMAP_BEGIN, /* reserved pte's for temporary kernel mappings */
3 FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1,
4#endif内核通过fix_to_virt(FIX_KMAP_BEGIN)返回的线性地址对应的页表项来初始化kmap_pte变量.
这里多看一下fix_to_virt函数, 它是一个将固定地址的索引转化为实际的地址的函数:
1#define __FIXADDR_TOP 0xfffff000
2#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
3#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
4
5/*
6 * 'index to address' translation. If anyone tries to use the idx
7 * directly without tranlation, we catch the bug with a NULL-deference
8 * kernel oops. Illegal ranges of incoming indices are caught too.
9 */
10static __always_inline unsigned long fix_to_virt(const unsigned int idx)
11{
12 /*
13 * this branch gets completely eliminated after inlining,
14 * except when someone tries to use fixaddr indices in an
15 * illegal way. (such as mixing up address types or using
16 * out-of-range indices).
17 *
18 * If it doesn't get removed, the linker will complain
19 * loudly with a reasonably clear error message..
20 */
21 if (idx >= __end_of_fixed_addresses)
22 __this_fixmap_does_not_exist();
23
24 return __fix_to_virt(idx);
25}其中:
-
__end_of_fixed_addresses是enum fixed_addresses结构的最后一项, 该枚举结构具体的内容可能随着内核编译选项的变化而变化, 固定映射可以加快内存的访问速度, 每一项的线性地址从4GB开始往回递减, 不予深究具体细节, 注释所言:Text1/* 2* Here we define all the compile-time 'special' virtual 3* addresses. The point is to have a constant address at 4* compile time, but to set the physical address only 5* in the boot process. We allocate these special addresses 6* from the end of virtual memory (0xfffff000) backwards. 7* Also this lets us do fail-safe vmalloc(), we 8* can guarantee that these special addresses and 9* vmalloc()-ed addresses never overlap. 10* 11* these 'compile-time allocated' memory buffers are 12* fixed-size 4k pages. (or larger if used with an increment 13* highger than 1) use fixmap_set(idx,phys) to associate 14* physical memory with fixmap indices. 15* 16* TLB entries of such buffers will not be flushed across 17* task switches. 18*/ -
该函数总是声明为
inline, 因而C编译程序不调用该函数, 而是仅仅将其代码插入到调用处, 并且运行时从不对这个索引进行检查. 因而, 由于实际在调用该函数时索引值总是一个常量(枚举类型的元素), 编译器可以直接去掉if判断; 而如果输入有误, 则编译器会在连接阶段直接产生一个错误. 十分的精妙. -
为了将物理地址和固定映射的线性地址对应起来, 内核使用
set_fixmap(idx, phys)宏和set_fixmap_nocache(idx, phys). 这两个函数都会将对应的页表项初始化化为物理地址phys, 但是第二个函数也会把页表项的PCD标志置位从而禁用硬件高速缓存; 而撤销连接关系, 则调用clear_fixmap(idx)宏.c1#define set_fixmap(idx, phys) \ 2 __set_fixmap(idx, phys, PAGE_KERNEL) 3/* 4* Some hardware wants to get fixmapped without caching. 5*/ 6#define set_fixmap_nocache(idx, phys) \ 7 __set_fixmap(idx, phys, PAGE_KERNEL_NOCACHE) 8 9#define clear_fixmap(idx) \ 10 __set_fixmap(idx, 0, __pgprot(0))
回到临时内核映射, 为了建立一个这样的映射, 内核调用kmap_atomic函数:
1/*
2 * kmap_atomic/kunmap_atomic is significantly faster than kmap/kunmap because
3 * no global lock is needed and because the kmap code must perform a global TLB
4 * invalidation when the kmap pool wraps.
5 *
6 * However when holding an atomic kmap is is not legal to sleep, so atomic
7 * kmaps are appropriate for short, tight code paths only.
8 */
9void *kmap_atomic(struct page *page, enum km_type type)
10{
11 enum fixed_addresses idx;
12 unsigned long vaddr;
13
14 /* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */
15 inc_preempt_count();
16 if (!PageHighMem(page))
17 return page_address(page);
18
19 idx = type + KM_TYPE_NR*smp_processor_id();
20 vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
21#ifdef CONFIG_DEBUG_HIGHMEM
22 if (!pte_none(*(kmap_pte-idx)))
23 BUG();
24#endif
25 set_pte(kmap_pte-idx, mk_pte(page, kmap_prot));
26 __flush_tlb_one(vaddr);
27
28 return (void*) vaddr;
29}其中:
-
idx根据CPU标识符和type进行偏移, 指定对应的虚拟地址 -
kmap_prot字段最终被设置为初始化的_PAGE_KERNEL, 设置对应的页表项标志位:
1#define _PAGE_KERNEL \
2 (_PAGE_PRESENT | _PAGE_RW | _PAGE_DIRTY | _PAGE_ACCESSED | _PAGE_NX)为了撤销临时内核映射, 内核使用kunmap_atomic函数.
1void kunmap_atomic(void *kvaddr, enum km_type type)
2{
3 dec_preempt_count();
4 preempt_check_resched();
5}这里preempt_count似乎有妙用, 好像涉及到irq的相关知识, 留坑.
伙伴系统算法
内核为了分配一组连续的页框, 应该建立一种健壮, 高效的分配策略, 因而必须解决外碎片问题.
从本质上说, 解决外碎片有2种办法:
-
利用分页单元把一组分连续的页框映射到连续的线性地址空间
-
开发一种适当的技术, 记录现存的空闲且连续的页框块情况, 以尽量避免为了满足小块的请求而分割大的空闲块.
Linux采用第二种方法, 基于以下的几点原因:
-
在某些情况下, 需要连续的页框. 一个典型的例子是给DMA处理器分配缓冲区的请求(参考第十三章), 因为再一次单独的IO操作中传输几个扇区的数据时DMA忽略分页单元热直接访问地址总线, 因此所请求的缓冲区就必须在连续的页框中.
-
连续页框在保持内核页表不变方面也起到作用, 因为频繁地修改页表会导致CPU频繁刷新TLB导致平均访问内存的次数增加.
-
内核可以通过4MB的页访问大块连续的内存, 减少TLB的失效率, 提高访问内存的平均速度.
Linux采用伙伴系统(buddy system)来解决外碎片问题: 把所有的空闲页框分组为11个块链表, 每个块链表分别包含$2^i(i=0,1,…,10)$个连续的页框. 每个块第一个页框的物理地址是该块大小的整数倍.
当尝试分配一个大小为$2^i$的块时, 首先检查对应大小的块链表中是否存在空闲块, 若没有, 则向更大的块$2^{i+1}$迭代, 一旦找到一个更大的块后, 将需求大小的块分配给内核, 并将残余的部分按照对应大小分配回链表.
当两个块: 大小相同(设为$b$), 物理地址连续且第一块的第一个页框物理地址是$2 \times b \times 2^{12}$的倍数, 那么这两个块就被称为伙伴. 页框块的释放过程中, 伙伴块会不断迭代并向上合并.
数据结构
Linux2.6为每个管理区都使用不同的伙伴系统, 因此在x86体系中有3种管理系统, 每种管理系统使用的主要数据结构如下:
mem_map数组. 实际上每个管理区都只是使用该数组的一个子集, 根据zone_mem_map和size字段指定第一个元素和元素的个数.(没找到size…)
1struct page *zone_mem_map;- 包含11个类型为
free_area的数组free_area, 其中free_list是双向循环链表的头, 该链表将页描述符的lru字段连接在一起. 此外, 一个$2^k$大小的页块的第一个页描述符中,private字段将会存放块的order(即$k$). 正是由于这个字段, 当页块被释放时内核可以确定这个块的伙伴是否空闲. 而当页正在被使用时,lru和private字段就会被用于其他目的.
1struct free_area {
2 struct list_head free_list;
3 unsigned long nr_free;
4};
5
6struct free_area free_area[MAX_ORDER];分配块
__rmqueue函数用来在管理区找到空闲块, 其接受两个参数: 管理区描述符地址zone和空闲块大小的对数值order.
1/*
2 * Do the hard work of removing an element from the buddy allocator.
3 * Call me with the zone->lock already held.
4 */
5static struct page *__rmqueue(struct zone *zone, unsigned int order)
6{
7 struct free_area * area;
8 unsigned int current_order;
9 struct page *page;
10
11 for (current_order = order; current_order < MAX_ORDER; ++current_order) {
12 area = zone->free_area + current_order;
13 if (list_empty(&area->free_list))
14 continue;
15
16 page = list_entry(area->free_list.next, struct page, lru);
17 list_del(&page->lru);
18 rmv_page_order(page);
19 area->nr_free--;
20 zone->free_pages -= 1UL << order;
21 return expand(zone, page, order, current_order, area);
22 }
23
24 return NULL;
25}其中:
-
该函数假设调用者已经禁用了本地中断, 并且获得了伙伴系统的
zone->lock自旋锁. -
rmv_page_order函数清除
PG_private标志位, 将private字段清零;PG_private标志代表着描述符中的private的字段是否有意义.
1#define __ClearPagePrivate(page) __clear_bit(PG_private, &(page)->flags)
2
3static inline void rmv_page_order(struct page *page)
4{
5 __ClearPagePrivate(page);
6 page->private = 0;
7}- expand函数执行最终的分配操作, 从大页块往小遍历, size在每轮遍历时直接作为偏移量, 将对应页描述符的
private字段进行设置, 十分的优美.
1static inline static inline void set_page_order(struct page *page, int order) {
2 page->private = order;
3 __SetPagePrivate(page);
4}
5
6struct page *
7expand(struct zone *zone, struct page *page,
8 int low, int high, struct free_area *area)
9{
10 unsigned long size = 1 << high;
11
12 while (high > low) {
13 area--;
14 high--;
15 size >>= 1;
16 BUG_ON(bad_range(zone, &page[size]));
17 list_add(&page[size].lru, &area->free_list);
18 area->nr_free++;
19 set_page_order(&page[size], high);
20 }
21 return page;
22}释放块
__free_pages_bulk函数按照伙伴系统释放页框.
1static inline void __free_pages_bulk (struct page *page, struct page *base,
2 struct zone *zone, unsigned int order)
3{
4 unsigned long page_idx;
5 struct page *coalesced;
6 int order_size = 1 << order;
7
8 if (unlikely(order))
9 destroy_compound_page(page, order);
10
11 page_idx = page - base;
12
13 BUG_ON(page_idx & (order_size - 1));
14 BUG_ON(bad_range(zone, page));
15
16 zone->free_pages += order_size;
17 while (order < MAX_ORDER-1) {
18 struct free_area *area;
19 struct page *buddy;
20 int buddy_idx;
21
22 buddy_idx = (page_idx ^ (1 << order));
23 buddy = base + buddy_idx;
24 if (bad_range(zone, buddy))
25 break;
26 if (!page_is_buddy(buddy, order))
27 break;
28 /* Move the buddy up one level. */
29 list_del(&buddy->lru);
30 area = zone->free_area + order;
31 area->nr_free--;
32 rmv_page_order(buddy);
33 page_idx &= buddy_idx;
34 order++;
35 }
36 coalesced = base + page_idx;
37 set_page_order(coalesced, order);
38 list_add(&coalesced->lru, &zone->free_area[order].free_list);
39 zone->free_area[order].nr_free++;
40}-
函数假设调用者已经禁用本地汇总段并获得了
zone->lock自旋锁. -
base参数本质上就是zone参数的zone_mem_map字段, 将它也作为参数传递进来是出于性能的考虑. -
destroy_compound_page函数处理扩展分页机制下的页框:
1#ifndef CONFIG_HUGETLB_PAGE
2#define PageCompound(page) 0
3#define destroy_compound_page(page, order) do { } while (0)
4
5#else
6#define PageCompound(page) test_bit(PG_compound, &(page)->flags)
7static void destroy_compound_page(struct page *page, unsigned long order)
8{
9 int i;
10 int nr_pages = 1 << order;
11
12 if (!PageCompound(page))
13 return;
14
15 if (page[1].index != order)
16 bad_page(__FUNCTION__, page);
17
18 for (i = 0; i < nr_pages; i++) {
19 struct page *p = page + i;
20
21 if (!PageCompound(p))
22 bad_page(__FUNCTION__, page);
23 if (p->private != (unsigned long)page)
24 bad_page(__FUNCTION__, page);
25 ClearPageCompound(p);
26 }
27}
28#endif /* CONFIG_HUGETLB_PAGE */-
伙伴下标的获得(L22): 通过与基地址相减, 得到当前页描述符的偏移序号
page_idx, 随后直接对该序号在1<<order上进行一次异或即可得到伙伴下标, 与算法竞赛中链式前向星获得双向边有异曲同工之妙. 其中, 能够直接通过相对于基地址的偏移来进行页描述符和下标的转换(L11, 23)也是得益于页框的连续性. -
随后再通过2个判断分支检测运算得到的伙伴下标是否合法:
1/*
2 * Temporary debugging check for pages not lying within a given zone.
3 */
4static int bad_range(struct zone *zone, struct page *page)
5{
6 if (page_to_pfn(page) >= zone->zone_start_pfn + zone->spanned_pages)
7 return 1;
8 if (page_to_pfn(page) < zone->zone_start_pfn)
9 return 1;
10#ifdef CONFIG_HOLES_IN_ZONE
11 if (!pfn_valid(page_to_pfn(page)))
12 return 1;
13#endif
14 if (zone != page_zone(page))
15 return 1;
16 return 0;
17}
18
19/*
20 * This function checks whether a page is free && is the buddy
21 * we can do coalesce a page and its buddy if
22 * (a) the buddy is free &&
23 * (b) the buddy is on the buddy system &&
24 * (c) a page and its buddy have the same order.
25 * for recording page's order, we use page->private and PG_private.
26 *
27 */
28static inline int page_is_buddy(struct page *page, int order)
29{
30 if (PagePrivate(page) &&
31 (page_order(page) == order) &&
32 !PageReserved(page) &&
33 page_count(page) == 0)
34 return 1;
35 return 0;
36}-
在每一轮循环结束后, 应当修改page指针为当前页块第一个页描述符的指针; 在伙伴系统中其实就是将
1<<order位清零, 代码中采用了优美的page_idx &= buddy_idx即可达到目的. -
循环跳出后, 将最终合并而成的大块的相应信息进行更新即可.
每CPU页框高速缓存
内核经常请求和释放单个页框. 为了提升系统性能, 每个内存管理区都定义了一个每CPU页框高速缓存, 这些缓存中包含一些预先分配的页框.
实际上, 每个内存管理区和CPU提供了两个高速缓存: 热高速缓存(其存放的页框内容很可能就在CPU的硬件Cache中 Q: 那什么时候不在?); 冷高速缓存.
如果内核or用户态进程在刚分配到页框后就向其写, 那么热高速缓存会更加有利; 而如果页框将要被DMA填充, 这种情况下不涉及到CPU, cache不会被修改, 从冷高速缓存中获得页框就可以为其他类型的内存分配保留热页框.
实现这种缓存主要通过管理区类型为per_cpu_pageset的数组pageset[NR_CPUS]实现:
1struct per_cpu_pages {
2 int count; /* number of pages in the list */
3 int low; /* low watermark, refill needed */
4 int high; /* high watermark, emptying needed */
5 int batch; /* chunk size for buddy add/remove */
6 struct list_head list; /* the list of pages */
7};
8
9struct per_cpu_pageset {
10 struct per_cpu_pages pcp[2]; /* 0: hot. 1: cold */
11#ifdef CONFIG_NUMA
12 unsigned long numa_hit; /* allocated in intended node */
13 unsigned long numa_miss; /* allocated in non intended node */
14 unsigned long numa_foreign; /* was intended here, hit elsewhere */
15 unsigned long interleave_hit; /* interleaver prefered this zone */
16 unsigned long local_node; /* allocation from local node */
17 unsigned long other_node; /* allocation from other node */
18#endif
19} ____cacheline_aligned_in_smp;我们不过多关注NUMA架构下的数据结构, 因而主要关注pcp[2]字段和per_cpu_pages结构. 内核通过low, high来监视冷热cache的大小: 页框数量count < low时, 内核从伙伴系统中分配batch个单一页框来补充cache; count > high时,内核从cache中释放batch个页框到伙伴系统中.
分配页框
buffered_rmqueue()函数在指定的内存管理区中分配页框, 它将使用per-cpu页框高速缓存来处理单一页框的请求.
1/*
2 * Really, prep_compound_page() should be called from __rmqueue_bulk(). But
3 * we cheat by calling it from here, in the order > 0 path. Saves a branch
4 * or two.
5 */
6static struct page *
7buffered_rmqueue(struct zone *zone, int order, int gfp_flags)
8{
9 unsigned long flags;
10 struct page *page = NULL;
11 int cold = !!(gfp_flags & __GFP_COLD);
12
13 if (order == 0) {
14 struct per_cpu_pages *pcp;
15
16 pcp = &zone->pageset[get_cpu()].pcp[cold];
17 local_irq_save(flags);
18 if (pcp->count <= pcp->low)
19 pcp->count += rmqueue_bulk(zone, 0,
20 pcp->batch, &pcp->list);
21 if (pcp->count) {
22 page = list_entry(pcp->list.next, struct page, lru);
23 list_del(&page->lru);
24 pcp->count--;
25 }
26 local_irq_restore(flags);
27 put_cpu();
28 }
29
30 if (page == NULL) {
31 spin_lock_irqsave(&zone->lock, flags);
32 page = __rmqueue(zone, order);
33 spin_unlock_irqrestore(&zone->lock, flags);
34 }
35
36 if (page != NULL) {
37 BUG_ON(bad_range(zone, page));
38 mod_page_state_zone(zone, pgalloc, 1 << order);
39 prep_new_page(page, order);
40
41 if (gfp_flags & __GFP_ZERO)
42 prep_zero_page(page, order, gfp_flags);
43
44 if (order && (gfp_flags & __GFP_COMP))
45 prep_compound_page(page, order);
46 }
47 return page;
48}-
__GFP_COLD标志代表是否请求的是一个冷页, 而!!将非零映射到1, 不改变原数值的布尔含义, 因而cold最终取值只可能为0或1;pcp根据cold的结果选取冷热页对应的数据结构. -
如果
pcp->count <= pcp->low, 那么需要往缓存中补充页框, 通过rmqueue_bulk函数:c1/* 2* Obtain a specified number of elements from the buddy allocator, all under 3* a single hold of the lock, for efficiency. Add them to the supplied list. 4* Returns the number of new pages which were placed at *list. 5*/ 6static int rmqueue_bulk(struct zone *zone, unsigned int order, 7 unsigned long count, struct list_head *list) 8{ 9 unsigned long flags; 10 int i; 11 int allocated = 0; 12 struct page *page; 13 14 spin_lock_irqsave(&zone->lock, flags); 15 for (i = 0; i < count; ++i) { 16 page = __rmqueue(zone, order); 17 if (page == NULL) 18 break; 19 allocated++; 20 list_add_tail(&page->lru, list); 21 } 22 spin_unlock_irqrestore(&zone->lock, flags); 23 return allocated; 24}容易发现, 该函数进行多次单页面的分配, 将分配到的页面插入到cache链表中. 函数返回实际分配到的页框数, 因而在上层
buffered_rmqueue函数中用该返回值更新count字段. -
如果此时每CPU-Cache中存在空闲页, 将其取出并更新count字段即可.(可能存在分配失败的情况, cache中没有空闲页, rmqueue_bulk也没有成功补充页框)
-
随后将处理非单一页框(order>0)的分配和上述步骤中单一页框失败分配的情况, 尝试调用
__rmqueue从伙伴系统中分配需要的页框. -
如果内存请求得到满足, 函数就将初始化页块第一个页框的描述符, 清除一些标志, 清零
private字段, 设置页框引用计数器为1. 并根据gfp_flags对页框进行额外的一些操作. -
最终, 返回页块中第一个页框的描述符地址, 分配失败则返回NULL.
释放页框
为了释放单个页框到每CPU页框高速缓存, 内核使用free_hot_page和free_cold_page.
1void fastcall free_hot_page(struct page *page)
2{
3 free_hot_cold_page(page, 0);
4}
5
6void fastcall free_cold_page(struct page *page)
7{
8 free_hot_cold_page(page, 1);
9}它们本质上都是对free_hot_cold_page函数的简单封装:
1static void fastcall free_hot_cold_page(struct page *page, int cold)
2{
3 struct zone *zone = page_zone(page);
4 struct per_cpu_pages *pcp;
5 unsigned long flags;
6
7 arch_free_page(page, 0);
8
9 kernel_map_pages(page, 1, 0);
10 inc_page_state(pgfree);
11 if (PageAnon(page))
12 page->mapping = NULL;
13 free_pages_check(__FUNCTION__, page);
14 pcp = &zone->pageset[get_cpu()].pcp[cold];
15 local_irq_save(flags);
16 if (pcp->count >= pcp->high)
17 pcp->count -= free_pages_bulk(zone, pcp->batch, &pcp->list, 0);
18 list_add(&page->lru, &pcp->list);
19 pcp->count++;
20 local_irq_restore(flags);
21 put_cpu();
22}-
该函数首先通过page_zone从页描述符找到对应的管理区描述符地址, 源码详见 内存管理区
-
x86体系没有实现arch_free_page, kernel_map_pages好像是调试用函数, 都不予深究.
-
inc_page_state的参数pgfree是一个关于页的全局计数器, 记录了空闲页的总数目, 其定义在了struct page_state结构(include/linux/page-flags.h)中. 而该函数本身则是对该计数器加一, 实现方式为:
1void __mod_page_state(unsigned offset, unsigned long delta)
2{
3 unsigned long flags;
4 void* ptr;
5
6 local_irq_save(flags);
7 ptr = &__get_cpu_var(page_states);
8 *(unsigned long*)(ptr + offset) += delta;
9 local_irq_restore(flags);
10}
11
12#define mod_page_state(member, delta) \
13 __mod_page_state(offsetof(struct page_state, member), (delta))
14#define inc_page_state(member) mod_page_state(member, 1UL)-
PageAnon涉及到匿名映射, 参考第十七章, 这里不详细展开.
-
free_pages_check检查页框是否确实是空闲可回收的, 并检查若干标志位和清除脏位.
1static inline void free_pages_check(const char *function, struct page *page)
2{
3 if ( page_mapped(page) ||
4 page->mapping != NULL ||
5 page_count(page) != 0 ||
6 (page->flags & (
7 1 << PG_lru |
8 1 << PG_private |
9 1 << PG_locked |
10 1 << PG_active |
11 1 << PG_reclaim |
12 1 << PG_slab |
13 1 << PG_swapcache |
14 1 << PG_writeback )))
15 bad_page(function, page);
16 if (PageDirty(page))
17 ClearPageDirty(page);
18}- pcp根据cold的值选择对应的冷热页链表, 首先检查是否有
pcp->count >= pcp->high, 如果结果为真则调用free_pages_bulk回收一部分高速缓存页框到伙伴系统中:
1/*
2 * Frees a list of pages.
3 * Assumes all pages on list are in same zone, and of same order.
4 * count is the number of pages to free, or 0 for all on the list.
5 *
6 * If the zone was previously in an "all pages pinned" state then look to
7 * see if this freeing clears that state.
8 *
9 * And clear the zone's pages_scanned counter, to hold off the "all pages are
10 * pinned" detection logic.
11 */
12static int
13free_pages_bulk(struct zone *zone, int count,
14 struct list_head *list, unsigned int order)
15{
16 unsigned long flags;
17 struct page *base, *page = NULL;
18 int ret = 0;
19
20 base = zone->zone_mem_map;
21 spin_lock_irqsave(&zone->lock, flags);
22 zone->all_unreclaimable = 0;
23 zone->pages_scanned = 0;
24 while (!list_empty(list) && count--) {
25 page = list_entry(list->prev, struct page, lru);
26 /* have to delete it as __free_pages_bulk list manipulates */
27 list_del(&page->lru);
28 __free_pages_bulk(page, base, zone, order);
29 ret++;
30 }
31 spin_unlock_irqrestore(&zone->lock, flags);
32 return ret;
33}-
其中
all_unreclaimable字段标志着管理内充满了不可回收的页,pages_scanned字段为回收页框时使用的计数器. -
调用__free_pages_bulk将空闲页插入到伙伴系统中, 由于伙伴系统会处理链表的插入, 因而此时应该从链表中删去既有的page->lru.
需要注意, Linux2.6内核从不将页框释放到冷高速缓存中, 内核总是假设被释放的页框是热的. 但这并不意味着冷高速缓存是空的, 因而buffered_rmqueue会补充该高速缓存.
管理区分配器
管理区分配器必须分配一个包含足够多空闲页框的内存区满足内存请求, 这并不简单, 因为其必须满足几个目标:
-
其应当保护保留的页框池
-
当内存不足且允许阻塞当前进程时, 其应当触发页框回收算法, 并再次分配
-
尽可能保存小而珍贵的
ZONE_DMA管理区
分配页框
正如我们在
请求页框看到的, 对一组页框的请求实质上是调用__alloc_pages函数, 现在我们将对该核心函数进行详细的说明:
1/*
2 * This is the 'heart' of the zoned buddy allocator.
3 */
4struct page * fastcall
5__alloc_pages(unsigned int gfp_mask, unsigned int order,
6 struct zonelist *zonelist)
7{
8 const int wait = gfp_mask & __GFP_WAIT;
9 struct zone **zones, *z;
10 struct page *page;
11 struct reclaim_state reclaim_state;
12 struct task_struct *p = current;
13 int i;
14 int classzone_idx;
15 int do_retry;
16 int can_try_harder;
17 int did_some_progress;
18
19 might_sleep_if(wait);
20
21 /*
22 * The caller may dip into page reserves a bit more if the caller
23 * cannot run direct reclaim, or is the caller has realtime scheduling
24 * policy
25 */
26 can_try_harder = (unlikely(rt_task(p)) && !in_interrupt()) || !wait;
27
28 zones = zonelist->zones; /* the list of zones suitable for gfp_mask */
29
30 if (unlikely(zones[0] == NULL)) {
31 /* Should this ever happen?? */
32 return NULL;
33 }
34
35 classzone_idx = zone_idx(zones[0]);
36
37 restart:
38 /* Go through the zonelist once, looking for a zone with enough free */
39 for (i = 0; (z = zones[i]) != NULL; i++) {
40
41 if (!zone_watermark_ok(z, order, z->pages_low,
42 classzone_idx, 0, 0))
43 continue;
44
45 page = buffered_rmqueue(z, order, gfp_mask);
46 if (page)
47 goto got_pg;
48 }
49
50 for (i = 0; (z = zones[i]) != NULL; i++)
51 wakeup_kswapd(z, order);
52
53 /*
54 * Go through the zonelist again. Let __GFP_HIGH and allocations
55 * coming from realtime tasks to go deeper into reserves
56 */
57 for (i = 0; (z = zones[i]) != NULL; i++) {
58 if (!zone_watermark_ok(z, order, z->pages_min,
59 classzone_idx, can_try_harder,
60 gfp_mask & __GFP_HIGH))
61 continue;
62
63 page = buffered_rmqueue(z, order, gfp_mask);
64 if (page)
65 goto got_pg;
66 }
67
68 /* This allocation should allow future memory freeing. */
69 if (((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE))) && !in_interrupt()) {
70 /* go through the zonelist yet again, ignoring mins */
71 for (i = 0; (z = zones[i]) != NULL; i++) {
72 page = buffered_rmqueue(z, order, gfp_mask);
73 if (page)
74 goto got_pg;
75 }
76 goto nopage;
77 }
78
79 /* Atomic allocations - we can't balance anything */
80 if (!wait)
81 goto nopage;
82
83rebalance:
84 cond_resched();
85
86 /* We now go into synchronous reclaim */
87 p->flags |= PF_MEMALLOC;
88 reclaim_state.reclaimed_slab = 0;
89 p->reclaim_state = &reclaim_state;
90
91 did_some_progress = try_to_free_pages(zones, gfp_mask, order);
92
93 p->reclaim_state = NULL;
94 p->flags &= ~PF_MEMALLOC;
95
96 cond_resched();
97
98 if (likely(did_some_progress)) {
99 /*
100 * Go through the zonelist yet one more time, keep
101 * very high watermark here, this is only to catch
102 * a parallel oom killing, we must fail if we're still
103 * under heavy pressure.
104 */
105 for (i = 0; (z = zones[i]) != NULL; i++) {
106 if (!zone_watermark_ok(z, order, z->pages_min,
107 classzone_idx, can_try_harder,
108 gfp_mask & __GFP_HIGH))
109 continue;
110
111 page = buffered_rmqueue(z, order, gfp_mask);
112 if (page)
113 goto got_pg;
114 }
115 } else if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) {
116 /*
117 * Go through the zonelist yet one more time, keep
118 * very high watermark here, this is only to catch
119 * a parallel oom killing, we must fail if we're still
120 * under heavy pressure.
121 */
122 for (i = 0; (z = zones[i]) != NULL; i++) {
123 if (!zone_watermark_ok(z, order, z->pages_high,
124 classzone_idx, 0, 0))
125 continue;
126
127 page = buffered_rmqueue(z, order, gfp_mask);
128 if (page)
129 goto got_pg;
130 }
131
132 out_of_memory(gfp_mask);
133 goto restart;
134 }
135
136 /*
137 * Don't let big-order allocations loop unless the caller explicitly
138 * requests that. Wait for some write requests to complete then retry.
139 *
140 * In this implementation, __GFP_REPEAT means __GFP_NOFAIL for order
141 * <= 3, but that may not be true in other implementations.
142 */
143 do_retry = 0;
144 if (!(gfp_mask & __GFP_NORETRY)) {
145 if ((order <= 3) || (gfp_mask & __GFP_REPEAT))
146 do_retry = 1;
147 if (gfp_mask & __GFP_NOFAIL)
148 do_retry = 1;
149 }
150 if (do_retry) {
151 blk_congestion_wait(WRITE, HZ/50);
152 goto rebalance;
153 }
154
155nopage:
156 if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) {
157 printk(KERN_WARNING "%s: page allocation failure."
158 " order:%d, mode:0x%x\n",
159 p->comm, order, gfp_mask);
160 dump_stack();
161 }
162 return NULL;
163got_pg:
164 zone_statistics(zonelist, z);
165 return page;
166}-
首先看到的
might_sleep_if用于DEBUG, 当编译参数包含CONFIG_DEBUG_SPINLOCK_SLEEP时才有意义. -
rt_task的全称似乎是real-time task, 该宏有可能是通过进程优先级的比较来判断进程的若干性质, 待学习进程调度后再进行考察; 而
in_interrupt宏则通过进一步调用irq_count宏来判断当前是否处于中断处理的环境中; wait变量标志了页框请求是否允许阻塞当前进程. 当本次分配请求是一个atomic请求时(wait为0),或请求者拥有实时调度策略(?)时就设置can_try_harder变量, 允许内存分配可以访问保留的页框池.c1#define rt_task(p) (unlikely((p)->prio < MAX_RT_PRIO)) 2 3#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK)) 4#define in_interrupt() (irq_count()) -
zone_idx宏将区域转化为其对应类型的序号c1/* 2* zone_idx() returns 0 for the ZONE_DMA zone, 1 for the ZONE_NORMAL zone, etc. 3*/ 4#define zone_idx(zone) ((zone) - (zone)->zone_pgdat->node_zones) -
说明
zone_watermark_ok辅助函数:c1/* 2* Return 1 if free pages are above 'mark'. This takes into account the order 3* of the allocation. 4*/ 5int zone_watermark_ok(struct zone *z, int order, unsigned long mark, 6 int classzone_idx, int can_try_harder, int gfp_high) 7{ 8 /* free_pages my go negative - that's OK */ 9 long min = mark, free_pages = z->free_pages - (1 << order) + 1; 10 int o; 11 12 if (gfp_high) 13 min -= min / 2; 14 if (can_try_harder) 15 min -= min / 4; 16 17 if (free_pages <= min + z->lowmem_reserve[classzone_idx]) 18 return 0; 19 for (o = 0; o < order; o++) { 20 /* At the next order, this order's pages become unavailable */ 21 free_pages -= z->free_area[o].nr_free << o; 22 23 /* Require fewer higher order pages to be free */ 24 min >>= 1; 25 26 if (free_pages <= min) 27 return 0; 28 } 29 return 1; 30}-
如果设置了
gfp_high标志(允许访问页框池)或拥有can_try_harder标志, 则相应的允许水印线更低一些. -
函数检查管理区分配完需求的页框后, 是否仍然含有足够多的空间(即剩余的空间
free_pages高于水印线mark), 具体来说, 它仅在下列两个条件都满足时返回1:-
考虑lowmem_reserve保留的页框后, 剩余空间仍高于水印线
-
对$\forall k=1,\cdots, \textrm{order}$, 所有order不小于k的页块中一共至少还有$min/2^k$个页框.
-
-
mark可能是
pages_{low, min, high}中的任意一个. 调用者通过返回值来得知当前管理区是否满足要求.
-
-
多次遍历
zonelist中每个可选的合适区域.-
第一次水印线初值为
pages_low, 强迫不允许try_harder标志和使用页框池. 如果未找到页, 说明此时内存中没有多少空闲内存了, 函数唤醒kswapd内核线程来异步地回收页框 -
第二次水印线初值降低为
pages_min, 同时允许拥有相应标志的内存请求访问页框池. 如果仍然未找到页, 说明此时系统中内存肯定严重不足. -
如果此时内核控制路径不是一个中断处理函数或可延时的函数, 并且它试图回收页框, 则执行第三次扫描. 这次扫描不考虑水印值, 也只有在这种情况下才允许耗用为内存不足预留的页(对应
lowmem_reserve字段). 这种内核控制路径最终将试图释放页框, 因而只要可能就应该为其分配内存.
-
-
此时仍然没有成功分配内存, 如果当前进程不能被阻塞, 函数就返回NULL提示失败; 不然则开始
rebalance代码段. -
调用
cond_resched函数检查是否有其他的进程需要CPU. -
设置进程的
PF_MEMALLOC标志表明进程做好内存回收的准备了, 随后装载reclaim_state结构到对应的字段中并调用try_to_free_pages寻找一些页框进行回收(参考第十七章内存紧缺回收一节), 该函数可能阻塞当前进程; 一旦函数返回, 就重设当前进程的相关标志并再次调用cond_resched. -
接着检查页框回收是否确实回收了一些页框:
-
如果回收了一些页框, 则再次遍历zonelist, 水线和标志设置与前面步骤中的第二次遍历一致; 如果仍然未找到空闲的页框, 那么函数将决定是否应当继续扫描内存管理区(L143):
-
__GFP_NORETRY标志必须被清零 -
如果设置了
__GFP_REPEAT标志且请求的页框不多于8页, 则重试. -
如果设置了
__GFP_NOFAIL标志, 则重试. -
注意, ULK中认为
__GFP_REPEAT和__GFP_NOFAIL的实现是一样的, 但是在本份代码中的实现是不一样的,__GFP_REPEAT标志意味着对于不超过8页请求的__GFP_NOFAIL标志
-
-
不然, 这意味着内核遇到了麻烦, 空闲页框已经少到了危险的程度, 且无法回收任何页框. 此时将允许内核控制路径杀死一个进程来回收内存, 通过检查是否设置了
__GFP_FS标志(允许依赖文件系统)且未设置__GFP_NORETRY标志(一次失败后不再重试), 再次尝试遍历zonelist, 水印线设置为pages_high, 且强迫不允许try_harder标志和使用页框池. 循环结束后, 会进行一次out_of_memory进程杀死以回收内存, goto跳转到restart代码段, 重新开始尝试分配. 注意, 在这一条件分支中, 首先会运行一次高阈值水印的区域扫描, 由于阈值比前几次的都要高, 因而极容易失败. 只有当另一个内核控制路径已经杀死了一个进程并回收其内存后, 这一步才有可能成功; 因而这一步的存在避免了杀死两个无辜的进程. 这也印证了源码的注释, 当内存压力仍然很大时, 这次分配仍然一定会失败, 但是这样做的目的是为了捕捉一次oom killing.
-
-
对于那些分配失败的将返回NULL, 分配成功的将调用
zone_statistics函数(仅NUMA)后返回页描述符地址.
tips: plka中对于水印进行了一些额外的说明, 现补充说明:

释放页框
同样的, 补充说明
释放页框看到的页框释放算法, 所有的页框释放函数or宏都归结到__free_pages函数, 这里再次引用其函数代码:
1fastcall void __free_pages(struct page *page, unsigned int order)
2{
3 if (!PageReserved(page) && put_page_testzero(page)) {
4 if (order == 0)
5 free_hot_page(page);
6 else
7 __free_pages_ok(page, order);
8 }
9}释放页框的代码远简单于分配页框:
-
检测页框是否拥有
PG_reserved标志(页框留给内核代码或没有使用), 判断其是否真正属于动态内存; 如果不是则终止. -
递减page的引用计数器, 如果仍然大于0则终止.(ULK上说大于或等于0终止, 应该是错误的)
-
如果order为0, 则调用
free_hot_page释放热页. -
不然, 调用__free_pages_ok函数:
c1void __free_pages_ok(struct page *page, unsigned int order) 2{ 3 LIST_HEAD(list); 4 int i; 5 6 arch_free_page(page, order); 7 8 mod_page_state(pgfree, 1 << order); 9 10#ifndef CONFIG_MMU 11 if (order > 0) 12 for (i = 1 ; i < (1 << order) ; ++i) 13 __put_page(page + i); 14#endif 15 16 for (i = 0 ; i < (1 << order) ; ++i) 17 free_pages_check(__FUNCTION__, page + i); 18 list_add(&page->lru, &list); 19 kernel_map_pages(page, 1<<order, 0); 20 free_pages_bulk(page_zone(page), 1, &list, order); 21}-
arch_free_page,mod_page_state和free_pages_check都也已经在 每CPU页框高速缓存-释放页框中进行过说明, 此处不再赘述. -
将
page->lru对应的链表存放在本地链表中, 调用调试函数kernel_map_pages, 最终通过free_pages_bulk函数(同样参考 每CPU页框高速缓存-释放页框)将其释放到合适的伙伴系统中.
-
内存区管理
内存区(memory area), 即为具有连续物理地址和任意长度的内存单元序列.
伙伴系统使用页框作为基本单元, 但对于小内存区的分配请求这显然有点过于浪费了. 正确方法是引用一种新的数据结构来描述同一页框内的小内存区分配方案, 但这也就引出了内碎片的问题.
早期的Linux版本提供按几何分布的内存区大小(即类似于伙伴系统, 提供32, 64, 128,…,131072字节大小共13个的内存区链表), 这种办法可以保证内碎片永远小于50%.
slab分配器
在伙伴算法之上运行内存区分配算法没有显著的效率, 一种更好的算法源自slab分配器模式, 该模式最早用于Sun公式的Solaris2.4操作系统.
该算法基于下列前提:
-
所存放数据的类型可以影响内存区的分配方式. 例如: 给用户态进程分配一个页框时, 内核会调用
get_zeroed_page()清零该页. slab扩充了这种思想, 将内存区看作对象, 每个对象由一组数据结构和构造或析构函数构成. 为了避免重复初始化对象, slab并不丢弃已分配的对象而是将其保存在内存中, 当今后又要请求新的对象时就直接从内存中获取而不需要重新初始化. -
内核函数倾向于反复请求同一类型的内存区. 例如: 只要内核创建一个新进程, 它就一定要为其分配一些固定大小的表(进程描述符, 打开文件对象等等). 当进程结束时, 包含这些表的内存区就可以被保存在高速缓存中被重新使用, 节省反复分配或回收那些在同一页框的内存区.
-
对内存区的请求可以根据其发生频率来分类. 对于预计会被频繁请求的一个特定大小的内存区而言, 可以通过创建一组具有适当大小的专用对象来高效地处理, 并避免内碎片的产生; 另一种情况对于那些很少会遇到的内存区大小则可以通过一系列几何分布大小的对象的分配模式来处理.
-
在引入对象大小不是几何分布的情况下, 可以借助硬件cache获得较好的性能
-
对伙伴系统函数的调用会弄脏硬件cache, 增加了对内存的平均访问时间, 因而应该限制对伙伴系统分配器的调用.
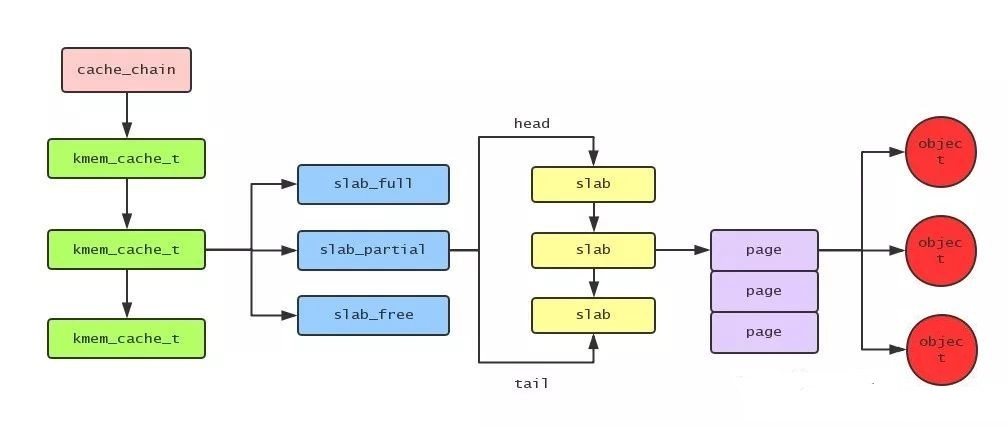
slab分配器将对象分组放进高速缓存, 每个高速缓存都是同种类型对象的一种储备.
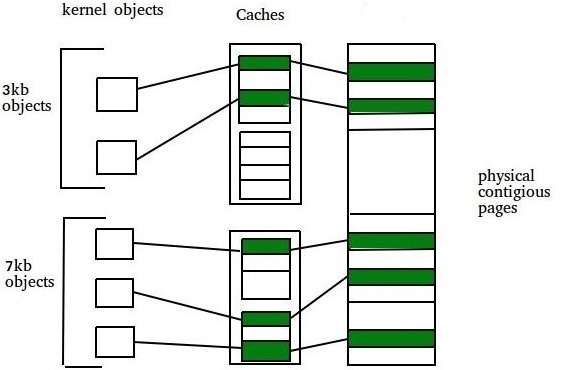
而包含高速缓存的主内存区会被划分为多个slab, 每个slab又由一个或多个连续的页框组成. 这些页框中可能既包含已分配的对象, 也包含空闲的对象.
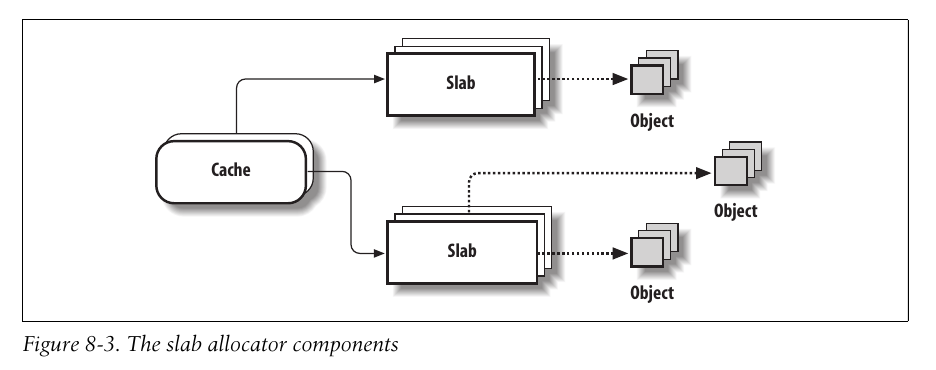
高速缓存描述符
每个高速缓存都有kmem_cache_t类型(等价于kmem_cache_s)的数据结构(存在于mm/slab.c)的描述符, 下表中省去了几个用于收集统计信息的字段.

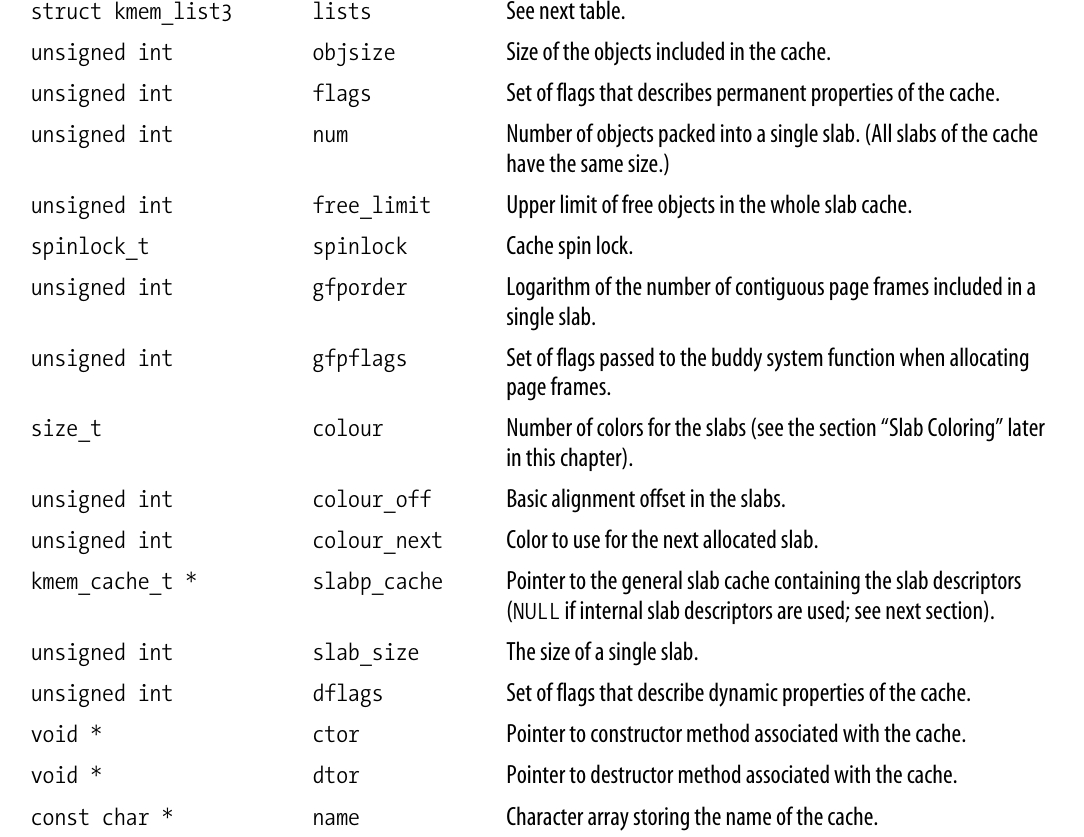
其中, lists字段的类型是kmem_list3结构体:


此外, 补充说明一些slab标志, 在后续的若干函数中将会用到:
1/* flags for kmem_cache_alloc() */
2#define SLAB_NOFS GFP_NOFS
3#define SLAB_NOIO GFP_NOIO
4#define SLAB_ATOMIC GFP_ATOMIC
5#define SLAB_USER GFP_USER
6#define SLAB_KERNEL GFP_KERNEL
7#define SLAB_DMA GFP_DMA
8
9#define SLAB_LEVEL_MASK GFP_LEVEL_MASK
10
11#define SLAB_NO_GROW __GFP_NO_GROW /* don't grow a cache */
12
13/* flags to pass to kmem_cache_create().
14 * The first 3 are only valid when the allocator as been build
15 * SLAB_DEBUG_SUPPORT.
16 */
17#define SLAB_DEBUG_FREE 0x00000100UL /* Peform (expensive) checks on free */
18#define SLAB_DEBUG_INITIAL 0x00000200UL /* Call constructor (as verifier) */
19#define SLAB_RED_ZONE 0x00000400UL /* Red zone objs in a cache */
20#define SLAB_POISON 0x00000800UL /* Poison objects */
21#define SLAB_NO_REAP 0x00001000UL /* never reap from the cache */
22#define SLAB_HWCACHE_ALIGN 0x00002000UL /* align objs on a h/w cache lines */
23#define SLAB_CACHE_DMA 0x00004000UL /* use GFP_DMA memory */
24#define SLAB_MUST_HWCACHE_ALIGN 0x00008000UL /* force alignment */
25#define SLAB_STORE_USER 0x00010000UL /* store the last owner for bug hunting */
26#define SLAB_RECLAIM_ACCOUNT 0x00020000UL /* track pages allocated to indicate
27 what is reclaimable later*/
28#define SLAB_PANIC 0x00040000UL /* panic if kmem_cache_create() fails */
29#define SLAB_DESTROY_BY_RCU 0x00080000UL /* defer freeing pages to RCU */
30
31/* flags passed to a constructor func */
32#define SLAB_CTOR_CONSTRUCTOR 0x001UL /* if not set, then deconstructor */
33#define SLAB_CTOR_ATOMIC 0x002UL /* tell constructor it can't sleep */
34#define SLAB_CTOR_VERIFY 0x004UL /* tell constructor it's a verify call */slab描述符
cache中的每个slab都有自己的类型为slab的描述符:

这个slab描述符可以存放在两个可能的地方:
-
外部描述符: 存放在
cache_sizes指向的一个不适合ISA DMA的普通高速缓存中 -
内部描述符: 存放在分配给slab的页框的起始位置.
当对象小于512MB, 或者内部碎片为slab描述符和对象描述符在slab中留下了足够的空间时, slab分配器会选择第二种方案. 如果slab采用外部存放的方式, 则cache描述符中flags字段中的CFLGS_OFF_SLAB将会被设置.
下图展示了cache描述符和slab描述符之间的联系关系.
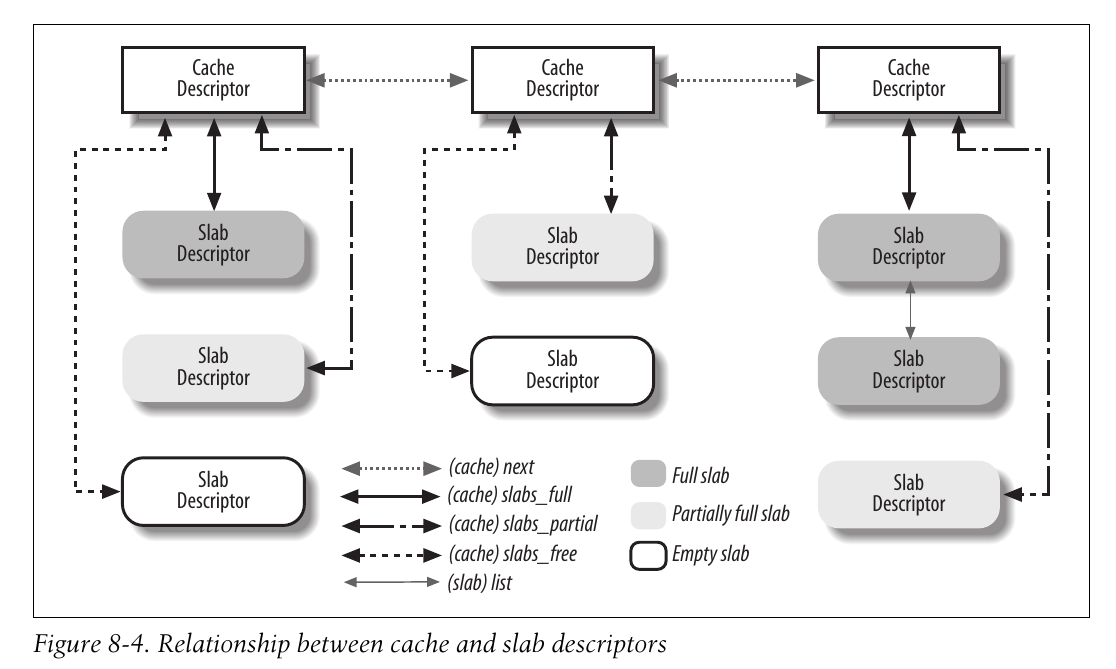
普通和专用高速缓存
cache被分为两种类型: 普通和专用. 普通cache只由slab分配器用于自己的目的, 而专用cache由内核的其余部分使用.
普通高速缓存是:
-
第一个高速缓存叫做
kmem_cache, 包含内核使用的其余cache的描述符,cache_cache变量包含第一个高速缓存的描述符.c1/* internal cache of cache description objs */ 2static kmem_cache_t cache_cache = { 3 .lists = LIST3_INIT(cache_cache.lists), 4 .batchcount = 1, 5 .limit = BOOT_CPUCACHE_ENTRIES, 6 .objsize = sizeof(kmem_cache_t), 7 .flags = SLAB_NO_REAP, 8 .spinlock = SPIN_LOCK_UNLOCKED, 9 .name = "kmem_cache", -
另外一些高速缓存包含用作普通用途的内存区, 内存区大小的范围一般包括13个几何分布的内存区.
系统在初始化期间通过kmem_cache_init()和kmem_cache_sizes_init()(在2.6.11中不存在)来建立普通高速缓存. 前一个函数较为复杂, 这里不予深究.
专用高速缓存由kmem_cache_create创建:
1/**
2 * kmem_cache_create - Create a cache.
3 * @name: A string which is used in /proc/slabinfo to identify this cache.
4 * @size: The size of objects to be created in this cache.
5 * @align: The required alignment for the objects.
6 * @flags: SLAB flags
7 * @ctor: A constructor for the objects.
8 * @dtor: A destructor for the objects.
9 *
10 * Returns a ptr to the cache on success, NULL on failure.
11 * Cannot be called within a int, but can be interrupted.
12 * The @ctor is run when new pages are allocated by the cache
13 * and the @dtor is run before the pages are handed back.
14 *
15 * @name must be valid until the cache is destroyed. This implies that
16 * the module calling this has to destroy the cache before getting
17 * unloaded.
18 *
19 * The flags are
20 *
21 * %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
22 * to catch references to uninitialised memory.
23 *
24 * %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
25 * for buffer overruns.
26 *
27 * %SLAB_NO_REAP - Don't automatically reap this cache when we're under
28 * memory pressure.
29 *
30 * %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
31 * cacheline. This can be beneficial if you're counting cycles as closely
32 * as davem.
33 */
34kmem_cache_t *
35kmem_cache_create (const char *name, size_t size, size_t align,
36 unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
37 void (*dtor)(void*, kmem_cache_t *, unsigned long))这个函数将根据参数确定处理cache的最佳方法(如, 在内部还是外部存放slab描述符), 然后从cache_cache普通cache中分配一个描述符给新的cache, 并将该这个描述符插入到cache_chain链表中.
还可以通过kmem_cache_destroy撤销一个高速缓存并将它从cache_chain链表中移除. 这个函数主要用于模块中, 模块装入时创建cache, 卸载时撤销cache; 为了避免浪费内存, 内核必须要在撤销cache本身之前撤销其所有的slab.
所有普通和专用高速缓存的名字都可以在运行期间通过读取/proc/slabinfo得到, 这个文件也指明了每个cache中空闲对象的个数和已分配对象的个数.
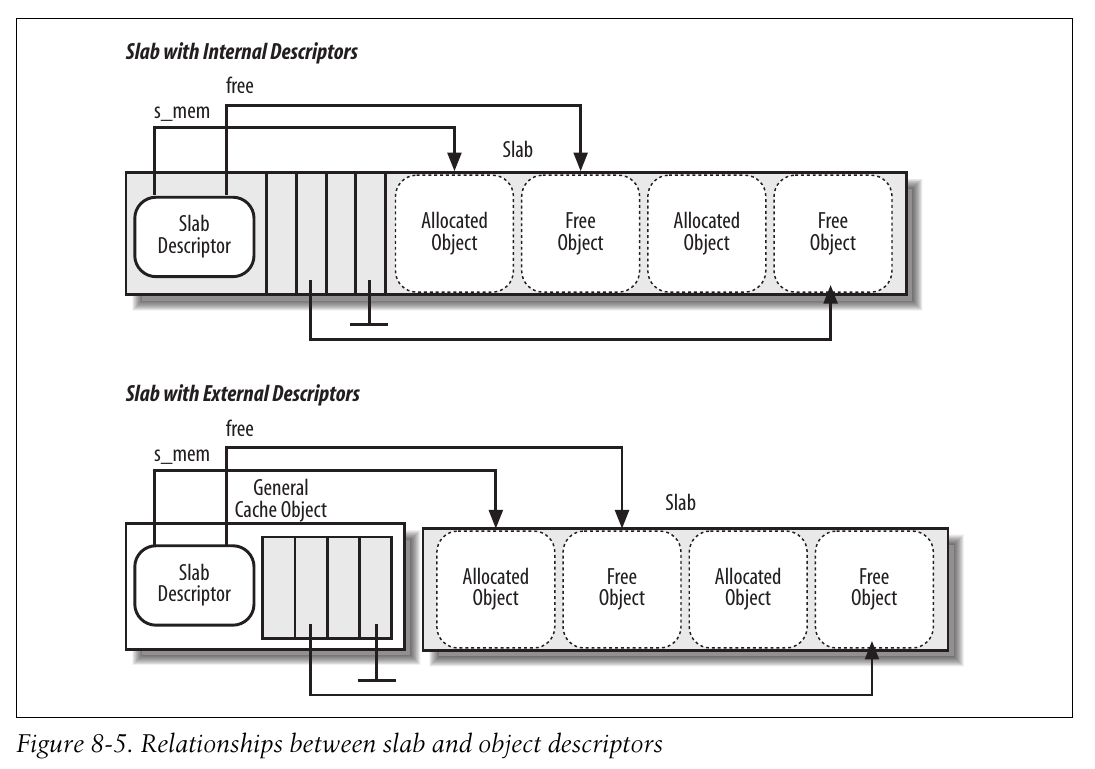
对象描述符
每个对象都有类型为kmem_bufctl_t的描述符, 对象描述符存放在数组中, 位于对应的slab描述符之后; 类似的, slab对象的描述符也有两种可能的方式存放:
-
外部对象描述符: 存放在slab外面, 位于cache描述符的
slabp_cache字段指向的一个普通高速缓存中. -
内部对象描述符: 存放在slab内部, 正好位于描述符所描述的对象前面.
事实上, 对象描述符只不过是一个无符号整数, 只有在对象空闲时才有意义: 包含的是下一个空闲对象在slab中的下标; 因此实现了一个slab内部关于空闲对象的简单链表. 该链表最后一个对象的描述符用常规值BUFCTL_END(0xffff)标记.
对齐内存中的对象
slab分配器管理的对象可以在内存中进行对齐, 使得存放他们的内存单元的起始物理地址是一个常量的倍数, 这个常量就被叫做对齐因子.
slab分配器允许最大的对齐因子是4096, 即一个页框的大小. 这就意味着通过访问对象的物理地址或线性地址就可以对齐该对象, 只有最低的12位会被改变.
通常, 内存单元的物理地址是字大小(内部内存总线的宽度)的倍数, 微机访问内存单元就会非常快. 因而缺省情况下, kmem_cache_create函数会根据BYTES_PER_WORD宏指定的字大小来对齐对象.
创建一个新的slab高速缓存时, 可以让它包含的对象在L1 Cache中对齐, 通过设置SLAB_HWCACHE_ALIGH标志即可.
显然, slab分配器在这里所在的事情就是以内存空间换访问时间, 人为增加对象的大小来获得更好的cache性能, 但也引起额外的内碎片.
slab着色
第二章中提到:
同一硬件cache行可以映射ram中很多不同的块, 而slab分配器中相同大小的对象倾向于放在cache内相同偏移量处, 在不同slab内具有相同偏移量的对象最终也很可能映射在同一行中. 因而高速缓存可能因此花费内存周期在同一cache行和ram内存单元之间来来回回传送两个对象, 导致其他的行并未充分利用.
原文空洞的描述有点抽象, 下面考虑一个实例:
假设A,B两个对象均为32B(不超过一个硬件Cache行的大小), 但是起始地址分别为0和16K; 由于全相联模式很少使用, 因而AB很大可能都会映射到Cache第0行(多路相联显然会缓解这种问题, 此处以最为极端的直接相联为例). 此时如果交替访问AB各自50次, 就很大概率会产生冲突, 每一次访问都将造成miss, 从而在内存和cache之间往返传送这两个对象.
为了避免这种愚蠢的事情, slab分配器采用一种叫做 slab着色(slab coloring) 的策略, 将称为颜色的不同随机数均匀分配给slab.
下面说明这种方法如何运行, 以及为何可以提高cache的访问效率.
首先说明几个相关的变量:
-
num: slab中可存放的对象
-
osize: 对象的大小
-
dsize: slap描述符加上所有对象描述符的大小
-
free: slab内的碎片字节
-
aln: 对齐因子
据此, 一个slab的总字节长度为dsize + osize * num + free.
free的值总是小于osize, 不然一定可以再分配一个对象在slab内; 不过free可以大于aln.
事实上, slab分配器就是利用free来对slab着色, 具体方法如下:
-
该高速缓存中所有的slab可用颜色的个数为
free/aln, 循环地将颜色分配给每个slab -
如果用颜色col对一个slab着色, 那么slab内所有内容都拥有偏移量
col*aln; 着色的本质是将原本在slab末尾的若干碎片字节移动到开头, 并且保证字节的对齐.
下图展示了着色后的slab内部结构:
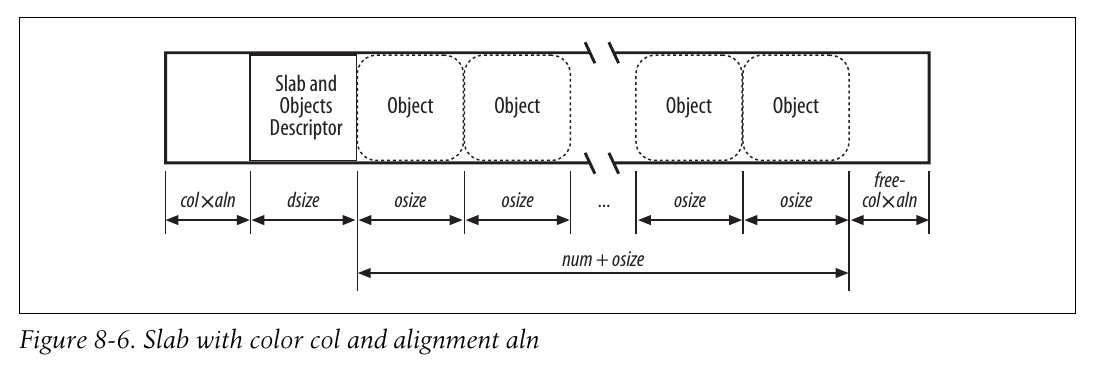
只有当free足够大时, 着色才起作用.
另外, 之前一直不够理解为何填充若干个偏移后就可以避免cache愚蠢的反复传送, 是因为有一个重要的但基本的事实没有被注意到: aln实际上是不小于一个硬件cache行大小的. 可以参考kmem_cache_create中部分代码:
1...
2 cachep->colour_off = cache_line_size();
3 /* Offset must be a multiple of the alignment. */
4 if (cachep->colour_off < align)
5 cachep->colour_off = align;
6 cachep->colour = left_over/cachep->colour_off;
7...事实上, 每个对齐因子(即cachep->colour_off)初值均为硬件cache中一行的大小, 而且有可能会被增大到指定的一个对齐因子上. 只有这样, 当使用着色方法来将slab的起始地址进行适当的偏移后, 能确切地改变其映射在硬件cache中的块的位置, 从而避免多个slab争夺同一块的问题. 这就解释了开头的问题, 并说明了着色如何提高cache访问的效率.
空闲slab对象的本地高速缓存
Linux2.6在多处理器系统上的slab分配器实现不同于其最初的实现. 为了减少处理器之间对于自旋锁的竞争并更好地利用硬件高速缓存, slab分配器中的每个高速缓存都有一个每CPU数据结构array, 被称为slab本地高速缓存, 其类型为array_cache类型的数组, 数组元素为CPU数量, 每个array_cache数据结构是空闲对象的本地高速缓存的一个描述符:
1/*
2 * struct array_cache
3 *
4 * Per cpu structures
5 * Purpose:
6 * - LIFO ordering, to hand out cache-warm objects from _alloc
7 * - reduce the number of linked list operations
8 * - reduce spinlock operations
9 *
10 * The limit is stored in the per-cpu structure to reduce the data cache
11 * footprint.
12 *
13 */
14struct array_cache {
15 unsigned int avail;
16 unsigned int limit;
17 unsigned int batchcount;
18 unsigned int touched;
19};
本地高速缓存描述符内部并不包含本地高速缓存本身的地址, 该地址事实上紧挨着描述符之后(更多代码细节可以参考 分配和释放slab对象). 本地高速缓存中存放的是可使用对象的指针, 而不是对象本身; 对象本身总是存在于高速缓存的slab中.
当创建一个新的slab高速缓存时, kmem_cache_create函数将决定本地高速缓存的大小并将其存放在描述符limit字段中, 分配本地高速缓存, 并将对应的描述符指针存入array字段中. limit的大小取决于slab中对象的大小, 范围从1(非常大的对象)到120(小对象). batchcount字段的初值被初始化为本地高速缓存大小的一半.
在多处理器系统中, 小对象使用的slab高速缓存同样包含一个附加的本地高速缓存, 其地址存放在高速缓存描述符的lists.shared字段中. 这个共享的本地高速缓存被所有CPU共享, 它将使得空闲对象从一个本地高速缓存转移到另一个的任务更容易, 其初值等于batchcount的8倍.
slab分配器和分区页框分配器的接口
slab分配器创建新的slab时, 依靠页框分配器来获得一组连续的空闲页框. 通过调用kmem_getpages函数:
1/*
2 * Interface to system's page allocator. No need to hold the cache-lock.
3 *
4 * If we requested dmaable memory, we will get it. Even if we
5 * did not request dmaable memory, we might get it, but that
6 * would be relatively rare and ignorable.
7 */
8static void *kmem_getpages(kmem_cache_t *cachep, int flags, int nodeid)
9{
10 struct page *page;
11 void *addr;
12 int i;
13
14 flags |= cachep->gfpflags;
15 if (likely(nodeid == -1)) {
16 page = alloc_pages(flags, cachep->gfporder);
17 } else {
18 page = alloc_pages_node(nodeid, flags, cachep->gfporder);
19 }
20 if (!page)
21 return NULL;
22 addr = page_address(page);
23
24 i = (1 << cachep->gfporder);
25 if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
26 atomic_add(i, &slab_reclaim_pages);
27 add_page_state(nr_slab, i);
28 while (i--) {
29 SetPageSlab(page);
30 page++;
31 }
32 return addr;
33}-
参数中
flags说明如何请求页框, 参考 请求页框中的__GFP_*标志. -
在UMA架构下,
nodeid为-1, 总是执行alloc_pages分配连续的页框, 分配的大小由cache描述符中的gfporder字段指定. 注意, 不可能从高端内存管理区中分配页框, 因为本函数最终将返回页框的线性地址. -
如果设置了
SLAB_RECLAIM_ACCOUNT标志(是否跟踪页框分配), 则将对全局的原子变量slab_reclaim_pages加上本次请求内存的大小, 该全局变量会被其余的函数使用c1/* 2* vm_enough_memory() looks at this to determine how many 3* slab-allocated pages are possibly freeable under pressure 4* 5* SLAB_RECLAIM_ACCOUNT turns this on per-slab 6*/ 7atomic_t slab_reclaim_pages; -
调用
add_page_state, 本质也是对__mod_page_state的一种封装.c1void __mod_page_state(unsigned offset, unsigned long delta) 2{ 3 unsigned long flags; 4 void* ptr; 5 6 local_irq_save(flags); 7 ptr = &__get_cpu_var(page_states); 8 *(unsigned long*)(ptr + offset) += delta; 9 local_irq_restore(flags); 10} 11 12#define mod_page_state(member, delta) \ 13 __mod_page_state(offsetof(struct page_state, member), (delta)) 14 15#define add_page_state(member,delta) mod_page_state(member, (delta)) -
最后通过循环, 将slab分配的每个页框的页描述符设置
_PG_slab标志
通过调用kmem_freepages函数释放分配给slab的页框:
1/*
2 * Interface to system's page release.
3 */
4static void kmem_freepages(kmem_cache_t *cachep, void *addr)
5{
6 unsigned long i = (1<<cachep->gfporder);
7 struct page *page = virt_to_page(addr);
8 const unsigned long nr_freed = i;
9
10 while (i--) {
11 if (!TestClearPageSlab(page))
12 BUG();
13 page++;
14 }
15 sub_page_state(nr_slab, nr_freed);
16 if (current->reclaim_state)
17 current->reclaim_state->reclaimed_slab += nr_freed;
18 free_pages((unsigned long)addr, cachep->gfporder);
19 if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
20 atomic_sub(1<<cachep->gfporder, &slab_reclaim_pages);
21}其中:
-
如果进程正在执行内存回收(
reclaim_state字段不为零, L16),reclaimed_slab字段就相应地增加, 于是刚被释放的页就能通过页框回收算法被记录下来. -
对应分配算法, 如果设置了
SLAB_RECLAIM_ACCOUNT标志, 则也将更新全局变量slab_reclaim_pages
向高速缓存分配和释放slab
新创建的cache里没有任何slab, 因此也没有空闲的对象. 只有同时满足下面两个条件时才会给cache分配slab:
-
已发出一个分配新对象的请求
-
高速缓存不包含任何空闲对象
slab分配器通过调用cache_grow来给cache分配一个新的slab:
1/*
2 * Grow (by 1) the number of slabs within a cache. This is called by
3 * kmem_cache_alloc() when there are no active objs left in a cache.
4 */
5static int cache_grow (kmem_cache_t * cachep, int flags, int nodeid)
6{
7 struct slab *slabp;
8 void *objp;
9 size_t offset;
10 int local_flags;
11 unsigned long ctor_flags;
12
13 /* Be lazy and only check for valid flags here,
14 * keeping it out of the critical path in kmem_cache_alloc().
15 */
16 if (flags & ~(SLAB_DMA|SLAB_LEVEL_MASK|SLAB_NO_GROW))
17 BUG();
18 if (flags & SLAB_NO_GROW)
19 return 0;
20
21 ctor_flags = SLAB_CTOR_CONSTRUCTOR;
22 local_flags = (flags & SLAB_LEVEL_MASK);
23 if (!(local_flags & __GFP_WAIT))
24 /*
25 * Not allowed to sleep. Need to tell a constructor about
26 * this - it might need to know...
27 */
28 ctor_flags |= SLAB_CTOR_ATOMIC;
29
30 /* About to mess with non-constant members - lock. */
31 check_irq_off();
32 spin_lock(&cachep->spinlock);
33
34 /* Get colour for the slab, and cal the next value. */
35 offset = cachep->colour_next;
36 cachep->colour_next++;
37 if (cachep->colour_next >= cachep->colour)
38 cachep->colour_next = 0;
39 offset *= cachep->colour_off;
40
41 spin_unlock(&cachep->spinlock);
42
43 if (local_flags & __GFP_WAIT)
44 local_irq_enable();
45
46 /*
47 * The test for missing atomic flag is performed here, rather than
48 * the more obvious place, simply to reduce the critical path length
49 * in kmem_cache_alloc(). If a caller is seriously mis-behaving they
50 * will eventually be caught here (where it matters).
51 */
52 kmem_flagcheck(cachep, flags);
53
54
55 /* Get mem for the objs. */
56 if (!(objp = kmem_getpages(cachep, flags, nodeid)))
57 goto failed;
58
59 /* Get slab management. */
60 if (!(slabp = alloc_slabmgmt(cachep, objp, offset, local_flags)))
61 goto opps1;
62
63 set_slab_attr(cachep, slabp, objp);
64
65 cache_init_objs(cachep, slabp, ctor_flags);
66
67 if (local_flags & __GFP_WAIT)
68 local_irq_disable();
69 check_irq_off();
70 spin_lock(&cachep->spinlock);
71
72 /* Make slab active. */
73 list_add_tail(&slabp->list, &(list3_data(cachep)->slabs_free));
74 STATS_INC_GROWN(cachep);
75 list3_data(cachep)->free_objects += cachep->num;
76 spin_unlock(&cachep->spinlock);
77 return 1;
78opps1:
79 kmem_freepages(cachep, objp);
80failed:
81 if (local_flags & __GFP_WAIT)
82 local_irq_disable();
83 return 0;
84}-
函数前期首先进行各种标志的设置和检查, 查阅标志的含义并阅读代码即可大致理解, 不予细述
-
L35-39进行染色.
color_next为下一个被分配的slab使用的颜色, 使用该颜色给本slab, 同时取模递增该值;offset为颜色乘以对齐量, 也就是slab开头的基本偏移量. -
kmem_flagcheck判断是否需要原子分配, 并检查错误的flag设置:c1static void kmem_flagcheck(kmem_cache_t *cachep, int flags) 2{ 3 if (flags & SLAB_DMA) { 4 if (!(cachep->gfpflags & GFP_DMA)) 5 BUG(); 6 } else { 7 if (cachep->gfpflags & GFP_DMA) 8 BUG(); 9 } 10} -
调用
kmem_getpages函数从伙伴系统中得到页框. -
调用
alloc_slabmgmt分配一个新的slab描述符:c1/* Get the memory for a slab management obj. */ 2static struct slab* alloc_slabmgmt (kmem_cache_t *cachep, 3 void *objp, int colour_off, int local_flags) 4{ 5 struct slab *slabp; 6 7 if (OFF_SLAB(cachep)) { 8 /* Slab management obj is off-slab. */ 9 slabp = kmem_cache_alloc(cachep->slabp_cache, local_flags); 10 if (!slabp) 11 return NULL; 12 } else { 13 slabp = objp+colour_off; 14 colour_off += cachep->slab_size; 15 } 16 slabp->inuse = 0; 17 slabp->colouroff = colour_off; 18 slabp->s_mem = objp+colour_off; 19 20 return slabp; 21}-
首先根据是否设置了
CFLGS_OFF_SLAB标志, 来决定在哪边存放slab描述符. 当设置标志后, 调用kmem_cache_alloc函数在高速缓存的slabp_cache中分配一个slab对象(参考 分配和释放slab对象); 如果未设置标志, slabp存放在页框起始的若干偏移处, 偏移大小根据color决定. -
根据传入的参数, 初始化slabp内的部分数据结构, 最终返回描述符地址. 注意, 如果slab描述符存放在内部, 那么colour_off将会额外加上
slab_size字段的内容, 该字段记录了slab描述符和所有对象描述符的大小:c1... 2 slab_size = ALIGN(cachep->num*sizeof(kmem_bufctl_t) 3 + sizeof(struct slab), align); 4 5 /* 6 * If the slab has been placed off-slab, and we have enough space then 7 * move it on-slab. This is at the expense of any extra colouring. 8 */ 9 if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) { 10 flags &= ~CFLGS_OFF_SLAB; 11 left_over -= slab_size; 12 } 13 14 if (flags & CFLGS_OFF_SLAB) { 15 /* really off slab. No need for manual alignment */ 16 slab_size = cachep->num*sizeof(kmem_bufctl_t)+sizeof(struct slab); 17 } 18 cachep->slab_size = slab_size; 19...因而在这种情况下, 对于slab描述符中
s_mem以及colouroff的初始化就正确无误了.
-
-
遍历涉及到的所有页, 更新页描述符
lru的字段, 将该节点的前后指针分别指向其所在的slabp和cachep. 注意, 当页面空闲时, lru字段被伙伴系统使用; 而在分配页框给slab时,kmem_getpages向伙伴系统请求页框, 这些页框就已经被设置了PG_slab标志而不再空闲, 因而这样利用lru字段没有问题.c1#define SET_PAGE_CACHE(pg,x) ((pg)->lru.next = (struct list_head *)(x)) 2#define SET_PAGE_SLAB(pg,x) ((pg)->lru.prev = (struct list_head *)(x)) 3static void set_slab_attr(kmem_cache_t *cachep, struct slab *slabp, void *objp) 4{ 5 int i; 6 struct page *page; 7 8 /* Nasty!!!!!! I hope this is OK. */ 9 i = 1 << cachep->gfporder; 10 page = virt_to_page(objp); 11 do { 12 SET_PAGE_CACHE(page, cachep); 13 SET_PAGE_SLAB(page, slabp); 14 page++; 15 } while (--i); 16} -
调用
cache_init_objs初始化slab内的所有对象.c1static void cache_init_objs (kmem_cache_t * cachep, 2 struct slab * slabp, unsigned long ctor_flags) 3{ 4 int i; 5 6 for (i = 0; i < cachep->num; i++) { 7 void* objp = slabp->s_mem+cachep->objsize*i; 8 if (cachep->ctor) 9 cachep->ctor(objp, cachep, ctor_flags); 10 slab_bufctl(slabp)[i] = i+1; 11 } 12 slab_bufctl(slabp)[i-1] = BUFCTL_END; 13 slabp->free = 0; 14} 15 16static inline kmem_bufctl_t *slab_bufctl(struct slab *slabp) 17{ 18 return (kmem_bufctl_t *)(slabp+1); 19}-
循环内部, objp为对象的地址. 如果cache定义了构造方法, 则调用该构造方法初始化所有的对象.
-
同时不断更新对象描述符, 初始化该简单链表. 这里比较精妙:
slab_bufctl函数对slabp指针加一, 运算结果为下一个slab类型应该在的起始地址, 而由于所有对象的描述符数组紧挨着slab描述符, 因而该地址就是第一个对象描述符的起始地址, 对其进行一次指针类型转化后返回即可.
-
-
L73将slab插入到高速缓存中.
list3_data将拓展cache描述符为其lists字段; 由于是新的slab, 所以插入到slabs_free链中; 并更新list3结构中的free_objects字段.c1#define list3_data(cachep) \ 2 (&(cachep)->lists) -
STATS_INC_GROWN是统计信息, 不予细究.
在两种条件下才能撤销slab:
-
slab高速缓存中有太多的空闲对象
-
周期性调用的定时器函数确定有完全未使用的slab
通过调用slab_destroy来撤销一个slab, 并释放页框到伙伴系统(已删去调试代码):
1/* Destroy all the objs in a slab, and release the mem back to the system.
2 * Before calling the slab must have been unlinked from the cache.
3 * The cache-lock is not held/needed.
4 */
5static void slab_destroy (kmem_cache_t *cachep, struct slab *slabp)
6{
7 void *addr = slabp->s_mem - slabp->colouroff;
8
9 if (cachep->dtor) {
10 int i;
11 for (i = 0; i < cachep->num; i++) {
12 void* objp = slabp->s_mem+cachep->objsize*i;
13 (cachep->dtor)(objp, cachep, 0);
14 }
15 }
16
17 if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
18 struct slab_rcu *slab_rcu;
19
20 slab_rcu = (struct slab_rcu *) slabp;
21 slab_rcu->cachep = cachep;
22 slab_rcu->addr = addr;
23 call_rcu(&slab_rcu->head, kmem_rcu_free);
24 } else {
25 kmem_freepages(cachep, addr);
26 if (OFF_SLAB(cachep))
27 kmem_cache_free(cachep->slabp_cache, slabp);
28 }
29}-
s_mem字段保证存放的是第一个对象的起始地址,colouroff字段保证存放的是第一个对象距离页框起始位置的偏移量, 参考本小节cache_grow中的解析; 因而作差得到的addr字段即为当前slab的起始页框地址. -
检查是否有定义析构函数, 如果有则对slab内的每一页都执行该析构函数.
-
检测
SLAB_DESTROY_BY_RCU标志, 如果设置了则意味着将使用call_rcu函数注册一个回调来延期释放slab(参考第五章的"读-拷贝-更新(RCU)一节), 留坑. -
不然, 调用接口函数
kmem_freepages释放页框; 如果cache描述符在slab外部, 则额外调用kmem_cache_free函数(参考 分配和释放slab对象)释放该对象
分配和释放slab对象
调用kmem_cache_alloc函数可以获取新对象:
1static inline void * __cache_alloc (kmem_cache_t *cachep, int flags)
2{
3 unsigned long save_flags;
4 void* objp;
5 struct array_cache *ac;
6
7 cache_alloc_debugcheck_before(cachep, flags);
8
9 local_irq_save(save_flags);
10 ac = ac_data(cachep);
11 if (likely(ac->avail)) {
12 STATS_INC_ALLOCHIT(cachep);
13 ac->touched = 1;
14 objp = ac_entry(ac)[--ac->avail];
15 } else {
16 STATS_INC_ALLOCMISS(cachep);
17 objp = cache_alloc_refill(cachep, flags);
18 }
19 local_irq_restore(save_flags);
20 objp = cache_alloc_debugcheck_after(cachep, flags, objp, __builtin_return_address(0));
21 return objp;
22}
23
24/**
25 * kmem_cache_alloc - Allocate an object
26 * @cachep: The cache to allocate from.
27 * @flags: See kmalloc().
28 *
29 * Allocate an object from this cache. The flags are only relevant
30 * if the cache has no available objects.
31 */
32void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
33{
34 return __cache_alloc(cachep, flags);
35}其中:
-
L10: ac_data获得本地高速缓存, ac指向
array_cache结构.c1static inline struct array_cache *ac_data(kmem_cache_t *cachep) 2{ 3 return cachep->array[smp_processor_id()]; 4} -
随后判断本地高速缓存中是否有空闲对象(
ac->avail大于0), 如果有则更新相应的标志, 通过ac_entry获得该对象的指针;ac_entry的实现如下, 容易与 空闲slab对象的本地高速缓存相互印证.c1static inline void ** ac_entry(struct array_cache *ac) 2{ 3 return (void**)(ac+1); 4} -
如果在本地高速缓存中未找到一个空闲的对象, 则将调用
cache_alloc_refill分配一个新的对象c1static void* cache_alloc_refill(kmem_cache_t* cachep, int flags) 2{ 3 int batchcount; 4 struct kmem_list3 *l3; 5 struct array_cache *ac; 6 7 check_irq_off(); 8 ac = ac_data(cachep); 9retry: 10 batchcount = ac->batchcount; 11 if (!ac->touched && batchcount > BATCHREFILL_LIMIT) { 12 /* if there was little recent activity on this 13 * cache, then perform only a partial refill. 14 * Otherwise we could generate refill bouncing. 15 */ 16 batchcount = BATCHREFILL_LIMIT; 17 } 18 l3 = list3_data(cachep); 19 20 BUG_ON(ac->avail > 0); 21 spin_lock(&cachep->spinlock); 22 if (l3->shared) { 23 struct array_cache *shared_array = l3->shared; 24 if (shared_array->avail) { 25 if (batchcount > shared_array->avail) 26 batchcount = shared_array->avail; 27 shared_array->avail -= batchcount; 28 ac->avail = batchcount; 29 memcpy(ac_entry(ac), &ac_entry(shared_array)[shared_array->avail], 30 sizeof(void*)*batchcount); 31 shared_array->touched = 1; 32 goto alloc_done; 33 } 34 } 35 while (batchcount > 0) { 36 struct list_head *entry; 37 struct slab *slabp; 38 /* Get slab alloc is to come from. */ 39 entry = l3->slabs_partial.next; 40 if (entry == &l3->slabs_partial) { 41 l3->free_touched = 1; 42 entry = l3->slabs_free.next; 43 if (entry == &l3->slabs_free) 44 goto must_grow; 45 } 46 47 slabp = list_entry(entry, struct slab, list); 48 check_slabp(cachep, slabp); 49 check_spinlock_acquired(cachep); 50 while (slabp->inuse < cachep->num && batchcount--) { 51 kmem_bufctl_t next; 52 STATS_INC_ALLOCED(cachep); 53 STATS_INC_ACTIVE(cachep); 54 STATS_SET_HIGH(cachep); 55 56 /* get obj pointer */ 57 ac_entry(ac)[ac->avail++] = slabp->s_mem + slabp->free*cachep->objsize; 58 59 slabp->inuse++; 60 next = slab_bufctl(slabp)[slabp->free]; 61 slabp->free = next; 62 } 63 check_slabp(cachep, slabp); 64 65 /* move slabp to correct slabp list: */ 66 list_del(&slabp->list); 67 if (slabp->free == BUFCTL_END) 68 list_add(&slabp->list, &l3->slabs_full); 69 else 70 list_add(&slabp->list, &l3->slabs_partial); 71 } 72 73must_grow: 74 l3->free_objects -= ac->avail; 75alloc_done: 76 spin_unlock(&cachep->spinlock); 77 78 if (unlikely(!ac->avail)) { 79 int x; 80 x = cache_grow(cachep, flags, -1); 81 82 // cache_grow can reenable interrupts, then ac could change. 83 ac = ac_data(cachep); 84 if (!x && ac->avail == 0) // no objects in sight? abort 85 return NULL; 86 87 if (!ac->avail) // objects refilled by interrupt? 88 goto retry; 89 } 90 ac->touched = 1; 91 return ac_entry(ac)[--ac->avail]; 92}-
首先获取当前本地高速缓存的
batchcount数值. 如果当前缓存很少被使用, 则使用部分的重填装(坑). -
检查多处理器系统中CPU共享的本地高速缓存
l3->shared是否拥有空闲的对象; 如果有则将其拥有的空闲对象尽量分配给当前高速缓存, 并维护好ac和shared结构中对应的数据信息. -
如果共享缓存并未成功分配出空闲对象, 则需要循环查询
l3字段中另外的一些链表:-
检查所有的部分链表
slabs_partial, 通过一个简单的判断&l3->slabs_partial == l3->slabs_partial即可知道链表是否为空, 这一点比较精妙. 如果部分链表为空, 且全空链表slabs_free也为空, 则进行must_grow阶段, 该阶段将稍后再进行讲解; -
不然, 即全空链表有空闲slab, 则将从全空链表中的一个空闲slab取对象分配给当前本地高速缓存, 同时更新slab描述符中的
list字段到l3内合适的三个链表之一, 代码十分清楚(L47-80).
-
-
最终根据分配情况有两个结果:
-
alloc_done: 释放锁, 再次检查本地高速缓存中是否拥有元素; 当没有元素时, 要么是上述过程全部分配失败, 要么大概是发生了内核进程同步的问题(?), 此时应当进行
cache_grow(参考 向高速缓存分配和释放slab)尝试向该高速缓存分配一个slab; 此时中断已经被重新打开, 可以再次检查一次本地高速缓存是否有空闲对象, 如果仍然没有, 返回到第一步重新开始; 如果有, 则更新对应的标志即可完成本函数. -
must_grow: 只有在循环从
l3中取对象时才有可能跳入到该分支, 因而此时ac->avail字段中正存储着已经从l3中分配出来的对象数量, 所以必须将该数量对应的减去后再进入alloc_done代码段.
-
-
函数最终返回分配对象的地址. 事实上, 该对象地址总是被保存在本地高速缓存中.
-
-
跳回到原函数, 恢复中断状态, 返回对象指针, 完成本次的分配.
调用kmem_cache_free释放一个曾经分配的slab对象.
1/*
2 * __cache_free
3 * Release an obj back to its cache. If the obj has a constructed
4 * state, it must be in this state _before_ it is released.
5 *
6 * Called with disabled ints.
7 */
8static inline void __cache_free (kmem_cache_t *cachep, void* objp)
9{
10 struct array_cache *ac = ac_data(cachep);
11
12 check_irq_off();
13 objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
14
15 if (likely(ac->avail < ac->limit)) {
16 STATS_INC_FREEHIT(cachep);
17 ac_entry(ac)[ac->avail++] = objp;
18 return;
19 } else {
20 STATS_INC_FREEMISS(cachep);
21 cache_flusharray(cachep, ac);
22 ac_entry(ac)[ac->avail++] = objp;
23 }
24}
25
26
27/**
28 * kmem_cache_free - Deallocate an object
29 * @cachep: The cache the allocation was from.
30 * @objp: The previously allocated object.
31 *
32 * Free an object which was previously allocated from this
33 * cache.
34 */
35void kmem_cache_free (kmem_cache_t *cachep, void *objp)
36{
37 unsigned long flags;
38
39 local_irq_save(flags);
40 __cache_free(cachep, objp);
41 local_irq_restore(flags);
42}-
如果本地高速缓存仍然可以放下一个空闲的对象, 则将其塞入其中即可;
-
不然, 则将调用
cache_flusharray函数(删去了统计和调试代码)先移除本地高速缓存中的部分对象, 再将该对象塞入其中:c1static void cache_flusharray (kmem_cache_t* cachep, struct array_cache *ac) 2{ 3 int batchcount; 4 5 batchcount = ac->batchcount; 6 check_irq_off(); 7 spin_lock(&cachep->spinlock); 8 if (cachep->lists.shared) { 9 struct array_cache *shared_array = cachep->lists.shared; 10 int max = shared_array->limit-shared_array->avail; 11 if (max) { 12 if (batchcount > max) 13 batchcount = max; 14 memcpy(&ac_entry(shared_array)[shared_array->avail], 15 &ac_entry(ac)[0], 16 sizeof(void*)*batchcount); 17 shared_array->avail += batchcount; 18 goto free_done; 19 } 20 } 21 22 free_block(cachep, &ac_entry(ac)[0], batchcount); 23free_done: 24 spin_unlock(&cachep->spinlock); 25 ac->avail -= batchcount; 26 memmove(&ac_entry(ac)[0], &ac_entry(ac)[batchcount], 27 sizeof(void*)*ac->avail); 28}-
具体检查过程自然为分配对象的逆过程. 首先检查多CPU共享的链表, 如果还能补充对象, 则尽力对其进行补充
-
不然, 多CPU共享链表已满, 则调用
free_block将本地高速缓存的中batchcount个对象补充回list3结构中.c1/* 2* NUMA: different approach needed if the spinlock is moved into 3* the l3 structure 4*/ 5 6static void free_block(kmem_cache_t *cachep, void **objpp, int nr_objects) 7{ 8 int i; 9 10 check_spinlock_acquired(cachep); 11 12 /* NUMA: move add into loop */ 13 cachep->lists.free_objects += nr_objects; 14 15 for (i = 0; i < nr_objects; i++) { 16 void *objp = objpp[i]; 17 struct slab *slabp; 18 unsigned int objnr; 19 20 slabp = GET_PAGE_SLAB(virt_to_page(objp)); 21 list_del(&slabp->list); 22 objnr = (objp - slabp->s_mem) / cachep->objsize; 23 check_slabp(cachep, slabp); 24 slab_bufctl(slabp)[objnr] = slabp->free; 25 slabp->free = objnr; 26 STATS_DEC_ACTIVE(cachep); 27 slabp->inuse--; 28 check_slabp(cachep, slabp); 29 30 /* fixup slab chains */ 31 if (slabp->inuse == 0) { 32 if (cachep->lists.free_objects > cachep->free_limit) { 33 cachep->lists.free_objects -= cachep->num; 34 slab_destroy(cachep, slabp); 35 } else { 36 list_add(&slabp->list, 37 &list3_data_ptr(cachep, objp)->slabs_free); 38 } 39 } else { 40 /* Unconditionally move a slab to the end of the 41 * partial list on free - maximum time for the 42 * other objects to be freed, too. 43 */ 44 list_add_tail(&slabp->list, 45 &list3_data_ptr(cachep, objp)->slabs_partial); 46 } 47 } 48}-
函数将从前往后遍历指定数量的对象. 对每一个对象而言, 首先找到其真实存储于其中的slab结构(L20), 随后计算得出该对象在slab内的序号(L22), 再将该对象插入回slab, 维护好
slab->free和对象描述符共同构成的简单链表(L24-25), 并更新inuse字段. -
其中, L20使用到了页描述符的
lru字段, 该字段被特殊填充, 存储了slabp和cachep的指针. (参考 向高速缓存分配和释放slab) -
由于slab内新增了一个空闲对象, slab的性质可能发生改变.
-
如果slab仍然有非空对象, 则无条件地将该slab移动到
slabs_partial末尾. -
如果slab已经全空, 进一步检查该slab拥有的对象数量是否已经超过上限, 如果未超过, 将该slab移动到
slabs_free开头; 如果超过, 则调用slab_destroy来析构该slab内所有的对象, 并释放整个页框.
c1/* Destroy all the objs in a slab, and release the mem back to the system. 2* Before calling the slab must have been unlinked from the cache. 3* The cache-lock is not held/needed. 4*/ 5static void slab_destroy (kmem_cache_t *cachep, struct slab *slabp) 6{ 7 void *addr = slabp->s_mem - slabp->colouroff; 8 9 if (cachep->dtor) { 10 int i; 11 for (i = 0; i < cachep->num; i++) { 12 void* objp = slabp->s_mem+cachep->objsize*i; 13 (cachep->dtor)(objp, cachep, 0); 14 } 15 } 16 17 if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) { 18 struct slab_rcu *slab_rcu; 19 20 slab_rcu = (struct slab_rcu *) slabp; 21 slab_rcu->cachep = cachep; 22 slab_rcu->addr = addr; 23 call_rcu(&slab_rcu->head, kmem_rcu_free); 24 } else { 25 kmem_freepages(cachep, addr); 26 if (OFF_SLAB(cachep)) 27 kmem_cache_free(cachep->slabp_cache, slabp); 28 } 29} -
-
-
无论是采用哪一种方式移除了一些多余的空闲对象, 最终都将进入
free_done代码段, 更新本地高速缓存的avail字段, 并将本地高速缓存下段的对象上移到从0开始的位置(上段对象被移除了).
-
通用对象
如果对存储区的请求不频繁, 则用一组普通高速缓存来处理, 这类缓存中的对象具有几何分布的大小.
调用kmalloc()函数即可得到这类对象:
1/**
2 * kmalloc - allocate memory
3 * @size: how many bytes of memory are required.
4 * @flags: the type of memory to allocate.
5 *
6 * kmalloc is the normal method of allocating memory
7 * in the kernel.
8 *
9 * The @flags argument may be one of:
10 *
11 * %GFP_USER - Allocate memory on behalf of user. May sleep.
12 *
13 * %GFP_KERNEL - Allocate normal kernel ram. May sleep.
14 *
15 * %GFP_ATOMIC - Allocation will not sleep. Use inside interrupt handlers.
16 *
17 * Additionally, the %GFP_DMA flag may be set to indicate the memory
18 * must be suitable for DMA. This can mean different things on different
19 * platforms. For example, on i386, it means that the memory must come
20 * from the first 16MB.
21 */
22void * __kmalloc (size_t size, int flags)
23{
24 struct cache_sizes *csizep = malloc_sizes;
25
26 for (; csizep->cs_size; csizep++) {
27 if (size > csizep->cs_size)
28 continue;
29 return __cache_alloc(flags & GFP_DMA ?
30 csizep->cs_dmacachep : csizep->cs_cachep, flags);
31 }
32 return NULL;
33}首先需要了解一下struct cache_sizes类型和malloc_sizes数组. 数组中每一个元素都记录了对应大小的高速缓存描述符, 该描述符在kmem_cache_init函数中被初始化, 暂时不予深究.
1/***************************** linux-2.6.11.12/include/linux/kmalloc_sizes.c *****************************/
2#if (PAGE_SIZE == 4096)
3 CACHE(32)
4#endif
5 CACHE(64)
6#if L1_CACHE_BYTES < 64
7 CACHE(96)
8#endif
9 CACHE(128)
10#if L1_CACHE_BYTES < 128
11 CACHE(192)
12#endif
13 CACHE(256)
14 CACHE(512)
15 CACHE(1024)
16 CACHE(2048)
17 CACHE(4096)
18 CACHE(8192)
19 CACHE(16384)
20 CACHE(32768)
21 CACHE(65536)
22 CACHE(131072)
23#ifndef CONFIG_MMU
24 CACHE(262144)
25 CACHE(524288)
26 CACHE(1048576)
27#ifdef CONFIG_LARGE_ALLOCS
28 CACHE(2097152)
29 CACHE(4194304)
30 CACHE(8388608)
31 CACHE(16777216)
32 CACHE(33554432)
33#endif /* CONFIG_LARGE_ALLOCS */
34#endif /* CONFIG_MMU */
35
36
37/***************************** linux-2.6.11.12/include/linux/slab.h *****************************/
38
39/* Size description struct for general caches. */
40struct cache_sizes {
41 size_t cs_size;
42 kmem_cache_t *cs_cachep;
43 kmem_cache_t *cs_dmacachep;
44};
45
46/***************************** linux-2.6.11.12/include/linux/slab.c *****************************/
47/* These are the default caches for kmalloc. Custom caches can have other sizes. */
48struct cache_sizes malloc_sizes[] = {
49#define CACHE(x) { .cs_size = (x) },
50#include <linux/kmalloc_sizes.h>
51 { 0, }
52#undef CACHE
53};回到__kmalloc函数, 代码就比较简单了. 找到拥有最接近2的幂次大小的对象的高速缓存, 并调用__cache_alloc分配即可.
kfree()函数用于释放通过kmalloc分配的对象:
1/**
2 * kfree - free previously allocated memory
3 * @objp: pointer returned by kmalloc.
4 *
5 * Don't free memory not originally allocated by kmalloc()
6 * or you will run into trouble.
7 */
8void kfree (const void *objp)
9{
10 kmem_cache_t *c;
11 unsigned long flags;
12
13 if (!objp)
14 return;
15 local_irq_save(flags);
16 kfree_debugcheck(objp);
17 c = GET_PAGE_CACHE(virt_to_page(objp));
18 __cache_free(c, (void*)objp);
19 local_irq_restore(flags);
20}其中GET_PAGE_CACHE也是利用了lru字段, 获得了页所在的cache指针后即可使用__cache_free释放对象.
内存池
内存池(memory pool)是Linux2.6的一个新特性, 允许一个内核成分在内存不足的紧急情况下分配一些动态内存使用.
不应将内存池和保留的页框池混淆. 保留的页框池仅仅用于满足中断处理程序或内部临界区发出的原子内存分配请求, 而内存池是动态内存的储备, 仅被特定的内核成分使用.
一个内存池常常用来保存slab对象, 但是一般而言内存池可以用来分配任何一种类型的动态内存. 因此, 我们一般将内存池处理的内存单元看作内存元素.
内存池由mempool_t对象描述, 其字段如下:
1typedef struct mempool_s {
2 spinlock_t lock;
3 int min_nr; /* nr of elements at *elements */
4 int curr_nr; /* Current nr of elements at *elements */
5 void **elements;
6
7 void *pool_data;
8 mempool_alloc_t *alloc;
9 mempool_free_t *free;
10 wait_queue_head_t wait;
11} mempool_t;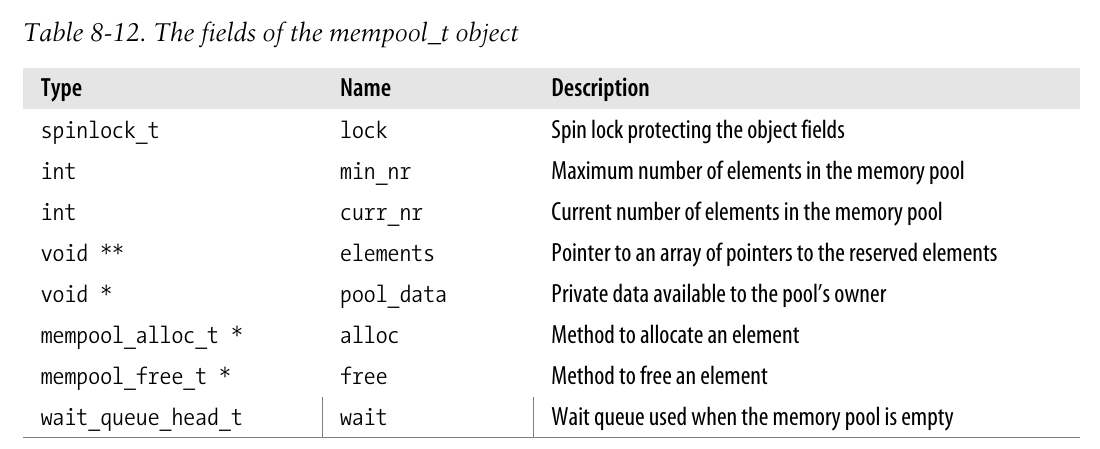
怪的是, min_nr存储的是内存池的最大数量, curr_nr总是小于它
alloc和free方法与基本的内存分配器交互, 可以用于定制函数.
当内存元素是slab对象是, alloc和free方法一般被设置为mempool_alloc_slab和mempool_free_slab, 他们只是简单地分别调用对应slab分配和释放的两个函数. 在这种情况下, pool_data字段就存放了slab高速缓存描述符的地址.
1/*
2 * A commonly used alloc and free fn.
3 */
4void *mempool_alloc_slab(int gfp_mask, void *pool_data)
5{
6 kmem_cache_t *mem = (kmem_cache_t *) pool_data;
7 return kmem_cache_alloc(mem, gfp_mask);
8}
9EXPORT_SYMBOL(mempool_alloc_slab);
10
11void mempool_free_slab(void *element, void *pool_data)
12{
13 kmem_cache_t *mem = (kmem_cache_t *) pool_data;
14 kmem_cache_free(mem, element);
15}
16EXPORT_SYMBOL(mempool_free_slab);add_element和remove_element是在内存池中以栈的方式加入和删减元素的一对简单函数:
1static void add_element(mempool_t *pool, void *element)
2{
3 BUG_ON(pool->curr_nr >= pool->min_nr);
4 pool->elements[pool->curr_nr++] = element;
5}
6
7static void *remove_element(mempool_t *pool)
8{
9 BUG_ON(pool->curr_nr <= 0);
10 return pool->elements[--pool->curr_nr];
11}mempool_create和mempool_destroy是创建和销毁内存池的一对函数:
1/**
2 * mempool_create - create a memory pool
3 * @min_nr: the minimum number of elements guaranteed to be
4 * allocated for this pool.
5 * @alloc_fn: user-defined element-allocation function.
6 * @free_fn: user-defined element-freeing function.
7 * @pool_data: optional private data available to the user-defined functions.
8 *
9 * this function creates and allocates a guaranteed size, preallocated
10 * memory pool. The pool can be used from the mempool_alloc and mempool_free
11 * functions. This function might sleep. Both the alloc_fn() and the free_fn()
12 * functions might sleep - as long as the mempool_alloc function is not called
13 * from IRQ contexts.
14 */
15mempool_t * mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
16 mempool_free_t *free_fn, void *pool_data)
17{
18 mempool_t *pool;
19
20 pool = kmalloc(sizeof(*pool), GFP_KERNEL);
21 if (!pool)
22 return NULL;
23 memset(pool, 0, sizeof(*pool));
24 pool->elements = kmalloc(min_nr * sizeof(void *), GFP_KERNEL);
25 if (!pool->elements) {
26 kfree(pool);
27 return NULL;
28 }
29 spin_lock_init(&pool->lock);
30 pool->min_nr = min_nr;
31 pool->pool_data = pool_data;
32 init_waitqueue_head(&pool->wait);
33 pool->alloc = alloc_fn;
34 pool->free = free_fn;
35
36 /*
37 * First pre-allocate the guaranteed number of buffers.
38 */
39 while (pool->curr_nr < pool->min_nr) {
40 void *element;
41
42 element = pool->alloc(GFP_KERNEL, pool->pool_data);
43 if (unlikely(!element)) {
44 free_pool(pool);
45 return NULL;
46 }
47 add_element(pool, element);
48 }
49 return pool;
50}
51
52/**
53 * mempool_destroy - deallocate a memory pool
54 * @pool: pointer to the memory pool which was allocated via
55 * mempool_create().
56 *
57 * this function only sleeps if the free_fn() function sleeps. The caller
58 * has to guarantee that all elements have been returned to the pool (ie:
59 * freed) prior to calling mempool_destroy().
60 */
61void mempool_destroy(mempool_t *pool)
62{
63 if (pool->curr_nr != pool->min_nr)
64 BUG(); /* There were outstanding elements */
65 free_pool(pool);
66}
67
68static void free_pool(mempool_t *pool)
69{
70 while (pool->curr_nr) {
71 void *element = remove_element(pool);
72 pool->free(element, pool->pool_data);
73 }
74 kfree(pool->elements);
75 kfree(pool);
76}mempool_alloc和mempool_free是从内存池中获取和删除元素的一对函数:
1/**
2 * mempool_alloc - allocate an element from a specific memory pool
3 * @pool: pointer to the memory pool which was allocated via
4 * mempool_create().
5 * @gfp_mask: the usual allocation bitmask.
6 *
7 * this function only sleeps if the alloc_fn function sleeps or
8 * returns NULL. Note that due to preallocation, this function
9 * *never* fails when called from process contexts. (it might
10 * fail if called from an IRQ context.)
11 */
12void * mempool_alloc(mempool_t *pool, int gfp_mask)
13{
14 void *element;
15 unsigned long flags;
16 DEFINE_WAIT(wait);
17 int gfp_nowait = gfp_mask & ~(__GFP_WAIT | __GFP_IO);
18
19 might_sleep_if(gfp_mask & __GFP_WAIT);
20repeat_alloc:
21 element = pool->alloc(gfp_nowait|__GFP_NOWARN, pool->pool_data);
22 if (likely(element != NULL))
23 return element;
24
25 /*
26 * If the pool is less than 50% full and we can perform effective
27 * page reclaim then try harder to allocate an element.
28 */
29 mb();
30 if ((gfp_mask & __GFP_FS) && (gfp_mask != gfp_nowait) &&
31 (pool->curr_nr <= pool->min_nr/2)) {
32 element = pool->alloc(gfp_mask, pool->pool_data);
33 if (likely(element != NULL))
34 return element;
35 }
36
37 /*
38 * Kick the VM at this point.
39 */
40 wakeup_bdflush(0);
41
42 spin_lock_irqsave(&pool->lock, flags);
43 if (likely(pool->curr_nr)) {
44 element = remove_element(pool);
45 spin_unlock_irqrestore(&pool->lock, flags);
46 return element;
47 }
48 spin_unlock_irqrestore(&pool->lock, flags);
49
50 /* We must not sleep in the GFP_ATOMIC case */
51 if (!(gfp_mask & __GFP_WAIT))
52 return NULL;
53
54 prepare_to_wait(&pool->wait, &wait, TASK_UNINTERRUPTIBLE);
55 mb();
56 if (!pool->curr_nr)
57 io_schedule();
58 finish_wait(&pool->wait, &wait);
59
60 goto repeat_alloc;
61}
62
63/**
64 * mempool_free - return an element to the pool.
65 * @element: pool element pointer.
66 * @pool: pointer to the memory pool which was allocated via
67 * mempool_create().
68 *
69 * this function only sleeps if the free_fn() function sleeps.
70 */
71void mempool_free(void *element, mempool_t *pool)
72{
73 unsigned long flags;
74
75 mb();
76 if (pool->curr_nr < pool->min_nr) {
77 spin_lock_irqsave(&pool->lock, flags);
78 if (pool->curr_nr < pool->min_nr) {
79 add_element(pool, element);
80 spin_unlock_irqrestore(&pool->lock, flags);
81 wake_up(&pool->wait);
82 return;
83 }
84 spin_unlock_irqrestore(&pool->lock, flags);
85 }
86 pool->free(element, pool->pool_data);
87}mempool_alloc函数首先会尝试调用alloc方法从基本内存分配器获得一个内存元素, 如果分配成功则将不触及到内存池; 如果分配失败则将从内存池获得内存元素. 当内存不足时内存池有可能用尽, 此时如果__GFP_WAIT没有被置位, 则该函数就会阻塞当前进程直到有一个内存元素被释放到内存池为止.
非连续内存区管理
将内存区映射到一组连续的页框会更好地利用高速缓存并获得较低的平均访问时间, 但是当对内存区的请求不是很频繁的时候, 将连续的线性地址映射到非连续的页框会更好. 这种模式可以有效的避免外碎片, 但是缺点在于会打乱内核页表(?).
Linux在几个方面使用非连续内存区:
-
为活动的交换区分配数据结构(参考第十七章激活和禁用交换区)
-
为模块分配空间
-
为某些IO驱动程序分配缓冲区
非连续内存区的线性地址空间
下图显示了从PAGE_OFFSET开始的第4个GB的线性地址:
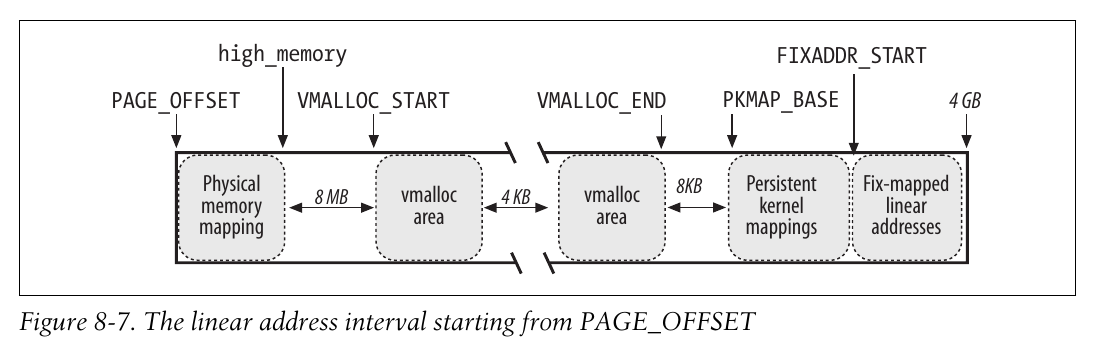
-
内存区开始的部分是对前896MB的RAM进行映射的线性地址, 这段物理内存末尾所对应的线性地址保存在
high_memory变量中 -
内存区从
PKMAP_BASE开始用于永久内核映射, 再往后则是固定映射的线性地址区域 -
中间的其余线性地址可以用于非连续内存区. 非连续内存区与开头的物理内存映射区域相距8MB, 与结尾的永久内核映射区域相距8KB, 这是为了捕获对内存的越界访问. 基于同样的理由, 在非连续内存区内也用4KB的安全区来隔离非连续的内存区.
非连续内存区的描述符
每个非连续内存其都有一个类型为vm_struct的描述符:

-
通过
next字段, 所有的非连续内存区描述符被插入到一个简单的链表, 链表第一个元素的地址在vmlist变量中. -
flags字段表示了该段内存的类型,VM_ALLOC表示使用vmalloc函数得到的页,VM_MAP表示使用vmap映射的已经被分配的页(参考 分配非连续内存区),VM_IOREMAP表示使用ioremap函数映射的硬件的板上内存.
非连续内存区的分配和释放
vmalloc函数给内核分配一个非连续内存区, 仅接受一个参数size表示请求内存区的大小.
在探究该函数之前, 首先看一下函数get_vm_area. 该函数在线性空间VMALLOC_START到VMALLOC_END之间查找一个空闲区域:
1#define IOREMAP_MAX_ORDER (7 + PAGE_SHIFT) /* 128 pages */
2
3struct vm_struct *__get_vm_area(unsigned long size, unsigned long flags,
4 unsigned long start, unsigned long end)
5{
6 struct vm_struct **p, *tmp, *area;
7 unsigned long align = 1;
8 unsigned long addr;
9
10 if (flags & VM_IOREMAP) {
11 int bit = fls(size);
12
13 if (bit > IOREMAP_MAX_ORDER)
14 bit = IOREMAP_MAX_ORDER;
15 else if (bit < PAGE_SHIFT)
16 bit = PAGE_SHIFT;
17
18 align = 1ul << bit;
19 }
20 addr = ALIGN(start, align);
21
22 area = kmalloc(sizeof(*area), GFP_KERNEL);
23 if (unlikely(!area))
24 return NULL;
25
26 /*
27 * We always allocate a guard page.
28 */
29 size += PAGE_SIZE;
30 if (unlikely(!size)) {
31 kfree (area);
32 return NULL;
33 }
34
35 write_lock(&vmlist_lock);
36 for (p = &vmlist; (tmp = *p) != NULL ;p = &tmp->next) {
37 if ((unsigned long)tmp->addr < addr) {
38 if((unsigned long)tmp->addr + tmp->size >= addr)
39 addr = ALIGN(tmp->size +
40 (unsigned long)tmp->addr, align);
41 continue;
42 }
43 if ((size + addr) < addr)
44 goto out;
45 if (size + addr <= (unsigned long)tmp->addr)
46 goto found;
47 addr = ALIGN(tmp->size + (unsigned long)tmp->addr, align);
48 if (addr > end - size)
49 goto out;
50 }
51
52found:
53 area->next = *p;
54 *p = area;
55
56 area->flags = flags;
57 area->addr = (void *)addr;
58 area->size = size;
59 area->pages = NULL;
60 area->nr_pages = 0;
61 area->phys_addr = 0;
62 write_unlock(&vmlist_lock);
63
64 return area;
65
66out:
67 write_unlock(&vmlist_lock);
68 kfree(area);
69 if (printk_ratelimit())
70 printk(KERN_WARNING "allocation failed: out of vmalloc space - use vmalloc=<size> to increase size.\n");
71 return NULL;
72}
73
74/**
75 * get_vm_area - reserve a contingous kernel virtual area
76 *
77 * @size: size of the area
78 * @flags: %VM_IOREMAP for I/O mappings or VM_ALLOC
79 *
80 * Search an area of @size in the kernel virtual mapping area,
81 * and reserved it for out purposes. Returns the area descriptor
82 * on success or %NULL on failure.
83 */
84struct vm_struct *get_vm_area(unsigned long size, unsigned long flags)
85{
86 return __get_vm_area(size, flags, VMALLOC_START, VMALLOC_END);
87}-
函数先通过
kmalloc函数为描述符分配一个内存区, 再将size增大一个页框的大小以保留安全区. -
获得
vmlist_lock锁, 循环遍历该链表下所有的非连续内存区, 找到符合条件的空白区域。此处应当注意:-
vmlist内部应该保证非连续内存的地址升序, 这一点虽然未从文中得到印证, 但是可以推断出来.
addr字段记录着每次搜索的可能起始地址, 循环将不断判断并更新该字段. 在每一次循环中, 如果当前内存区对应的tmp->addr字段大于addr字段, 则检查以addr为起点, 长度为size的区域是否仍然处于空白位置中(即L45), 如果成功则跳转到found分支中; 不然, 则将更新addr到该内存区的末尾位置, 重新进行搜索. 由于使用了ALIGN宏, 所以可能产生用力过猛的情况(?), 导致下一次循环取到的非连续内存区的地址甚至不如addr目前的值, 在这种情况下则将进行L37对应的判断分支: 如果本次循环取到的内存区间完全低于addr, continue即可; 不然, 如果addr恰被包含在该内存区间内, 则类似地更新addr到内存区末尾后continue即可. 通过这种循环, 就能不断地从小到大查询每块已有的非连续内存区前方的空白区域是否能够塞的下请求分配的新区域. -
如果循环全部完成后仍然没有跳至found分支, 这并不意味着失败, 因为只要进行过一次循环, 其内部就会判断是否有数值越界和范围越界(L43, 48); 既然完成了循环且未跳至out分支, 则说明此次分配合法, 只不过正好位于链表中最后一个元素后方的空白区域而已,
addr也已经由循环为我们更新到了相应的位置.
-
-
L53-54更新了链表的字段, 将新的内存区插入到链表中相应的位置; 利用到了双指针的方法, 比较神秘or精妙
接下来正式进入vmalloc函数:
1/**
2 * __vmalloc - allocate virtually contiguous memory
3 *
4 * @size: allocation size
5 * @gfp_mask: flags for the page level allocator
6 * @prot: protection mask for the allocated pages
7 *
8 * Allocate enough pages to cover @size from the page level
9 * allocator with @gfp_mask flags. Map them into contiguous
10 * kernel virtual space, using a pagetable protection of @prot.
11 */
12void *__vmalloc(unsigned long size, int gfp_mask, pgprot_t prot)
13{
14 struct vm_struct *area;
15 struct page **pages;
16 unsigned int nr_pages, array_size, i;
17
18 size = PAGE_ALIGN(size);
19 if (!size || (size >> PAGE_SHIFT) > num_physpages)
20 return NULL;
21
22 area = get_vm_area(size, VM_ALLOC);
23 if (!area)
24 return NULL;
25
26 nr_pages = size >> PAGE_SHIFT;
27 array_size = (nr_pages * sizeof(struct page *));
28
29 area->nr_pages = nr_pages;
30 /* Please note that the recursion is strictly bounded. */
31 if (array_size > PAGE_SIZE)
32 pages = __vmalloc(array_size, gfp_mask, PAGE_KERNEL);
33 else
34 pages = kmalloc(array_size, (gfp_mask & ~__GFP_HIGHMEM));
35 area->pages = pages;
36 if (!area->pages) {
37 remove_vm_area(area->addr);
38 kfree(area);
39 return NULL;
40 }
41 memset(area->pages, 0, array_size);
42
43 for (i = 0; i < area->nr_pages; i++) {
44 area->pages[i] = alloc_page(gfp_mask);
45 if (unlikely(!area->pages[i])) {
46 /* Successfully allocated i pages, free them in __vunmap() */
47 area->nr_pages = i;
48 goto fail;
49 }
50 }
51
52 if (map_vm_area(area, prot, &pages))
53 goto fail;
54 return area->addr;
55
56fail:
57 vfree(area->addr);
58 return NULL;
59}
60
61EXPORT_SYMBOL(__vmalloc);
62
63/**
64 * vmalloc - allocate virtually contiguous memory
65 *
66 * @size: allocation size
67 *
68 * Allocate enough pages to cover @size from the page level
69 * allocator and map them into contiguous kernel virtual space.
70 *
71 * For tight cotrol over page level allocator and protection flags
72 * use __vmalloc() instead.
73 */
74void *vmalloc(unsigned long size)
75{
76 return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
77}vmalloc大部分的代码比较简单, 可以注意以下几个地方:
-
该函数首先将计算所有的页描述符所占用的空间, 如果需要的空间超过一页, 则递归地调用
__vmalloc函数; 不然, 则调用kmalloc函数分配页内内存即可.(L31-34) -
根据总大小分配好页描述占用的空间后, 通过
alloc_page创建每一个页描述符; 如果中途发生失败, 保留成功创建的数量于对应字段中, 跳转到fail分支即可. 注意, 必须使用area->pages数组的原因是页框可能在高端内存管理区.
需要单独说明L52的map_vm_area函数. 目前已经获得了连续的线性地址空间以及一组非连续的页框来映射这些线性地址, 最后至关重要的步骤是修改内核使用的页表项, 这就是该函数将要做的:
1int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
2{
3 unsigned long address = (unsigned long) area->addr;
4 unsigned long end = address + (area->size-PAGE_SIZE);
5 unsigned long next;
6 pgd_t *pgd;
7 int err = 0;
8 int i;
9
10 pgd = pgd_offset_k(address);
11 spin_lock(&init_mm.page_table_lock);
12 for (i = pgd_index(address); i <= pgd_index(end-1); i++) {
13 pud_t *pud = pud_alloc(&init_mm, pgd, address);
14 if (!pud) {
15 err = -ENOMEM;
16 break;
17 }
18 next = (address + PGDIR_SIZE) & PGDIR_MASK;
19 if (next < address || next > end)
20 next = end;
21 if (map_area_pud(pud, address, next, prot, pages)) {
22 err = -ENOMEM;
23 break;
24 }
25
26 address = next;
27 pgd++;
28 }
29
30 spin_unlock(&init_mm.page_table_lock);
31 flush_cache_vmap((unsigned long) area->addr, end);
32 return err;
33}该函数接受3个参数, 其中prot总被设置为0x63, 对应着Present, Accessed, Read/Write, Dirty, 而pages是一个三指针, 指向指针数组.
(留坑, 待不久后学习完页表的相关代码后回头补充.)
除了vmalloc函数, 非连续内存区还能由vmalloc_32()函数分配, 该函数只从DMA和NORMAL区中分配页框.
1/**
2 * vmalloc_32 - allocate virtually contiguous memory (32bit addressable)
3 *
4 * @size: allocation size
5 *
6 * Allocate enough 32bit PA addressable pages to cover @size from the
7 * page level allocator and map them into contiguous kernel virtual space.
8 */
9void *vmalloc_32(unsigned long size)
10{
11 return __vmalloc(size, GFP_KERNEL, PAGE_KERNEL);
12}Linux2.6还特别提供了一个vmap()函数, 该函数映射非连续内存区中已经分配的页框; 本质上该函数与vmalloc类似, 但是它不分配一个新的页框.
1/**
2 * vmap - map an array of pages into virtually contiguous space
3 *
4 * @pages: array of page pointers
5 * @count: number of pages to map
6 * @flags: vm_area->flags
7 * @prot: page protection for the mapping
8 *
9 * Maps @count pages from @pages into contiguous kernel virtual
10 * space.
11 */
12void *vmap(struct page **pages, unsigned int count,
13 unsigned long flags, pgprot_t prot)
14{
15 struct vm_struct *area;
16
17 if (count > num_physpages)
18 return NULL;
19
20 area = get_vm_area((count << PAGE_SHIFT), flags);
21 if (!area)
22 return NULL;
23 if (map_vm_area(area, prot, &pages)) {
24 vunmap(area->addr);
25 return NULL;
26 }
27
28 return area->addr;
29}vfree函数用于使用vmalloc或是vmalloc_32创建的非连续内存区, 而vunmap函数用于释放vmap创建的内存区. 两个函数都使用将要释放的内存区的起始线性地址作为唯一参数, 都依赖__vunmap函数进行实质性的工作.
1/**
2 * vfree - release memory allocated by vmalloc()
3 *
4 * @addr: memory base address
5 *
6 * Free the virtually contiguous memory area starting at @addr, as
7 * obtained from vmalloc(), vmalloc_32() or __vmalloc().
8 *
9 * May not be called in interrupt context.
10 */
11void vfree(void *addr)
12{
13 BUG_ON(in_interrupt());
14 __vunmap(addr, 1);
15}
16
17/**
18 * vunmap - release virtual mapping obtained by vmap()
19 *
20 * @addr: memory base address
21 *
22 * Free the virtually contiguous memory area starting at @addr,
23 * which was created from the page array passed to vmap().
24 *
25 * May not be called in interrupt context.
26 */
27void vunmap(void *addr)
28{
29 BUG_ON(in_interrupt());
30 __vunmap(addr, 0);
31}具体的代码分析留坑, 理由同上.
1void __vunmap(void *addr, int deallocate_pages)
2{
3 struct vm_struct *area;
4
5 if (!addr)
6 return;
7
8 if ((PAGE_SIZE-1) & (unsigned long)addr) {
9 printk(KERN_ERR "Trying to vfree() bad address (%p)\n", addr);
10 WARN_ON(1);
11 return;
12 }
13
14 area = remove_vm_area(addr);
15 if (unlikely(!area)) {
16 printk(KERN_ERR "Trying to vfree() nonexistent vm area (%p)\n",
17 addr);
18 WARN_ON(1);
19 return;
20 }
21
22 if (deallocate_pages) {
23 int i;
24
25 for (i = 0; i < area->nr_pages; i++) {
26 if (unlikely(!area->pages[i]))
27 BUG();
28 __free_page(area->pages[i]);
29 }
30
31 if (area->nr_pages > PAGE_SIZE/sizeof(struct page *))
32 vfree(area->pages);
33 else
34 kfree(area->pages);
35 }
36
37 kfree(area);
38 return;
39}坑
一个宏观的说明 https://zhuanlan.zhihu.com/p/149581303
preempt_count 临时内核映射
page <-> pfn
页框的分配 整体流程?
kmem_cache_init 和 kmem_cache_create
kmalloc?? 该函数到底处于伙伴系统or slabh系统中的什么位置? 其位于内核中的内存分配模块又是什么位置?
map_vm_area函数
非连续内存区的分配和释放
