中断被定义为一个事件, 该事件将改变处理的指令执行顺序.
中断分为同步中断和异步中断, 在Intel微处理器手册中, 它们分别被称为异常和中断.
中断是由定时器或IO设备产生的; 而异常是由程序的错误产生的, 或是由内核必须处理的异常条件(如缺页, 对内核服务的请求等)产生的, 前者内核通过发送信号来处理, 后者则需要内核执行恢复异常的所有步骤.
中断信号的作用
中断信号提供了一种特殊的方式, 让CPU切换到一个新的活动. 为此就需要在内核态堆栈保存程序计数器即eip和cs的内容, 并把与中断类型相关的地址放进程序计数器.
这与进程中的上下文切换类似, 但是存在一个明显的差异: 中断处理程序执行的代码不是一个进程, 而只是一条内核控制路径. 作为一个内核控制路径, 中断处理程序比一般的进程要轻(light).
中断处理是内核执行的最敏感的任务之一, 其必须满足:
-
由于中断随时可能发生, 因而中断应当尽可能快的处理完, 尽量推迟更进一步的处理.
-
内核在处理中断时, 可能会出现另一个中断, 内核应当允许中断处理程序的嵌套发生, 这能维持更多的IO设备处于忙状态.
-
尽管内核允许一些中断嵌套, 但是仍然存在一些临界区代码, 其中中断必须被禁止.
中断和异常
Intel文档将中断和异常分为下述几类:
-
中断
-
可屏蔽中断: IO设备发出的所与IRQ都产生可屏蔽中断, 这种中断拥有屏蔽的和非屏蔽的两种状态, 只要中断还是被屏蔽的, CU就忽略它.
-
非屏蔽中断: 只有危机事件(如硬件故障)才会引起非屏蔽中断, 这种中断由CPU辨认.
-
-
异常
-
处理器探测异常: 当CPU执行指令时探测到一个反常条件产生的异常, 根据控制单元在发生异常时向
eip保存的值可以进一步分为3组:-
故障(fault): 通常可以纠正; 一旦纠正, 程序就可以不实连贯性的重新开始. 保存在
eip中的值就是引起故障的指令地址, 如缺页中断, 只要处理程序能够纠正反常条件, 重新执行同一指令是有必要的 -
陷阱(trap): 保存在
eip的是一个即将要执行的指令地址, 只有没有必要重新执行结束的指令时才触发陷阱, 陷阱的主要目的是调试程序. -
异常中止(abort): 发生了严重的错误, 控制单元出现问题, 不能在
eip中保存异常指令的确切位置. 异常中止用于报告严重错误, 该中断信号是紧急信号, 用来将控制权切换到相应的异常中止处理程序, 该程序除了终止对应的进程外别无选择.
-
-
编程异常: 该异常在编程者发出请求时发生, 由
int或者int3触发, 或是由当into(检查溢出)和bound(检查越界)指令检查的条件不为真时触发. 这种异常通常被称为软中断, 常用于系统调用以及给调试程序通报特定事件.
-
IRQ和中断
每个能发出中断请求的硬件设备控制器都有一条IRQ(Interrupt ReQuest)的输出线, 所有的IRQ线都输入到可编程中断控制器(Programmable Interrupt Controller, PIC)中, PIC执行下列动作:
中文版翻译的一塌糊涂, raised signal应该是上升沿信号的意思, 中文版翻译为了引发信号…
- Monitors the IRQ lines, checking for raised signals. If two or more IRQ lines are raised, selects the one having the lower pin number.
- If a raised signal occurs on an IRQ line: a. Converts the raised signal received into a corresponding vector. b. Stores the vector in an Interrupt Controller I/O port, thus allowing the CPU to read it via the data bus. c. Sends a raised signal to the processor INTR pin—that is, issues an interrupt. d. Waits until the CPU acknowledges the interrupt signal by writing into one of the Programmable Interrupt Controllers (PIC) I/O ports; when this occurs, clears the INTR line.
- Goes back to step 1.
IRQ线从0开始编号, IRQn对应的默认向量为n+32.
此外, 可以有选择性的禁止每条IRQ线. 禁止的中断不会丢失, 一旦被激活后PIC将又把它们送往CPU; 这个特点允许中断处理程序逐次地处理同一类型的IRQ. 需要注意, 这里的禁止不同于可屏蔽中断的全局屏蔽/非屏蔽. 当eflags的IF标志清零后, PIC发布的每个可屏蔽中断都将被暂时忽略.cli和sti汇编指令分别清除和设置该标志.
传统的PIC由两片8259A风格的芯片级联在一起, 每个芯片可以处理8个IRQ输入, 而从PIC的INT输出到主PIC的IRQ2引脚, 因而总共最多有15个IRQ输入.
梦回微机原理
高级PIC
如果系统为多CPU结构, 上述的简单方式将不再有效, 此时需要更加复杂度PIC.
为了充分发挥SMP(Symmetric Multi-Processing, 对称多处理)体系架构的并行性, Intel从奔腾III引用了一种名为I/O高级可编程中断控制器(I/O APIC)的新组件, 用于代替老式的8259A. 80x86微处理器所有的CPU都含有一个本地APIC, 所有的本地APIC都连接到一个外部I/O APIC, 形成一个多APIC的系统.
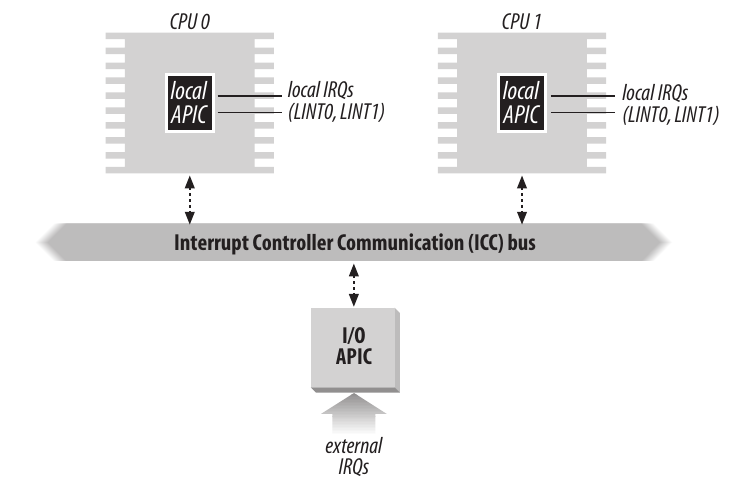
本地APIC包含32位的寄存器, 一个内部时钟, 一个本地定时设备以及为本地APIC中断保留的两条IRQ线LINT0和LINT1; 外部的I/O APIC包含一组24条IRQ线, 一张24项的中断重定向表, 可编程寄存器, 以及通过APIC总线接受和发送APIC信息的信息单元.
与8259A不同, APIC的中断优先级不与引脚号有关, 中断重定向表中每一项都可以被单独编程以指明中断向量, 优先级, 目标处理器以及选择处理器的方式. 重定向表将外部IRQ信号转换为一条消息, 通过总线将该消息发送到本地APIC单元.
中断请求以两种方式在CPU之间分发:
-
静态分发. IRQ信号传递给表项中列出的本地APIC, 中断立刻传递给特定的一个或一组CPU.
-
动态分发. IRQ信号将传递给当前任务优先级最低的CPU. 每个本地APIC有一个优先级寄存器TPR, 用于计算当前进程的优先级; 内核中发生进程切换将会修改这个寄存器.
- 如果多个CPU拥有相同的最低优先级, 则采用仲裁技术. 本地APIC拥有一个仲裁寄存器, 范围为0-15. 每当中断传递给某个CPU时, 该寄存器就归零, 而其余CPU的仲裁寄存器加一; 一旦寄存器内容超过15, 则将其设置为获胜CPU之前的仲裁等级加1. 因而中断以轮转方式在CPU之间分发..(?)
除此之外, 多APIC系统还允许CPU产生处理器间中断(Inter-Processor Interrupt, IPI). 当一个CPU希望将中断发给另一个CPU时, 就在自己本地APIC中的中断指令寄存器中存放该中断向量和目标APIC的标识符, 然后通过总线向目标发送一条消息, 从而使得自己的CPU发出一个相应的中断. IPI是SMP体系中至关重要的组成部分, 并由Linux有效利用来在CPU之间交换消息.
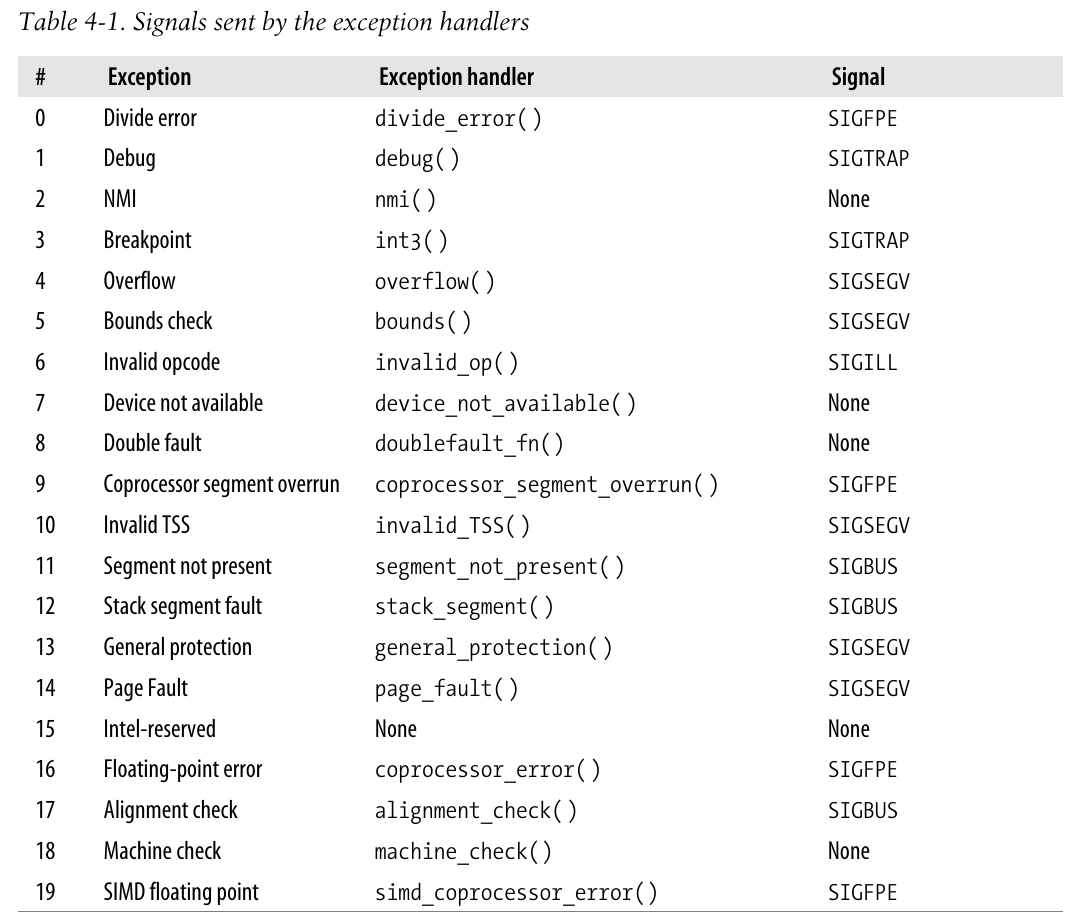
异常
x86处理器发布了约20种不同的异常, 内核必须为每个异常提供专门的处理程序.
下面给出这些异常的简单描述:
- “Divide error” (fault) Raised when a program issues an integer division by 0.
- “Debug” (trap or fault) Raised when the TF flag of eflags is set (quite useful to implement single-step execution of a debugged program) or when the address of an instruction or operand falls within the range of an active debug register (see the section “Hardware Context” in Chapter 3).
- Not used Reserved for nonmaskable interrupts (those that use the NMI pin).
- “Breakpoint” (trap) Caused by an int3 (breakpoint) instruction (usually inserted by a debugger).
- “Overflow” (trap) An into (check for overflow) instruction has been executed while the OF (overflow) flag of eflags is set.
- “Bounds check” (fault) A bound (check on address bound) instruction is executed with the operand outside of the valid address bounds.
- “Invalid opcode” (fault) The CPU execution unit has detected an invalid opcode (the part of the machine instruction that determines the operation performed).
- “Device not available” (fault) An ESCAPE, MMX, or SSE/SSE2 instruction has been executed with the TS flag of cr0 set (see the section “Saving and Loading the FPU, MMX, and XMM Regis- ters” in Chapter 3).
- “Double fault” (abort) Normally, when the CPU detects an exception while trying to call the handler for a prior exception, the two exceptions can be handled serially. In a few cases, however, the processor cannot handle them serially, so it raises this exception.
- “Coprocessor segment overrun” (abort) Problems with the external mathematical coprocessor (applies only to old 80386 microprocessors).
- “Invalid TSS” (fault) The CPU has attempted a context switch to a process having an invalid Task State Segment.
- “Segment not present” (fault) A reference was made to a segment not present in memory (one in which the Segment-Present flag of the Segment Descriptor was cleared).
- “Stack segment fault” (fault) The instruction attempted to exceed the stack segment limit, or the segment identified by ss is not present in memory.
- “General protection” (fault) One of the protection rules in the protected mode of the 80×86 has been violated.
- “Page Fault” (fault) The addressed page is not present in memory, the corresponding Page Table entry is null, or a violation of the paging protection mechanism has occurred.
- Reserved by Intel
- “Floating-point error” (fault) The floating-point unit integrated into the CPU chip has signaled an error condi- tion, such as numeric overflow or division by 0.*
- “Alignment check” (fault) The address of an operand is not correctly aligned (for instance, the address of a long integer is not a multiple of 4).
- “Machine check” (abort) A machine-check mechanism has detected a CPU or bus error.
- “SIMD floating point exception” (fault) The SSE or SSE2 unit integrated in the CPU chip has signaled an error condition on a floating-point operation.
20-31的值留作将来开发.
下表展示了对应的异常处理程序, 参考 异常处理
中断描述符表
中断描述符表(IDT)是一个系统表, 与每一个中断或异常向量相联系, 每一个向量在表中有相应的处理程序的入口地址.
IDT与GDT, LDT的格式非常相似, 表中每一项对应一个中断或异常向量, 每个向量有8字节, 因此最多需要256*8=2048 字节. (Q: 256是什么限制?)
idtr寄存器使IDT可以存放在任何位置, 其指定IDT的线性基址和最大长度; 在允许中断之前, 必须使用lidt汇编指令初始化idtr.
IDT包含三种类型的描述符, 下图给出了一共64位的含义; 值得注意其中40-43位的Type字段指明了描述符的类型:
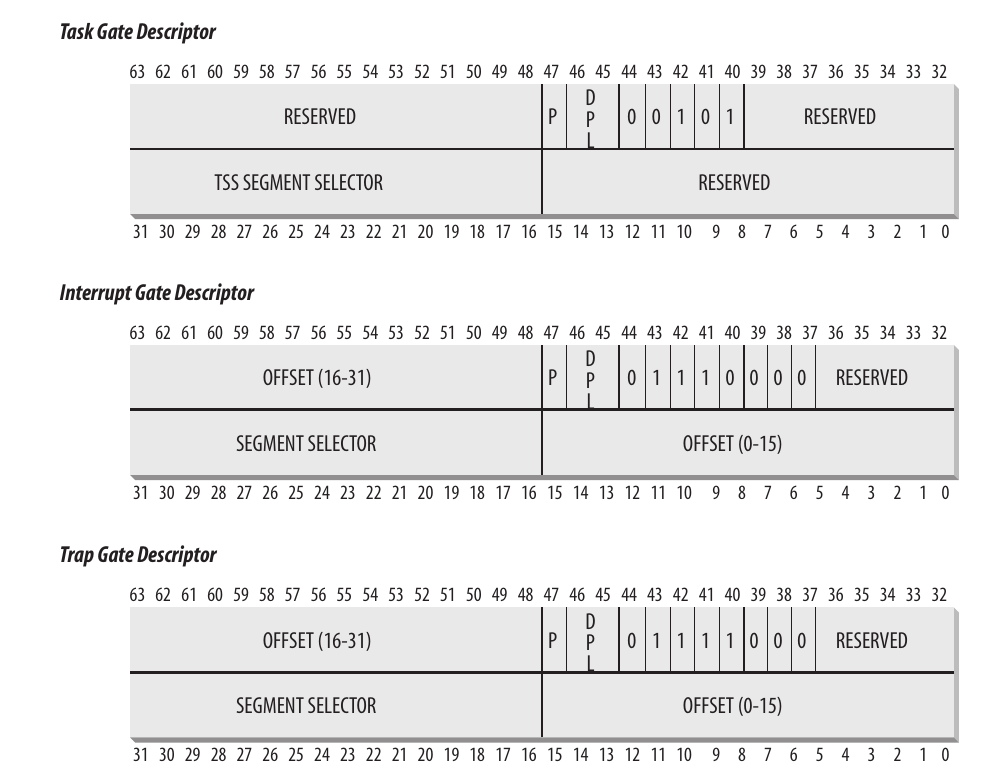
-
任务门: 中断发生时, 任务门中存放着必须取代当前进程的进程的TSS选择符.
-
中断门: 包含段选择符和处理程序的段内偏移. 控制权转移时, CPU清IF标志.
-
陷阱门: 与中断门类似, 但是转移控制权时不清IF标志.
其中P字段表示是否在内存中.
随后在 中断门,陷阱门以及系统门将看到, Linux利用中断门处理中断, 陷阱门处理异常.
中断和异常的硬件处理
下面说明CPU控制单元如何处理中断和异常. 假定内核已经初始化, CPU运行在保护模式下.
执行一条指令后, cs和eip寄存器包含下一条指令的逻辑地址. 在处理之前, CU检查前一条指令是否发生中断或异常, 如果发生, 则执行:
-
确定与中断或异常关联的向量$i, 0 \leq i \leq 255$
-
读
idtr寄存器指向的IDT表中的第$i$项, 假定是一个中断门或陷阱门 -
读
gdtr获得GDT基地址, 并在其中查找IDT表项对应的段描述符. -
检查中断是否被授权. 读当前特权级CPL(cs寄存器的低2位)和段描述符特权级DPL, 如果CPL低于DPL, 则产生13号异常General protectoin; 对于软中断, 则要进一步检查门描述符的DPL是否小于CPL, 如果小于也将产生13号异常, 这是用来避免用户程序访问特殊的陷阱门或中断门.
-
检查是否发生特权级的变化. 如CPL不同于段选择符的DPL, 则CU必须开始使用新的特权级相关的栈, 通过下述步骤完成这一点:
-
读
tr寄存器, 访问当前运行进程的TSS段 -
将与新特权级相关的栈段和栈指针的值载入
ss和esp寄存器, 其原有的值可以在TSS中找到. -
在新的栈中保存
ss和esp的旧值, 这些值定义了与旧特权级相关的栈的逻辑地址.
-
-
如果发生了一个fault类型的异常, 则用引起异常的指令地址装载
cs和eip, 从而使得之后该指令可以再次执行. -
在栈中保存
eflags,cs和eip. -
如果异常产生了一个硬件出错码, 则保存在栈中.
-
将IDT第$i$项对应的内容装载到
cs和eip寄存器中, 用于跳转到处理程序的逻辑地址上.
控制单元最后将跳转到处理程序进行执行, 执行完成后, 相应的处理程序一定会产生一条iret指令, 把控制权转交给此前被中断的程序, 这使得CU执行:
-
iret本质上将从栈中弹出cs,eip和eflags标志并将其装载到对应的寄存器中.IRET returns from an interrupt (hardware or software) by means of popping IP (or EIP), CS and the flags off the stack and then continuing execution from the new CS:IP.
如果一个硬件出错码在这些内容上方, 在执行
iret前必须先弹出该出错码. -
检查处理程序的CPL是否等于
cs中最低两位, 如果是, 则被中断的进程和处理程序在同一特权级, 处理结束; 不然, 进入下一步. -
从栈中装载
ss和esp寄存器, 回到旧特权级栈中. -
检查
ds, es, fs, gs段寄存器的内容, 如果其中某个寄存器包含段描述符, 且DPL小于CPL, 那么清该寄存器. 这样做是为了放置用户态的程序(CPL=3)利用内核以前所用的段寄存器(DPL=0)来访问内核地址空间.
中断和异常处理程序的嵌套
内核控制路径可以任意嵌套, 但是必须付出代价: 中断处理程序必须永不阻塞, 即意味着中断处理程序运行期间不得进行进程切换. 事实上, 嵌套的内核控制路径恢复执行时所需要的数据都存放在内核态堆栈中, 而内核态堆栈显然属于该进程.
大多数异常只在用户态发生, 唯一一种发生在内核态的是缺页异常. 由于缺页异常从不进一步引发一个异常, 因而与异常有关的嵌套至多两个, 第一个由系统调用引起, 第二个由缺页引起.
对于中断而言, 一个中断处理程序可以抢占其他的中断处理程序, 或是抢占异常处理程序(但从不抢占缺页处理, 因为这意味着进程切换); 相反, 异常从不抢占中断处理程序.
出于两个原因, Linux交错执行内核控制路径:
-
提高PIC和外部设备控制器的吞吐量. 当CPU在处理前一个中断时, 也能向新到来的中断发出相应.
-
实现没有优先级的中断模型, 使得每个中断程序都可以被另一个打断. 因而没有必要在硬件之间预定义优先级, 简化内核代码, 提高内核的可移植性.
在多处理器系统中, 几个内核控制路径可以并发进行. 此外, 与异常相关的内核控制路径可以由于进程切换移往其余CPU执行.
以上几节介绍了x86处理器在硬件级别对中断和异常的处理.
初始化中断描述符表
内核在启动中断之前, 必须要将IDT的初始地址装入idtr寄存器, 并初始化表中的每一项.
int指令允许用户态进程发出一个中断信号, 为了防止用户模拟非法的中断和异常, IDT将门描述符的DPL设置为0即可; 而当某些少数情况下, 用户需要发出一个编程异常, 将DPL字段设置为3即可.
下面, 我们将具体说明这些步骤:
中断门,陷阱门以及系统门
在 中断描述符表中提到, Intel提供了三种不同类型的门描述符; 但Linux使用稍有不同的细目分类:
-
中断门. 用户态进程不允许访问的一个Intel中断门(门的DPL为0); 所有Linux中断处理程序都通过中断门激活, 且限制在内核态.
-
系统门. 用户态进程可以访问的Intel陷阱门(门的DPL为3), 通过系统门来激活三个Linux异常处理程序, 向量为别为4, 5, 128; 因此, 用户态下可以使用
into,bound以及int $0x80三条汇编指令. -
系统中断门. 用户态进程可以访问的Intel中断门(门的DPL为3), 对应异常处理程序的向量为3, 因而用户态使用
int3汇编指令. -
陷阱门. 用户态进程不允许访问的Intel陷阱门(门的DPL为0). 大部分Linux异常处理程序都通过陷阱门激活.
-
任务门. 用户态进程不允许访问的Intel任务门(门的DPL为0). Linux通过任务门处理8号异常Double fault.
一些与体系结构相关的函数用于在IDT中插入门:
1#define _set_gate(gate_addr,type,dpl,addr,seg) \
2do { \
3 int __d0, __d1; \
4 __asm__ __volatile__ ("movw %%dx,%%ax\n\t" \
5 "movw %4,%%dx\n\t" \
6 "movl %%eax,%0\n\t" \
7 "movl %%edx,%1" \
8 :"=m" (*((long *) (gate_addr))), \
9 "=m" (*(1+(long *) (gate_addr))), "=&a" (__d0), "=&d" (__d1) \
10 :"i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
11 "3" ((char *) (addr)),"2" ((seg) << 16)); \
12} while (0)
13
14
15/*
16 * This needs to use 'idt_table' rather than 'idt', and
17 * thus use the _nonmapped_ version of the IDT, as the
18 * Pentium F0 0F bugfix can have resulted in the mapped
19 * IDT being write-protected.
20 */
21void set_intr_gate(unsigned int n, void *addr)
22{
23 _set_gate(idt_table+n,14,0,addr,__KERNEL_CS);
24}
25
26/*
27 * This routine sets up an interrupt gate at directory privilege level 3.
28 */
29static inline void set_system_intr_gate(unsigned int n, void *addr)
30{
31 _set_gate(idt_table+n, 14, 3, addr, __KERNEL_CS);
32}
33
34static void __init set_trap_gate(unsigned int n, void *addr)
35{
36 _set_gate(idt_table+n,15,0,addr,__KERNEL_CS);
37}
38
39static void __init set_system_gate(unsigned int n, void *addr)
40{
41 _set_gate(idt_table+n,15,3,addr,__KERNEL_CS);
42}
43
44static void __init set_task_gate(unsigned int n, unsigned int gdt_entry)
45{
46 _set_gate(idt_table+n,5,0,0,(gdt_entry<<3));
47}几个内联函数全部调用_set_gate宏的汇编指令, 其大致流程如下:
-
由于L9
&限制符的修饰, 原有的eax和edx先被输出到本地变量__d0, __d1. (?理解可能有误, 参考内联汇编博客) -
读入立即数(%4), 表项地址addr到
edx, 左移16位的段地址seg到eax -
将
edx低16位移动到eax中, 再将%4的低16位移动到edx -
将
eax全部32位内容移动到表项地址的前32位中. 此时eax低16位位段内偏移, 高16位为段选择符. -
将
edx全部32位移动到表项地址32-63位中. 此时edx低16位实际为立即数%4, 高16位保留未用. %4根据参数设置了对应的类别, DPL和P字段.
IDT的逐步初始化
计算机尚且处于实模式时, IDT被初始化并被BIOS使用. 但是一旦Linux开始接管, IDT就被移动到RAM中另一个区域, 并进行二次初始化(因为Linux不使用任何BIOS例程).
IDT存放在idt_table中, 有256个表项; 6B的idt_descr变量指明了IDT的大小和地址:
1idt_descr:
2 .word IDT_ENTRIES*8-1 # idt contains 256 entries
3 .long idt_table内核在初始化时, 通过setup_idt汇编函数使用同一个中断门ignore_int来填充这256个表项:
1/*
2 * setup_idt
3 *
4 * sets up a idt with 256 entries pointing to
5 * ignore_int, interrupt gates. It doesn't actually load
6 * idt - that can be done only after paging has been enabled
7 * and the kernel moved to PAGE_OFFSET. Interrupts
8 * are enabled elsewhere, when we can be relatively
9 * sure everything is ok.
10 *
11 * Warning: %esi is live across this function.
12 */
13setup_idt:
14 lea ignore_int,%edx
15 movl $(__KERNEL_CS << 16),%eax
16 movw %dx,%ax /* selector = 0x0010 = cs */
17 movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
18
19 lea idt_table,%edi
20 mov $256,%ecx
21rp_sidt:
22 movl %eax,(%edi)
23 movl %edx,4(%edi)
24 addl $8,%edi
25 dec %ecx
26 jne rp_sidt
27 ret
28
29/* This is the default interrupt "handler" :-) */
30 ALIGN
31ignore_int:
32 cld
33 pushl %eax
34 pushl %ecx
35 pushl %edx
36 pushl %es
37 pushl %ds
38 movl $(__KERNEL_DS),%eax
39 movl %eax,%ds
40 movl %eax,%es
41 pushl 16(%esp)
42 pushl 24(%esp)
43 pushl 32(%esp)
44 pushl 40(%esp)
45 pushl $int_msg
46 call printk
47 addl $(5*4),%esp
48 popl %ds
49 popl %es
50 popl %edx
51 popl %ecx
52 popl %eax
53 iret类似于上一节_set_gate代码, setup_idt代码将段描述符和偏移存储在eax中, 几个特殊字段对应存放在edx低16位中, 随后进行256次循环, 写入到对应的表项中.
ignore_int将通过printk输出"Unknown interrupt"消息, 该处理程序应当从不被执行, 不然则意味着要么硬件出现了问题(IO设备正产生一个未料到的中断)要么内核出现了问题(中断或异常未被正确的处理).
异常处理
CPU的大部分异常被解释为出错条件, 当这类异常发生时, 内核将向引起异常的进程发送一个信号通知该反常事件, 进程将会尝试从错误中恢复过来或是终止运行.
还有两种情况下Linux利用CPU异常来更有效管理硬件资源. 一种是Lazy保存加载FPU等寄存器时的Device not avaliable异常, 另一种是缺页异常, 该异常将推迟给进程分配新的页框, 一直推迟到不能再推迟为止, 相应的异常处理程序也很复杂, 参考第九章.
为了处理异常, 必须要对IDT进行适当的初始化. trap_init函数将异常处理的函数插入到对象的表项中:
1void __init trap_init(void)
2{
3#ifdef CONFIG_EISA
4 void __iomem *p = ioremap(0x0FFFD9, 4);
5 if (readl(p) == 'E'+('I'<<8)+('S'<<16)+('A'<<24)) {
6 EISA_bus = 1;
7 }
8 iounmap(p);
9#endif
10
11#ifdef CONFIG_X86_LOCAL_APIC
12 init_apic_mappings();
13#endif
14
15 set_trap_gate(0,÷_error);
16 set_intr_gate(1,&debug);
17 set_intr_gate(2,&nmi);
18 set_system_intr_gate(3, &int3); /* int3-5 can be called from all */
19 set_system_gate(4,&overflow);
20 set_system_gate(5,&bounds);
21 set_trap_gate(6,&invalid_op);
22 set_trap_gate(7,&device_not_available);
23 set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
24 set_trap_gate(9,&coprocessor_segment_overrun);
25 set_trap_gate(10,&invalid_TSS);
26 set_trap_gate(11,&segment_not_present);
27 set_trap_gate(12,&stack_segment);
28 set_trap_gate(13,&general_protection);
29 set_intr_gate(14,&page_fault);
30 set_trap_gate(15,&spurious_interrupt_bug);
31 set_trap_gate(16,&coprocessor_error);
32 set_trap_gate(17,&alignment_check);
33#ifdef CONFIG_X86_MCE
34 set_trap_gate(18,&machine_check);
35#endif
36 set_trap_gate(19,&simd_coprocessor_error);
37
38 set_system_gate(SYSCALL_VECTOR,&system_call);
39
40 /*
41 * Should be a barrier for any external CPU state.
42 */
43 cpu_init();
44
45 trap_init_hook();
46}其中需要特别注意的是8号异常Double fault的任务门: 产生该异常时说明内核发生了严重的非法操作, 此时无法确定esp寄存器的值是否正确, 因而通过该任务门指向GDT中专门的TSS段, 通过段中内容装载esp和eip寄存器, 最终结果是, 处理器在自己的私有栈上执行doublefault_fn异常处理程序.
下面将简单说明一个典型的异常处理程序被调用时会发生什么.
以0号异常为例, 下面是其处理程序的汇编代码:
1ENTRY(divide_error)
2 pushl $0 # no error code
3 pushl $do_divide_error
4 ALIGN
5error_code:
6 pushl %ds
7 pushl %eax
8 xorl %eax, %eax
9 pushl %ebp
10 pushl %edi
11 pushl %esi
12 pushl %edx
13 decl %eax # eax = -1
14 pushl %ecx
15 pushl %ebx
16 cld
17 movl %es, %ecx
18 movl ES(%esp), %edi # get the function address
19 movl ORIG_EAX(%esp), %edx # get the error code
20 movl %eax, ORIG_EAX(%esp)
21 movl %ecx, ES(%esp)
22 movl $(__USER_DS), %ecx
23 movl %ecx, %ds
24 movl %ecx, %es
25 movl %esp,%eax # pt_regs pointer
26 call *%edi
27 jmp ret_from_exception-
在一些异常处理程序的开始, CPU没有自动压入一个硬件错误码到栈中, 则人为通过
pushl $0压入一个空值占位. -
然后将高级C函数的地址压入栈中, 其名称由异常处理程序名和
do_前缀构成. -
除了Device not avaliable异常, 其余异常处理程序都会jmp到
error_code代码段中:-
该代码段首先存储若干C高级函数可能用到的寄存器值到栈中
-
通过
cld清除eflags的DF标志, 使得调用字符串指令会自动增加edi和esi的值 -
将栈中的硬件出错码存放在
edx寄存器中, 随后将-1写入到栈中该位置 -
将栈中的处理函数地址存放到
edi中, 随后将es段寄存器的内容写入栈中该位置 -
将用户数据段(__USER_DS)的选择符拷贝到
ds,es寄存器中. -
将
esp复制到eax后, 调用存放在edi的函数, 函数按照顺序从寄存器eax(栈顶地址)和edx(硬件出错码)取数据.
-
-
随后看到
do_handler_name类型的C语言函数, 这类函数通过宏定义, 存在于arch/i386/kernel/trap.c文件中. 以0号异常处理程序为例:c1#define DO_VM86_ERROR_INFO(trapnr, signr, str, name, sicode, siaddr) \ 2fastcall void do_##name(struct pt_regs * regs, long error_code) \ 3{ \ 4 siginfo_t info; \ 5 info.si_signo = signr; \ 6 info.si_errno = 0; \ 7 info.si_code = sicode; \ 8 info.si_addr = (void __user *)siaddr; \ 9 if (notify_die(DIE_TRAP, str, regs, error_code, trapnr, signr) \ 10 == NOTIFY_STOP) \ 11 return; \ 12 do_trap(trapnr, signr, str, 1, regs, error_code, &info); \ 13} 14 15DO_VM86_ERROR_INFO( 0, SIGFPE, "divide error", divide_error, FPE_INTDIV, regs->eip)大部分函数将硬件出错码和异常向量存放在当前进程的描述符后, 向该进程发送一个信号进行通知. 这里不细究具体的函数和几个函数的定义宏.
异常处理程序结束后, 当前进程就关注该信号. 该信号要么由进程自己处理, 要么由内核处理, 内核通常会杀死该进程.
此外, 异常处理程序会检查异常发生在用户态还是内核态, 如果处于内核态还会检查是否由于系统调用的无效参数导致(在第十章将看到内核如何防御受到无效的系统调用参数的攻击). 出现在内核态的其余异常均是由于内核Bug导致, 为了避免硬盘上的数据崩溃处理程序将调用
die()在控制台打印出所有的CPU寄存器内容(这种转储被称为kernel opps), 并调用do_exit终止当前进程. -
C语言函数完成后, 将通过jmp跳转到
ret_from_exception函数, 该函数将在 从中断和异常返回说明.
中断处理
对于异常而言, 内核只需要给对应进程发送一个Unix信号, 即可完成异常处理. 要采取的行动被延迟到进程收到信号为止, 因而内核能够很快处理异常.
但是这种方法并不适合中断. 中断到来时, 当前运行的进程可能与之毫无关系, 向当前进程发送Unix信号是无意义的.
中断处理取决于中断类型, 有以下三种主要的中断类型:
-
I/O中断.
-
时钟中断. 大部分时钟中断是作为IO中断处理的, 在第六章再会说明时钟中断.
-
处理器间中断. 多处理器系统中一个CPU对另一个发出一个中断.
I/O中断
IO中断处理程序需要足够灵活来同时给多个设备提供服务, 这种灵活主要通过两种方式实现:
-
IRQ共享. 中断处理程序执行多个中断服务例程(interrupt service routine, ISR), 由于事先不知道哪个设备产生IRQ, 因而所有例程都将执行以验证其对应的设备是否需要关注.
-
IRQ动态分配. 一条IRQ线在最后才与一个设备驱动程序相关联.
此外, 中断发生时, 并不是所有操作都是同样紧迫的. 中断处理程序不能执行任何阻塞操作, 因而其应该把时间长的, 非重要的任务延后执行. 因此, Linux对中断后要执行的操作进行了分类:
-
紧急的(Critical). 如PIC应答中断, 对PIC或设备控制器重编程, 修改设备和处理器共享的数据结构等. 紧急操作要立即执行, 且处在禁止可屏蔽中断的情况下.
-
非紧急的(Noncritical). 如修改那些只有处理器会访问的数据结构. 这些操作也要立即执行, 但是需要打开中断.
-
非紧急可延迟的(Noncritical deferrable). 如将缓存区的内容拷贝到进程地址空间中. 这类操作由独立的函数执行, 参考 软中断及tasklet
中断向量
下表给出了Linux中一些特定中断向量的用途:
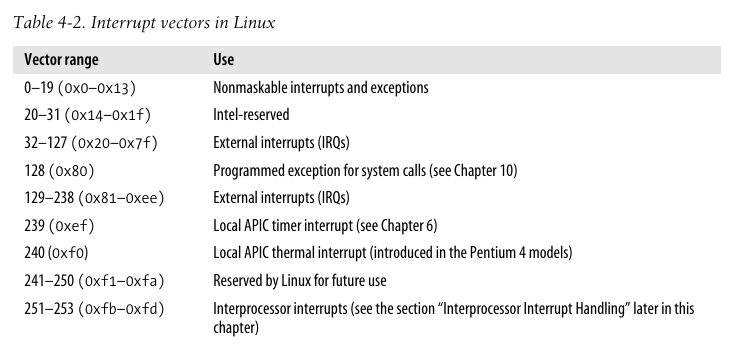

内核在初始化设备驱动程序时将会将IRQ号与IO设备之间对应起来, 参考第十三章.
IRQ数据结构
每个中断向量都有一个struct irq_desc类型的描述符, 所有描述符组成irq_desc数组.
1/*
2 * This is the "IRQ descriptor", which contains various information
3 * about the irq, including what kind of hardware handling it has,
4 * whether it is disabled etc etc.
5 *
6 * Pad this out to 32 bytes for cache and indexing reasons.
7 */
8typedef struct irq_desc {
9 hw_irq_controller *handler;
10 void *handler_data;
11 struct irqaction *action; /* IRQ action list */
12 unsigned int status; /* IRQ status */
13 unsigned int depth; /* nested irq disables */
14 unsigned int irq_count; /* For detecting broken interrupts */
15 unsigned int irqs_unhandled;
16 spinlock_t lock;
17} ____cacheline_aligned irq_desc_t;
18
19extern irq_desc_t irq_desc [NR_IRQS];
如果一个中断内核没有处理, 那么这就是一个意外中断, 这意味着相应的ISR不存在, 或是与之相关的所有ISR都无法识别出是否是自己的硬件所发出的中断. 内核会统计从IRQ中接受到的意外中断的数量, 如果有故障的设备没完没了地发送中断, 内核就将禁用该IRQ线, 判断方法为: 中断发生次数irq_count为100000次时, 意外中断的次数irqs_unhandled超过99900次.
下表给出了描述IRQ状态status的一些标志:

handler字段类型hw_irq_controller为:
1/*
2 * Interrupt controller descriptor. This is all we need
3 * to describe about the low-level hardware.
4 */
5struct hw_interrupt_type {
6 const char * typename;
7 unsigned int (*startup)(unsigned int irq);
8 void (*shutdown)(unsigned int irq);
9 void (*enable)(unsigned int irq);
10 void (*disable)(unsigned int irq);
11 void (*ack)(unsigned int irq);
12 void (*end)(unsigned int irq);
13 void (*set_affinity)(unsigned int irq, cpumask_t dest);
14};
15
16typedef struct hw_interrupt_type hw_irq_controller;-
typename是PIC的名字 -
startup和shutdown用于启动和关闭芯片的IRQ线;enable和disable用于启用和禁用IRQ线. 在8259A下这两对芯片作用一样. -
ack用于将适当的字节发往8259A的IO端口以回应IRQ请求 -
end用于在IRQ中断处理程序终止时被调用. -
set_affinity用于在多处理器系统中声明特定IRQ所在CPU的亲和力.
如前所述, 多个设备能共享一个IRQ线, 因此内核需要维护多个irqaction描述符, 其中每个描述符对应一个特定的硬件和一个特定的中断:
1struct irqaction {
2 irqreturn_t (*handler)(int, void *, struct pt_regs *);
3 unsigned long flags;
4 cpumask_t mask;
5 const char *name;
6 void *dev_id;
7 struct irqaction *next;
8 int irq;
9 struct proc_dir_entry *dir;
10};

最后一个涉及到的数据结构为irq_stat数组, 该数组元素数量为CPU数量, 每个元素为irq_cpustat_t, 包含几个计数器和一组记录内核正在做什么的标志:
1typedef struct {
2 unsigned int __softirq_pending;
3 unsigned long idle_timestamp;
4 unsigned int __nmi_count; /* arch dependent */
5 unsigned int apic_timer_irqs; /* arch dependent */
6} ____cacheline_aligned irq_cpustat_t;
7
8irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
IRQ在多处理器系统上的分发
硬件产生一个中断信号后, 多APIC系统将选择其中一个CPU并将信号传递给它的本地APIC, 本地APIC再依次中断其CPU. 这些全部由硬件自动完成, 初始化完成后内核就无需再费心.
然而一些情况下, 硬件无法公平地在处理器间平均分配中断, linux26利用kirqd这一特殊内核线程来纠正对CPU的IRQ分配.
-
内核线程通过修改IO APIC的重定向表项来讲中断信号发送到某个特定的CPU上, 通过函数
set_ioapic_affinity_irq实现. 该函数有2个参数: 被重定向的IRQ向量以及一个32位的掩码(表示可以接受该IRQ的CPU). -
通过
do_irq_balance追踪最近时间间隔内每个CPU接收中断的次数, 并进行负载均衡.
具体源码不予深究.
多类型的内核栈
根据编译选项不同, thread_union结构可能占据1个或2个页框.
当其占据8KB时, 该内核站被用于处理所有类型的内核控制路径: 异常, 中断和可延迟函数(详见 软中断及tasklet)
而当其只占据4KB时, 内核就使用3种类型的内核栈:
-
异常栈, 用于处理包括系统调用的异常. 这个栈包含在
thread_union结构中, 因而与进程相关联 -
硬中断请求栈, 用于处理中断.
-
软中断请求栈, 用于处理软中断.
硬中断和软中断请求分别全部存放在hardirq_ctx和softirq_ctx数组中, 数组元素是类似于thread_info的联合体. 每个CPU都有一个硬中断请求栈和一个软中断请求栈, 栈也是从高到低增长, 联合体占据一个单独的页框.
1#ifdef CONFIG_4KSTACKS
2/*
3 * per-CPU IRQ handling contexts (thread information and stack)
4 */
5union irq_ctx {
6 struct thread_info tinfo;
7 u32 stack[THREAD_SIZE/sizeof(u32)];
8};
9
10static union irq_ctx *hardirq_ctx[NR_CPUS];
11static union irq_ctx *softirq_ctx[NR_CPUS];
12#endif中断处理程序
在系统初始化时, init_IRQ()函数将每个IRQ主描述符的status字段设置为IRQ_DISABLED, 并通过interrupt数组中的函数地址替换由setup_idt()所建立的中断门:
1for (i = 0; i < (NR_VECTORS - FIRST_EXTERNAL_VECTOR); i++) {
2 int vector = FIRST_EXTERNAL_VECTOR + i;
3 if (i >= NR_IRQS)
4 break;
5 if (vector != SYSCALL_VECTOR)
6 set_intr_gate(vector, interrupt[i]);interrupt数组在arch/i386/kernel/head.S汇编中建立:
1/*
2 * Build the entry stubs and pointer table with
3 * some assembler magic.
4 */
5.data
6ENTRY(interrupt)
7.text
8
9vector=0
10ENTRY(irq_entries_start)
11.rept NR_IRQS
12 ALIGN
131: pushl $vector-256
14 jmp common_interrupt
15
16common_interrupt:
17 SAVE_ALL
18 movl %esp,%eax
19 call do_IRQ
20 jmp ret_from_intr-
L13的指令将中断号减去256后压栈, 这是由于内核使用负数表示中断, 正数表示系统调用.
-
随后跳转执行通用代码
common_interrupt. 首先执行的是SAVE_ALL, 用于保存所有寄存器. 它将保存所有可能用到的CPU寄存器, 但不保存eflags, eip, cs, ss, esp, 因为这些由硬件自动保存.(参考 中断和异常的硬件处理); 该代码段还将把__USER_DS装载到ds, es中.Text1#define SAVE_ALL \ 2 cld; \ 3 pushl %es; \ 4 pushl %ds; \ 5 pushl %eax; \ 6 pushl %ebp; \ 7 pushl %edi; \ 8 pushl %esi; \ 9 pushl %edx; \ 10 pushl %ecx; \ 11 pushl %ebx; \ 12 movl $(__USER_DS), %edx; \ 13 movl %edx, %ds; \ 14 movl %edx, %es; -
将栈顶指针存放到
eax寄存器后, 调用do_IRQ函数.
1/*
2* do_IRQ handles all normal device IRQ's (the special
3* SMP cross-CPU interrupts have their own specific
4* handlers).
5*/
6fastcall unsigned int do_IRQ(struct pt_regs *regs)
7{
8 /* high bits used in ret_from_ code */
9 int irq = regs->orig_eax & 0xff;
10#ifdef CONFIG_4KSTACKS
11 union irq_ctx *curctx, *irqctx;
12 u32 *isp;
13#endif
14
15 irq_enter();
16
17#ifdef CONFIG_4KSTACKS
18
19 curctx = (union irq_ctx *) current_thread_info();
20 irqctx = hardirq_ctx[smp_processor_id()];
21
22 /*
23 * this is where we switch to the IRQ stack. However, if we are
24 * already using the IRQ stack (because we interrupted a hardirq
25 * handler) we can't do that and just have to keep using the
26 * current stack (which is the irq stack already after all)
27 */
28 if (curctx != irqctx) {
29 int arg1, arg2, ebx;
30
31 /* build the stack frame on the IRQ stack */
32 isp = (u32*) ((char*)irqctx + sizeof(*irqctx));
33 irqctx->tinfo.task = curctx->tinfo.task;
34 irqctx->tinfo.previous_esp = current_stack_pointer;
35
36 asm volatile(
37 " xchgl %%ebx,%%esp \n"
38 " call __do_IRQ \n"
39 " movl %%ebx,%%esp \n"
40 : "=a" (arg1), "=d" (arg2), "=b" (ebx)
41 : "0" (irq), "1" (regs), "2" (isp)
42 : "memory", "cc", "ecx"
43 );
44 } else
45#endif
46 __do_IRQ(irq, regs);
47
48 irq_exit();
49
50 return 1;
51}对于do_IRQ函数:
-
irq_enter宏将递增嵌套数量的计数器, 关于该计数器字段preempt_count可以参考 软中断.c1#define irq_enter() \ 2do { \ 3 account_system_vtime(current); \ 4 add_preempt_count(HARDIRQ_OFFSET); \ 5} while (0) -
如果
thread_union联合体只占据一个页框, 那么将执行一些特殊的操作:-
执行
current_thread_info函数以获取与内核栈相关联的thread_info描述符地址.c1/* how to get the thread information struct from C */ 2static inline struct thread_info *current_thread_info(void) 3{ 4 struct thread_info *ti; 5 __asm__("andl %%esp,%0; ":"=r" (ti) : "0" (~(THREAD_SIZE - 1))); 6 return ti; 7}该函数在第三章中有说明, 这里给出源码, 其本质是一样的.
-
L28将比较当前与内核栈相关联的进程描述符地址和存放在
hardirq_ctx中的与本地CPU相关联的进程描述符地址. 如果地址相等, 说明内核已经在使用硬中断请求栈, 这种情况发生在内核处理中断时又产生了中断请求时; 如果不等, 则要切换到硬中断请求栈:-
将当前进程描述符指针和
esp寄存器存放在本地CPU的irq_ctx联合体中. -
将旧
esp寄存器的内容存入ebx后, 将esp更新为irqctx+4096. 由于esp是向下增长的, 因而通过这种方式来使用该硬中断请求栈.
-
-
-
无论联合体占据几个页框, 本质上都之后将调用
__do_IRQ函数(单页框的在调用完后成将从ebx中恢复原来的esp). 该函数通过栈快速传入两个参数irq号和指向pt_regs结构的指针.- 需要说明一下irq号的获取(L9). 参数
regs所对应的结构实质上从栈中取得, 那么回到调用do_IRQ的汇编函数, 我们可以看到SAVEALL保存了从es到ebx的所有寄存器, 而在SAVEALL之上又保存过了$vector-256. 结合pt_regs的字段可以发现, 最先前压入的$vector-256所在的位置正是orig_eax字段, 这也解释了L9会对该字段进行操作.
c1struct pt_regs { 2 long ebx; 3 long ecx; 4 long edx; 5 long esi; 6 long edi; 7 long ebp; 8 long eax; 9 int xds; 10 int xes; 11 long orig_eax; 12 long eip; 13 int xcs; 14 long eflags; 15 long esp; 16 int xss; 17}; - 需要说明一下irq号的获取(L9). 参数
只考虑80x86硬件体系下的代码, 因而删去一些无用代码. __do_IRQ源码如下:
1/*
2 * do_IRQ handles all normal device IRQ's (the special
3 * SMP cross-CPU interrupts have their own specific
4 * handlers).
5 */
6fastcall unsigned int __do_IRQ(unsigned int irq, struct pt_regs *regs)
7{
8 irq_desc_t *desc = irq_desc + irq;
9 struct irqaction * action;
10 unsigned int status;
11
12 kstat_this_cpu.irqs[irq]++;
13
14 spin_lock(&desc->lock);
15 desc->handler->ack(irq);
16 /*
17 * REPLAY is when Linux resends an IRQ that was dropped earlier
18 * WAITING is used by probe to mark irqs that are being tested
19 */
20 status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
21 status |= IRQ_PENDING; /* we _want_ to handle it */
22
23 /*
24 * If the IRQ is disabled for whatever reason, we cannot
25 * use the action we have.
26 */
27 action = NULL;
28 if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
29 action = desc->action;
30 status &= ~IRQ_PENDING; /* we commit to handling */
31 status |= IRQ_INPROGRESS; /* we are handling it */
32 }
33 desc->status = status;
34
35 /*
36 * If there is no IRQ handler or it was disabled, exit early.
37 * Since we set PENDING, if another processor is handling
38 * a different instance of this same irq, the other processor
39 * will take care of it.
40 */
41 if (unlikely(!action))
42 goto out;
43
44 /*
45 * Edge triggered interrupts need to remember
46 * pending events.
47 * This applies to any hw interrupts that allow a second
48 * instance of the same irq to arrive while we are in do_IRQ
49 * or in the handler. But the code here only handles the _second_
50 * instance of the irq, not the third or fourth. So it is mostly
51 * useful for irq hardware that does not mask cleanly in an
52 * SMP environment.
53 */
54 for (;;) {
55 irqreturn_t action_ret;
56
57 spin_unlock(&desc->lock);
58
59 action_ret = handle_IRQ_event(irq, regs, action);
60
61 spin_lock(&desc->lock);
62 if (!noirqdebug)
63 note_interrupt(irq, desc, action_ret);
64 if (likely(!(desc->status & IRQ_PENDING)))
65 break;
66 desc->status &= ~IRQ_PENDING;
67 }
68 desc->status &= ~IRQ_INPROGRESS;'
69
70out:
71 /*
72 * The ->end() handler has to deal with interrupts which got
73 * disabled while the handler was running.
74 */
75 desc->handler->end(irq);
76 spin_unlock(&desc->lock);
77
78 return 1;
79}对于__do_IRQ函数:
-
访问主IRQ之前需要获得自旋锁, 以保护不同CPU的并发访问(参考第五章).
-
调用主描述符的
ack方法. 如果使用8259A PIC, ack函数将会应答该中断, 并禁用此IRQ线, 这是为了保证CPU在处理结束前不再接受这种类型的中断. 事实上, 该函数是以禁止本地中断的情况下进行的, 且CPU控制单元也会由于这是一个IDT中断门调用而自动清空eflags寄存器的IF标志; 而对于APIC而言事情可能会更加复杂, 应答中断依赖于中断类型, 可能由ack实现也可能由end实现. 不过在任何一种情况下, 都应当认为在中断处理程序结束前, 本地APIC不再接受这种中断. -
随后清
REPLAY,WAITING标志, 设置PENDING标志. -
如果IRQ未被设置
DISABLED和INPROGESS, 那么就将处理该中断:-
清
PENDING标志, 置INPROGESS标志 -
释放irq描述符的自旋锁后, 执行
handle_IRQ_event函数执行中断服务例程ISR:c1/* 2* Have got an event to handle: 3*/ 4fastcall int handle_IRQ_event(unsigned int irq, struct pt_regs *regs, 5 struct irqaction *action) 6{ 7 int ret, retval = 0, status = 0; 8 9 if (!(action->flags & SA_INTERRUPT)) 10 local_irq_enable(); 11 12 do { 13 ret = action->handler(irq, action->dev_id, regs); 14 if (ret == IRQ_HANDLED) 15 status |= action->flags; 16 retval |= ret; 17 action = action->next; 18 } while (action); 19 20 if (status & SA_SAMPLE_RANDOM) 21 add_interrupt_randomness(irq); 22 local_irq_disable(); 23 24 return retval; 25}-
如果
SA_INTERRUPT标志(处理程序必须关中断)清零, 则调用sti汇编指令打开中断 -
通过一个循环执行该action下所有的
hanlder处理例程, 每个处理例程返回0(失败)或1(成功), 所有例程的执行结果用或运算存储起来; 对于所有的例程均接受3个参数: 第一个参数使得单个ISP可以处理多个IRQ线; 第二个设备标识符使得单个ISP可以处理多个同类设备; 第三个参数则允许ISP访问到被中断的内核控制路径的执行上下文. -
如过设置了随机采样标志, 则执行相关函数(不予深究)
-
禁用本地中断后返回执行结果.
-
-
当处理例程返回后, 重新获得描述符的自旋锁.
-
再次检查
PENDING标志.- 如果标志仍然为0(L30中清零过), 说明没有进一步的中断到来
- 而当其被设置时, 则说明在上一步执行
handle_IRQ_event时, 由于自旋锁被释放, 另一个CPU正在为一个新出现的此类中断执行do_IRQ函数. 而由于此时该irq描述符的INPROGESS标志被设置, 则另一个CPU会简单地放弃处理(L28), 将处理工作交给当前CPU完成. 所以当前CPU执行的__do_irq将再循环一次, 清PENDING标志, 重新进入循环, 为这个新到来的中断进行处理. 这样做的好处有: (1) ISR不必是可重入的, 它们的执行是串行的, 从而导致了较简单的内核结构; (2) 放弃执行ISR的CPU很快又回到了它原本正在做的事情上, 不弄脏其原本的硬件Cache, 这对系统性能是有利的. 只要一个CPU正在执行中断的ISR,IRQ_INPROGRESS标志就被设置, 因此, 这也解释了__do_irq实际执行ISR之前都要对该标志进行判断的原因.
-
循环退出后, 清零
INPROGESS标志.
-
-
调用主IRQ描述符的
end方法, 最终释放自旋锁, 函数结束!
执行完__do_IRQ函数后, 重新回到do_IRQ执行最后一步irq_exit:
1/*
2 * Exit an interrupt context. Process softirqs if needed and possible:
3 */
4void irq_exit(void)
5{
6 account_system_vtime(current);
7 sub_preempt_count(IRQ_EXIT_OFFSET);
8 if (!in_interrupt() && local_softirq_pending())
9 invoke_softirq();
10 preempt_enable_no_resched();
11}该宏递减preempt_count计数器, 并检查是否有挂起的软中断(参考后续的
处理软中断)需要执行.
该函数结束后, 控制将转向ret_from_intr()函数. 参考
从中断和异常返回.
挽救丢失的中断
在单处理器上, 通过IRQ_PENDING, IRQ_INPROGRESS和IRQ_DISABLED标志能够保证中断被正确处理, 即使是硬件失常也不例外.
但在多处理器下, 可能会产生问题:
- IRQ线上出现一个中断, APIC系统选择了CPU a进行处理, 但CPU a在应答前, 这条IRQ线被CPU b屏蔽掉了, 即
IRQ_DISABLED被设置, 因而CPU a不会执行ISR…
为了解决这种局面, 内核用来激活IRQ线的函数enable_irq先检查是否发生了中断丢失:
1#if defined(CONFIG_X86_IO_APIC)
2static inline void hw_resend_irq(struct hw_interrupt_type *h, unsigned int i)
3{
4 if (IO_APIC_IRQ(i))
5 send_IPI_self(IO_APIC_VECTOR(i));
6}
7#else
8static inline void hw_resend_irq(struct hw_interrupt_type *h, unsigned int i) {}
9#endif
10
11/**
12 * enable_irq - enable handling of an irq
13 * @irq: Interrupt to enable
14 *
15 * Undoes the effect of one call to disable_irq(). If this
16 * matches the last disable, processing of interrupts on this
17 * IRQ line is re-enabled.
18 *
19 * This function may be called from IRQ context.
20 */
21void enable_irq(unsigned int irq)
22{
23 irq_desc_t *desc = irq_desc + irq;
24 unsigned long flags;
25
26 spin_lock_irqsave(&desc->lock, flags);
27 switch (desc->depth) {
28 case 0:
29 WARN_ON(1);
30 break;
31 case 1: {
32 unsigned int status = desc->status & ~IRQ_DISABLED;
33
34 desc->status = status;
35 if ((status & (IRQ_PENDING | IRQ_REPLAY)) == IRQ_PENDING) {
36 desc->status = status | IRQ_REPLAY;
37 hw_resend_irq(desc->handler,irq);
38 }
39 desc->handler->enable(irq);
40 /* fall-through */
41 }
42 default:
43 desc->depth--;
44 }
45 spin_unlock_irqrestore(&desc->lock, flags);
46}-
与挽救丢失中断的标志是 IRQ_REPLAY….之前一直看成了REPLY… 这个标志用于说明当IRQ线被屏蔽时, 前一个IRQ还没有对PIC做出应答的情况. 涉及到该标志的设置和清零只出现在两个地方:
__do_irq清零该标志,enable_irq设置该标志. -
IRQ_PENGDING标志在离开中断处理程序后总会被设置为0; 因而, 函数中判断depth为1且IRQ_PENDING被设置时, 就认为出现了上述提到的中断丢失的情况. 在这种情况下, 通过调用hw_resend_irq产生一个新中断.这可以通过强制本地APIC产生一个自我中断达成, 参考后续的 处理器间中断. -
L35判断
IRQ_REPLAY是为了确保只产生一个自我中断, 这个标志会在__do_irq函数开始阶段被清除.
IRQ线的动态分配
在 中断向量中看到, 除了几个特定固定的向量, 其余的向量都被动态分配处理.
因而有一种方式让本不支持IRQ共享的设备能够使用同一条IRQ线, 技巧就在于使这些硬件的活动串行化.
在激活一个准备使用IRQ线的设备前, 其驱动程序需要调用request_irq:
1/**
2 * request_irq - allocate an interrupt line
3 * @irq: Interrupt line to allocate
4 * @handler: Function to be called when the IRQ occurs
5 * @irqflags: Interrupt type flags
6 * @devname: An ascii name for the claiming device
7 * @dev_id: A cookie passed back to the handler function
8 *
9 * This call allocates interrupt resources and enables the
10 * interrupt line and IRQ handling. From the point this
11 * call is made your handler function may be invoked. Since
12 * your handler function must clear any interrupt the board
13 * raises, you must take care both to initialise your hardware
14 * and to set up the interrupt handler in the right order.
15 *
16 * Dev_id must be globally unique. Normally the address of the
17 * device data structure is used as the cookie. Since the handler
18 * receives this value it makes sense to use it.
19 *
20 * If your interrupt is shared you must pass a non NULL dev_id
21 * as this is required when freeing the interrupt.
22 *
23 * Flags:
24 *
25 * SA_SHIRQ Interrupt is shared
26 * SA_INTERRUPT Disable local interrupts while processing
27 * SA_SAMPLE_RANDOM The interrupt can be used for entropy
28 *
29 */
30int request_irq(unsigned int irq,
31 irqreturn_t (*handler)(int, void *, struct pt_regs *),
32 unsigned long irqflags, const char * devname, void *dev_id)
33{
34 struct irqaction * action;
35 int retval;
36
37 /*
38 * Sanity-check: shared interrupts must pass in a real dev-ID,
39 * otherwise we'll have trouble later trying to figure out
40 * which interrupt is which (messes up the interrupt freeing
41 * logic etc).
42 */
43 if ((irqflags & SA_SHIRQ) && !dev_id)
44 return -EINVAL;
45 if (irq >= NR_IRQS)
46 return -EINVAL;
47 if (!handler)
48 return -EINVAL;
49
50 action = kmalloc(sizeof(struct irqaction), GFP_ATOMIC);
51 if (!action)
52 return -ENOMEM;
53
54 action->handler = handler;
55 action->flags = irqflags;
56 cpus_clear(action->mask);
57 action->name = devname;
58 action->next = NULL;
59 action->dev_id = dev_id;
60
61 retval = setup_irq(irq, action);
62 if (retval)
63 kfree(action);
64
65 return retval;
66}
67
68
69/*
70 * Internal function to register an irqaction - typically used to
71 * allocate special interrupts that are part of the architecture.
72 */
73int setup_irq(unsigned int irq, struct irqaction * new)
74{
75 struct irq_desc *desc = irq_desc + irq;
76 struct irqaction *old, **p;
77 unsigned long flags;
78 int shared = 0;
79
80 if (desc->handler == &no_irq_type)
81 return -ENOSYS;
82 /*
83 * Some drivers like serial.c use request_irq() heavily,
84 * so we have to be careful not to interfere with a
85 * running system.
86 */
87 if (new->flags & SA_SAMPLE_RANDOM) {
88 /*
89 * This function might sleep, we want to call it first,
90 * outside of the atomic block.
91 * Yes, this might clear the entropy pool if the wrong
92 * driver is attempted to be loaded, without actually
93 * installing a new handler, but is this really a problem,
94 * only the sysadmin is able to do this.
95 */
96 rand_initialize_irq(irq);
97 }
98
99 /*
100 * The following block of code has to be executed atomically
101 */
102 spin_lock_irqsave(&desc->lock,flags);
103 p = &desc->action;
104 if ((old = *p) != NULL) {
105 /* Can't share interrupts unless both agree to */
106 if (!(old->flags & new->flags & SA_SHIRQ)) {
107 spin_unlock_irqrestore(&desc->lock,flags);
108 return -EBUSY;
109 }
110
111 /* add new interrupt at end of irq queue */
112 do {
113 p = &old->next;
114 old = *p;
115 } while (old);
116 shared = 1;
117 }
118
119 *p = new;
120
121 if (!shared) {
122 desc->depth = 0;
123 desc->status &= ~(IRQ_DISABLED | IRQ_AUTODETECT |
124 IRQ_WAITING | IRQ_INPROGRESS);
125 if (desc->handler->startup)
126 desc->handler->startup(irq);
127 else
128 desc->handler->enable(irq);
129 }
130 spin_unlock_irqrestore(&desc->lock,flags);
131
132 new->irq = irq;
133 register_irq_proc(irq);
134 new->dir = NULL;
135 register_handler_proc(irq, new);
136
137 return 0;
138}代码比较长, 但是大部分很好理解:
-
在
request_irq中, 分配空间给一个新的irqaction描述符, 使用相应的参数进行初始化后, 调用setup_irq尝试将其插入到合适的链表中. -
在
setup_irq中:-
L106-108判断了IRQ上的原有设备和即将插入的新设备是否都设置了IRQ共享标志, 如果满足, 再通过一个循环L112-115将指针移动到链表尾, 以备后续插入L119.
-
如果没有和其他设备共享IRQ线L121, 则清除一些标志并更新一些变量L122-123, 随后调用
startup(如果有)或enable函数来确保IRQ信号被激活. -
L133,135好像对CPU亲和力进行了修改, 同时在
/proc/irq/中更新了相关的文件, 不予深究
-
当设备操作结束后, 驱动调用free_irq从链表中删除该描绘符, 并释放对应的内存:
1/**
2 * free_irq - free an interrupt
3 * @irq: Interrupt line to free
4 * @dev_id: Device identity to free
5 *
6 * Remove an interrupt handler. The handler is removed and if the
7 * interrupt line is no longer in use by any driver it is disabled.
8 * On a shared IRQ the caller must ensure the interrupt is disabled
9 * on the card it drives before calling this function. The function
10 * does not return until any executing interrupts for this IRQ
11 * have completed.
12 *
13 * This function must not be called from interrupt context.
14 */
15void free_irq(unsigned int irq, void *dev_id)
16{
17 struct irq_desc *desc;
18 struct irqaction **p;
19 unsigned long flags;
20
21 if (irq >= NR_IRQS)
22 return;
23
24 desc = irq_desc + irq;
25 spin_lock_irqsave(&desc->lock,flags);
26 p = &desc->action;
27 for (;;) {
28 struct irqaction * action = *p;
29
30 if (action) {
31 struct irqaction **pp = p;
32
33 p = &action->next;
34 if (action->dev_id != dev_id)
35 continue;
36
37 /* Found it - now remove it from the list of entries */
38 *pp = action->next;
39 if (!desc->action) {
40 desc->status |= IRQ_DISABLED;
41 if (desc->handler->shutdown)
42 desc->handler->shutdown(irq);
43 else
44 desc->handler->disable(irq);
45 }
46 spin_unlock_irqrestore(&desc->lock,flags);
47 unregister_handler_proc(irq, action);
48
49 /* Make sure it's not being used on another CPU */
50 synchronize_irq(irq);
51 kfree(action);
52 return;
53 }
54 printk(KERN_ERR "Trying to free free IRQ%d\n",irq);
55 spin_unlock_irqrestore(&desc->lock,flags);
56 return;
57 }
58}双指针的操作很炫..但是并不想深究每一行代码, 大体能看懂..因而就此略过
处理器间中断
处理器间中断(IPI)允许一个CPU向系统中其余CPU发送信号, 不过并不通过IRQ线传输, 而是直接作为信号直接放在连接所有本地APIC的总线上传输.
在SMP中, Linux定义了三种处理器间中断:
- CALL_FUNCTION_VECTOR (vector 0xfb):
Sent to all CPUs but the sender, forcing those CPUs to run a function passed by the sender. The corresponding interrupt handler is named
call_function_ interrupt(). The function (whose address is passed in the call_data global variable) may, for instance, force all other CPUs to stop, or may force them to set the contents of the Memory Type Range Registers (MTRRs).* Usually this interrupt is sent to all CPUs except the CPU executing the calling function by means of the smp_call_function() facility function. - RESCHEDULE_VECTOR (vector 0xfc):
When a CPU receives this type of interrupt, the corresponding handler—named
reschedule_interrupt()—limits itself to acknowledging the interrupt. Resched- uling is done automatically when returning from the interrupt (see the section “Returning from Interrupts and Exceptions” later in this chapter). - INVALIDATE_TLB_VECTOR (vector 0xfd):
Sent to all CPUs but the sender, forcing them to invalidate their Translation Lookaside Buffers. The corresponding handler, named
invalidate_interrupt(), flushes some TLB entries of the processor as described in the section “Handling the Hardware Cache and the TLB” in Chapter 2.
IPI处理程序的代码由BUILD_INTERRUPT 产生. 其调用高级C语言函数smp_call_function_interrupt, 该函数应当本地APIC上的IPI, 执行低级C语言函数call_function_interrupt.
1#define BUILD_INTERRUPT(name, nr) \
2ENTRY(name) \
3 pushl $nr-256; \
4 SAVE_ALL \
5 movl %esp,%eax; \
6 call smp_/**/name; \
7 jmp ret_from_intr;通过一组函数可以很容易实现IPI:
1send_IPI_all()
2send_IPI_all_allbutself()
3send_IPI_self()
4send_IPI_mask() //发送一个IPI到位掩码指定的一组CPU
非紧迫任务的执行
在 中断处理中我们提到, 一些不紧急的内核任务可以延迟执行. 由于一个中断处理程序的几个处理例程是串行进行的, 且在一个处理程序完成之前不应该再出现这个中断; 而可延迟中断可以在开中断的时候完成, 将其从中断处理程序中抽离开有助于内核保持较短的响应时间.
Linux2.6使用两种非紧迫、可中断的内核函数来处理:
-
可延迟函数: 软中断和tasklet
(事实上在Intel手册中, 编程异常也被称为软中断, 参考 中断和异常; 由于会产生混淆, 所以称其为可延迟函数…怪怪的) -
通过工作队列来执行的函数
软中断及tasklet
软中断和tasklet有密切的关系, 后者是在前者的基础上实现的. 不过, 出现在内核代码中的术语 软中断(softirq) 常常表示可延迟函数的所有种类. 另一个常用的术语 中断上下文 则表示内核当前正在执行一个中断处理程序或可延迟函数.
-
软中断的分配是编译时静态定义的, 而tasklet的分配和初始化可以在运行时进行(如安装内核模块时).
-
软中断可以并发地执行, 即便是同种类型的软中断, 因此软中断必须是**可重入自旋锁保护其数据结构; 而tasklet不必担心这些问题, 因为内核对其的执行采用了更加严格控制. 相同类型的tasklet总是被串行的执行, 因而在多CPU上只能并发执行不同类型的tasklet.
在可延迟函数上可以执行四种操作:
-
Initialization Defines a new deferrable function; this operation is usually done when the kernel initializes itself or a module is loaded.
-
Activation Marks a deferrable function as “pending”—to be run the next time the kernel schedules a round of executions of deferrable functions. Activation can be done at any time (even while handling interrupts).
-
Masking(屏蔽) Selectively disables a deferrable function so that it will not be executed by the kernel even if activated. We’ll see in the section “Disabling and Enabling Deferrable Functions” in Chapter 5 that disabling deferrable functions is sometimes essential.
-
Execution Executes a pending deferrable function together with all other pending deferra- ble functions of the same type; execution is performed at well-specified times, explained later in the section “Softirqs.”
软中断
Linux2.6使用有限个软中断, 大多数情况下tasklet是足够使用的, 且容易编写, 因为它不必可重入.
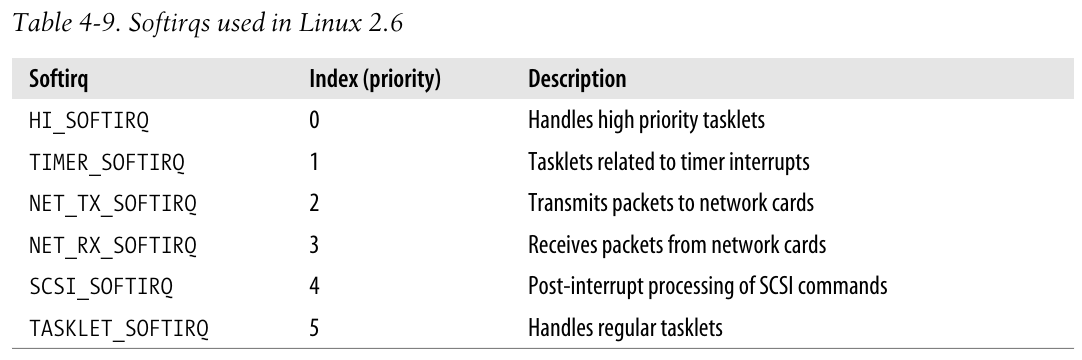
软中断的下标决定了它的优先级, 低下标意味着高优先级, 因为软中断从0开始执行.
通过grep, 可以看到6个软中断的初始化函数(参考 处理软中断):
1net/core/dev.c:3294: open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
2net/core/dev.c:3295: open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
3drivers/scsi/scsi.c:1277: open_softirq(SCSI_SOFTIRQ, scsi_softirq, NULL);
4kernel/timer.c:1394: open_softirq(TIMER_SOFTIRQ, run_timer_softirq, NULL);
5kernel/softirq.c:346: open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
6kernel/softirq.c:347: open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);- 其中关于tasklet的两个软中断处理函数将会在 处理tasklet中具体说明.
软中断数据结构
表示软中断的数据结构是softirq_vec数组, 拥有32个元素, 但仅有前6个被有效地使用, 其元素类型为softirq_action: action指向软中断函数, data指向该函数所需要的通用数据结构.
1struct softirq_action
2{
3 void (*action)(struct softirq_action *);
4 void *data;
5};
6
7static struct softirq_action softirq_vec[32] __cacheline_aligned_in_smp;另一个需要说明的是preempt_count字段, 其用于追踪内核抢占和内核控制路径的嵌套, 该字段存放在进程描述符的thread_info中.
该字段中比特位表示的含义如下:

第一个计数器显式记录本地CPU内核抢占的次数, 第二个计数器表示可延迟函数被禁用的程度, 第三个计数器表示在本地CPU上中断处理程序的嵌套数(参考前文
中断处理程序中的do_IRQ函数)
内核为了快速确定是否能够抢占当前进程, 只需要检查preempt_count字段中的相应值是否为0即可. 第五章会深入讨论内核抢占.
一些与该字段关联的函数如下:
1#define hardirq_count() (preempt_count() & HARDIRQ_MASK)
2#define softirq_count() (preempt_count() & SOFTIRQ_MASK)
3#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK))
4
5/*
6 * Are we doing bottom half or hardware interrupt processing?
7 * Are we in a softirq context? Interrupt context?
8 */
9#define in_irq() (hardirq_count())
10#define in_softirq() (softirq_count())
11#define in_interrupt() (irq_count())宏in_interrupt检查中断计数器, 只要软中断计数器或硬中断计数器中有一个非零就产生一个正值. 当内核不使用多内核栈时, 检查当前进程的preempt_count即可; 不然, 则可能还需要检查本地CPU的irq_ctx联合体中thread_info->preempt_count的内容, 不过在这种情况下, 该值总为正数值, 因而宏返回非零结果.
实现软中断的最后一个关键数据结构是每个CPU都有的32位掩码(参考
irq数据结构), 即irq_cpustat_t结构中的__softirq_pending字段. 可以通过local_softirq_pending宏来快速选中该字段内容:
1#ifndef __ARCH_IRQ_STAT
2extern irq_cpustat_t irq_stat[]; /* defined in asm/hardirq.h */
3#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member)
4#endif
5
6 /* arch independent irq_stat fields */
7#define local_softirq_pending() \
8 __IRQ_STAT(smp_processor_id(), __softirq_pending)检查软中断
内核需要周期性但不能过于频繁地检查活动的软中断, 这类检查在以下的几个点上进行:
- When the kernel invokes the local_bh_enable() function* to enable softirqs on the local CPU
- When the do_IRQ() function finishes handling an I/O interrupt and invokes the irq_exit() macro
- If the system uses an I/O APIC, when the smp_apic_timer_interrupt() function finishes handling a local timer interrupt (see the section “Timekeeping Architecture in Multiprocessor Systems” in Chapter 6)
- In multiprocessor systems, when a CPU finishes handling a function triggered by a CALL_FUNCTION_VECTOR interprocessor interrupt
- When one of the special ksoftirqd/n kernel threads is awakened (see later)
处理软中断
初始化软中断 open_softirq:
1void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
2{
3 softirq_vec[nr].data = data;
4 softirq_vec[nr].action = action;
5}通过参数nr来决定初始化softirq_vec数组中合适的元素.
激活软中断 raise_softirq:
1#define __raise_softirq_irqoff(nr) do { local_softirq_pending() |= 1UL << (nr); } while (0)
2
3/*
4 * we cannot loop indefinitely here to avoid userspace starvation,
5 * but we also don't want to introduce a worst case 1/HZ latency
6 * to the pending events, so lets the scheduler to balance
7 * the softirq load for us.
8 */
9static inline void wakeup_softirqd(void)
10{
11 /* Interrupts are disabled: no need to stop preemption */
12 struct task_struct *tsk = __get_cpu_var(ksoftirqd);
13
14 if (tsk && tsk->state != TASK_RUNNING)
15 wake_up_process(tsk);
16}
17
18
19/*
20 * This function must run with irqs disabled!
21 */
22inline fastcall void raise_softirq_irqoff(unsigned int nr)
23{
24 __raise_softirq_irqoff(nr);
25
26 /*
27 * If we're in an interrupt or softirq, we're done
28 * (this also catches softirq-disabled code). We will
29 * actually run the softirq once we return from
30 * the irq or softirq.
31 *
32 * Otherwise we wake up ksoftirqd to make sure we
33 * schedule the softirq soon.
34 */
35 if (!in_interrupt())
36 wakeup_softirqd();
37}
38
39EXPORT_SYMBOL(raise_softirq_irqoff);
40
41void fastcall raise_softirq(unsigned int nr)
42{
43 unsigned long flags;
44
45 local_irq_save(flags);
46 raise_softirq_irqoff(nr);
47 local_irq_restore(flags);
48}-
在关中断的情况下执行
raise_softirq_irqoff函数 -
将软中断标记为挂起状态, 这是通过设置
local_softirq_pending中与当前下标nr相关的掩码来实现的(L24->L1)- 注意: 在这一点中, 我们结合
irq_exit(参考 中断处理程序中相关源码)对挂起的软中断的周期检查(参考 检查软中断)为例. 源码中可以看到, 通过直接调用local_softirq_pending宏来获取相应CPU中的软中断掩码字段, 一旦该值不为零, 则意味着有一个软中断正在等待, 应当执行软中断处理程序. 这就解释了为什么上面为何说通过设置掩码即可将软中断标记为挂起.
c1void irq_exit(void) 2{ 3 ... 4 if (!in_interrupt() && local_softirq_pending()) 5 invoke_softirq(); 6 ... 7} - 注意: 在这一点中, 我们结合
-
如果
in_interrupt宏非零, 说明要么此时已经在中断上下文中调用了raise_softirq, 要么当前禁用了软中断. 不然, 则调用wakeup_softirqd唤醒本地CPU的ksoftirqd进程(参考后续的 ksoftirqd内核线程).
调用do_softirq来处理软中断:
1asmlinkage void do_softirq(void)
2{
3 unsigned long flags;
4 struct thread_info *curctx;
5 union irq_ctx *irqctx;
6 u32 *isp;
7
8 if (in_interrupt())
9 return;
10
11 local_irq_save(flags);
12
13 if (local_softirq_pending()) {
14 curctx = current_thread_info();
15 irqctx = softirq_ctx[smp_processor_id()];
16 irqctx->tinfo.task = curctx->task;
17 irqctx->tinfo.previous_esp = current_stack_pointer;
18
19 /* build the stack frame on the softirq stack */
20 isp = (u32*) ((char*)irqctx + sizeof(*irqctx));
21
22 asm volatile(
23 " xchgl %%ebx,%%esp \n"
24 " call __do_softirq \n"
25 " movl %%ebx,%%esp \n"
26 : "=b"(isp)
27 : "0"(isp)
28 : "memory", "cc", "edx", "ecx", "eax"
29 );
30 }
31
32 local_irq_restore(flags);
33}-
首先检查
in_interrupt是否为1, 这种情况说明要么在中断上下文中调用了该函数, 要么当前禁用软中断, 应当直接返回. -
如果
thread_union结构大小为4KB, 则应当使用单独的软中断栈, 理应如此.( 不过在此处代码中, 并不对此进行判断, 而总是选择使用软中断请求栈, 为何?) 从代码中可以看到, 将irqctx的进程字段更新为当前进程(L16), 将旧的栈地址存放到对应字段中(L17), 再结合汇编指令, 将esp寄存器的值设置为该联合体的栈地址, 调用__do_softirq后重新恢复原先的esp寄存器内容. 此处逻辑与硬中断处理类似, 参考 中断处理程序.
下面看到真正的处理核心__do_softirq函数:
1/*
2 * We restart softirq processing MAX_SOFTIRQ_RESTART times,
3 * and we fall back to softirqd after that.
4 *
5 * This number has been established via experimentation.
6 * The two things to balance is latency against fairness -
7 * we want to handle softirqs as soon as possible, but they
8 * should not be able to lock up the box.
9 */
10#define MAX_SOFTIRQ_RESTART 10
11
12asmlinkage void __do_softirq(void)
13{
14 struct softirq_action *h;
15 __u32 pending;
16 int max_restart = MAX_SOFTIRQ_RESTART;
17 int cpu;
18
19 pending = local_softirq_pending();
20
21 local_bh_disable();
22 cpu = smp_processor_id();
23restart:
24 /* Reset the pending bitmask before enabling irqs */
25 local_softirq_pending() = 0;
26
27 local_irq_enable();
28
29 h = softirq_vec;
30
31 do {
32 if (pending & 1) {
33 h->action(h);
34 rcu_bh_qsctr_inc(cpu);
35 }
36 h++;
37 pending >>= 1;
38 } while (pending);
39
40 local_irq_disable();
41
42 pending = local_softirq_pending();
43 if (pending && --max_restart)
44 goto restart;
45
46 if (pending)
47 wakeup_softirqd();
48
49 __local_bh_enable();
50}-
由于在执行一个软中断函数时可能出现新挂起的软中断, 因此为了保证可延迟函数的低延迟性,
__do_softirq会一直执行完所有挂起的软中断函数. 但是这会使得该函数执行时间过长, 延迟用户态进程的执行, 因此本函数最多只做固定次数的循环, 即MAX_SOFTIRQ_RESTART次. -
下面看到
local_bh_disable和__local_bh_enable这一对用于激活和禁止可延迟函数的函数:c1/* <hardirq.h> */ 2/* 3* We put the hardirq and softirq counter into the preemption 4* counter. The bitmask has the following meaning: 5* 6* - bits 0-7 are the preemption count (max preemption depth: 256) 7* - bits 8-15 are the softirq count (max # of softirqs: 256) 8* 9* The hardirq count can be overridden per architecture, the default is: 10* 11* - bits 16-27 are the hardirq count (max # of hardirqs: 4096) 12* - ( bit 28 is the PREEMPT_ACTIVE flag. ) 13* 14* PREEMPT_MASK: 0x000000ff 15* SOFTIRQ_MASK: 0x0000ff00 16* HARDIRQ_MASK: 0x0fff0000 17*/ 18#define PREEMPT_BITS 8 19#define SOFTIRQ_BITS 8 20 21#ifndef HARDIRQ_BITS 22#define HARDIRQ_BITS 12 23 24#define PREEMPT_SHIFT 0 25#define SOFTIRQ_SHIFT (PREEMPT_SHIFT + PREEMPT_BITS) 26#define HARDIRQ_SHIFT (SOFTIRQ_SHIFT + SOFTIRQ_BITS) 27 28#define PREEMPT_OFFSET (1UL << PREEMPT_SHIFT) 29#define SOFTIRQ_OFFSET (1UL << SOFTIRQ_SHIFT) 30#define HARDIRQ_OFFSET (1UL << HARDIRQ_SHIFT) 31 32 33/* <preempt.h> */ 34# define add_preempt_count(val) do { preempt_count() += (val); } while (0) 35# define sub_preempt_count(val) do { preempt_count() -= (val); } while (0) 36 37#define inc_preempt_count() add_preempt_count(1) 38#define dec_preempt_count() sub_preempt_count(1) 39 40/* <interrupt.h> */ 41/* SoftIRQ primitives. */ 42#define local_bh_disable() \ 43 do { add_preempt_count(SOFTIRQ_OFFSET); barrier(); } while (0) 44#define __local_bh_enable() \ 45 do { barrier(); sub_preempt_count(SOFTIRQ_OFFSET); } while (0) 46 47extern void local_bh_enable(void); 48 49 50/* <softirq.c> */ 51void local_bh_enable(void) 52{ 53 WARN_ON(irqs_disabled()); 54 /* 55 * Keep preemption disabled until we are done with 56 * softirq processing: 57 */ 58 sub_preempt_count(SOFTIRQ_OFFSET - 1); 59 60 if (unlikely(!in_interrupt() && local_softirq_pending())) 61 do_softirq(); 62 63 dec_preempt_count(); 64 preempt_check_resched(); 65}-
事实上, 这一对函数执行的就是在
preempt_count内部的相关计数器上进行加一或减一, 以控制软中断的激活或禁用, 结合代码很清晰就可以看到. -
单独说明一下
local_bh_enable函数. 其直接通过sub_preempt_count(SOFTIRQ_OFFSET - 1);语句来操作计数器, 这样看可能有些疑惑为什么要减一, 其实它做的工作是两步:- SOFTIRQ_OFFSET为软中断计数器加一;+ 1来为抢占计数器加一. 为抢占计数器加1来禁止内核被抢占, 这可能是因为后续可能要执行软中断的检查与执行(参考 检查软中断的检查点). 检查完成后, 调用dec_preempt_count再将抢占计数器减一, 重新激活内核抢占. -
此外, bh其实表示的是后半部分(bottom half,bh), 相对应的是前半部分(top half,th), 其实这就是硬中断和软中断.
-
-
重新回到
__do_softirq函数, 在禁用了软中断后, 开始每一轮的循环:-
清空CPU对应的软中断位图后, 打开硬中断以便可以接受新的irq中断请求.
-
按位检查位图标志, 找出对应的软中断处理函数并执行(L29-38); L34似乎是一些内核同步机制, 好像类似于之前xv6做的COW机制, 具体不予深究.
-
禁用硬中断, 检查是否出现了新的挂起的软中断, 如果循环次数仍然足够, 则跳转到
restart代码段重新进行软中断处理; 如果次数不够, 则调用wakeup_softirqd唤醒内核线程来处理本地CPU的软中断(参考下一节 ksoftirqd内核线程).
-
-
函数结束, 重新打开软中断.
- 注意, 可延迟函数的执行应该是串行的, 因而在该函数中, 对于软中断的禁用和激活是十分重要的.
ksoftirqd内核线程
每个CPU都有自己的ksoftirqd/n内核线程, n为CPU的逻辑号, 每个这样的内核线程都将执行ksoftirqd()函数:
1static int ksoftirqd(void * __bind_cpu)
2{
3 set_user_nice(current, 19);
4 current->flags |= PF_NOFREEZE;
5
6 set_current_state(TASK_INTERRUPTIBLE);
7
8 while (!kthread_should_stop()) {
9 if (!local_softirq_pending())
10 schedule();
11
12 __set_current_state(TASK_RUNNING);
13
14 while (local_softirq_pending()) {
15 /* Preempt disable stops cpu going offline.
16 If already offline, we'll be on wrong CPU:
17 don't process */
18 preempt_disable();
19 if (cpu_is_offline((long)__bind_cpu))
20 goto wait_to_die;
21 do_softirq();
22 preempt_enable();
23 cond_resched();
24 }
25
26 set_current_state(TASK_INTERRUPTIBLE);
27 }
28 __set_current_state(TASK_RUNNING);
29 return 0;
30
31wait_to_die:
32 preempt_enable();
33 /* Wait for kthread_stop */
34 set_current_state(TASK_INTERRUPTIBLE);
35 while (!kthread_should_stop()) {
36 schedule();
37 set_current_state(TASK_INTERRUPTIBLE);
38 }
39 __set_current_state(TASK_RUNNING);
40 return 0;
41}不予深究函数细节, 其大致完成的工作为: 内核线程被唤醒后, 检查local_softirq_pending以确定是否有未完成的软中断, 如果没有则调用schedule重新进入睡眠; 不然, 则通过一个循环不断调用do_softirq处理软中断. 不过当进程需要时(thread_info的TIF_NEED_RESCHED标志被设置时), 提供偶cond_resched即可实现进程切换.
内核线程为解决重要而难以平衡的问题提供了解决方案:

tasklet
tasklet是IO设备实现可延迟中断的首选方法.
几个tasklet可以与同一个软中断相关联, 每个tasklet都执行自己的函数.
tasklet数据结构
如前所述(
软中断), tasklet建立在两个软中断上: HI_SOFTIRQ和TASKLET_SOFTIRQ, 分别存放在tasklet_hi_vec和tasklet_vec数组中, 二者都包含类型为tasklet_head类型的NR_CPUS个元素:
1/* include/asm-generic/percpu.h */
2/* Separate out the type, so (int[3], foo) works. */
3#define DEFINE_PER_CPU(type, name) \
4 __attribute__((__section__(".data.percpu"))) __typeof__(type) per_cpu__##name
5
6
7/* include/linux/interrupt.h */
8/* Tasklets --- multithreaded analogue of BHs.
9
10 Main feature differing them of generic softirqs: tasklet
11 is running only on one CPU simultaneously.
12
13 Main feature differing them of BHs: different tasklets
14 may be run simultaneously on different CPUs.
15
16 Properties:
17 * If tasklet_schedule() is called, then tasklet is guaranteed
18 to be executed on some cpu at least once after this.
19 * If the tasklet is already scheduled, but its excecution is still not
20 started, it will be executed only once.
21 * If this tasklet is already running on another CPU (or schedule is called
22 from tasklet itself), it is rescheduled for later.
23 * Tasklet is strictly serialized wrt itself, but not
24 wrt another tasklets. If client needs some intertask synchronization,
25 he makes it with spinlocks.
26 */
27
28struct tasklet_struct
29{
30 struct tasklet_struct *next;
31 unsigned long state;
32 atomic_t count;
33 void (*func)(unsigned long);
34 unsigned long data;
35};
36
37
38/* kernel/softirq.c */
39/* Tasklets */
40struct tasklet_head
41{
42 struct tasklet_struct *list;
43};
44
45/* Some compilers disobey section attribute on statics when not
46 initialized -- RR */
47static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec) = { NULL };
48static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec) = { NULL };tasklet_struct描述符字段的含义如下:

其中, state字段有两个标志:
-
TASKLET_STATE_SCHED: 意味着tasklet是被挂起的(曾经被执行), 也意味着tasklet的描述符以及被插入到tasklet_vec或tasklet_hi_vec链表中. -
TASKLET_STATE_RUN: 意味着tasklet正在被执行; 单处理器系统上不使用该标志, 因为没有必要对tasklet的运行状态进行检查.c1enum 2{ 3 TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */ 4 TASKLET_STATE_RUN /* Tasklet is running (SMP only) */ 5};
处理tasklet
考虑一个设备驱动程序, 希望使用tasklet来实现可延迟函数:
首先应该分配(allocate) 一个tasklet_struct结构, 调用tasklet_init进行初始化(initialize):
1void tasklet_init(struct tasklet_struct *t,
2 void (*func)(unsigned long), unsigned long data)
3{
4 t->next = NULL;
5 t->state = 0;
6 atomic_set(&t->count, 0);
7 t->func = func;
8 t->data = data;
9}通过两个函数可以有选择性地禁止(disabled) tasklet:
1static inline void tasklet_disable_nosync(struct tasklet_struct *t)
2{
3 atomic_inc(&t->count);
4 smp_mb__after_atomic_inc();
5}
6
7static inline void tasklet_disable(struct tasklet_struct *t)
8{
9 tasklet_disable_nosync(t);
10 tasklet_unlock_wait(t);
11 smp_mb();
12}- 这两个函数都将增加描述符中的
count字段, 但是后者仅在tasklet实例结束后才返回, 具体函数不予深究.
为了重新启用(reenable) tasklet, 调用tasklet_enable():
1static inline void tasklet_enable(struct tasklet_struct *t)
2{
3 smp_mb__before_atomic_dec();
4 atomic_dec(&t->count);
5}为了激活(activate) tasklet, 则根据需要的优先级, 选择调用tasklet_schedule或者tasklet_hi_schedule函数:
1void fastcall __tasklet_schedule(struct tasklet_struct *t)
2{
3 unsigned long flags;
4
5 local_irq_save(flags);
6 t->next = __get_cpu_var(tasklet_vec).list;
7 __get_cpu_var(tasklet_vec).list = t;
8 raise_softirq_irqoff(TASKLET_SOFTIRQ);
9 local_irq_restore(flags);
10}
11
12EXPORT_SYMBOL(__tasklet_schedule);
13
14void fastcall __tasklet_hi_schedule(struct tasklet_struct *t)
15{
16 unsigned long flags;
17
18 local_irq_save(flags);
19 t->next = __get_cpu_var(tasklet_hi_vec).list;
20 __get_cpu_var(tasklet_hi_vec).list = t;
21 raise_softirq_irqoff(HI_SOFTIRQ);
22 local_irq_restore(flags);
23}
24
25
26static inline void tasklet_schedule(struct tasklet_struct *t)
27{
28 if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
29 __tasklet_schedule(t);
30}
31
32static inline void tasklet_hi_schedule(struct tasklet_struct *t)
33{
34 if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
35 __tasklet_hi_schedule(t);
36}-
首先检查的是
TASKLET_STATE_SCHED标志, 如果已经被设置, 说明tasklet已经进入调度, 直接返回即可. -
在
__tasklet_schedule中, 通过raise_softirq_irqoff禁用中断, 更新每CPU的tasklet_vec相应字段, 执行禁用中断的软中断激活版本raise_softirq_irqoff.
为了执行(execute) tasklet, 通过软中断执行的do_softirq, 最终使用tasklet_action和tasklet_hi_action函数:
1static void tasklet_action(struct softirq_action *a)
2{
3 struct tasklet_struct *list;
4
5 local_irq_disable();
6 list = __get_cpu_var(tasklet_vec).list;
7 __get_cpu_var(tasklet_vec).list = NULL;
8 local_irq_enable();
9
10 while (list) {
11 struct tasklet_struct *t = list;
12
13 list = list->next;
14
15 if (tasklet_trylock(t)) {
16 if (!atomic_read(&t->count)) {
17 if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
18 BUG();
19 t->func(t->data);
20 tasklet_unlock(t);
21 continue;
22 }
23 tasklet_unlock(t);
24 }
25
26 local_irq_disable();
27 t->next = __get_cpu_var(tasklet_vec).list;
28 __get_cpu_var(tasklet_vec).list = t;
29 __raise_softirq_irqoff(TASKLET_SOFTIRQ);
30 local_irq_enable();
31 }
32}-
tasklet_action和tasklet_hi_action十分相似, 仅仅在诸如L6-7, 27-29这类涉及到具体的数组名和中断向量号时有所区别. -
L10开始的循环, 每次处理链表中的一个tasklet任务:
-
tasklet_trylock是用于检查在SMP中当前tasklet是否有RUN标志. 如果拥有该标志, 函数返回0, 说明另一个CPU正在执行同类型的tasklet, 当前任务应当被延迟.c1#ifdef config_smp 2static inline int tasklet_trylock(struct tasklet_struct *t) 3{ 4 return !test_and_set_bit(tasklet_state_run, &(t)->state); 5} 6 7static inline void tasklet_unlock(struct tasklet_struct *t) 8{ 9 smp_mb__before_clear_bit(); 10 clear_bit(tasklet_state_run, &(t)->state); 11} 12 13static inline void tasklet_unlock_wait(struct tasklet_struct *t) 14{ 15 while (test_bit(tasklet_state_run, &(t)->state)) { barrier(); } 16} 17#else 18#define tasklet_trylock(t) 1 19#define tasklet_unlock_wait(t) do { } while (0) 20#define tasklet_unlock(t) do { } while (0) 21#endif -
只有通过了
tasklet_trylock判断且锁计数器为0时, 才真正执行当前tasklet对应的函数, 并且清除SCHED标志. -
如果没有通过上述的测试, 则将tasklet任务重新插回
tasklet_vec所对应的链表中, 并再次激活软中断(L29).
-
-
注意这里对链表的遍历与管理:
-
L6将原先的整个tasklet链表存储到局部变量
list中, L7清空每CPU结构中的tasklet链表. -
在每次循环中, 通过L11,13 来实现对原链表中每个tasklet任务的遍历
-
当tasklet任务不被执行时, 即开始执行L26-的代码段, 会将任务再次插回每CPU结构中的tasklet链表, 等待下次软中断处理时继续执行.
-
需要注意, 除非tasklet函数重新激活自己, 不然, tasklet的每次激活至多触发tasklet函数的一次执行. (这是显而易见的, 当tasklet函数被成功执行后, 便不再会插入链表中)
