本章主要目的为设计和实现支持批处理操作的OS, 其相比于上一节的库OS而言, 主要的不同在于:
-
OS自身运行在内核态; 支持其他应用运行在用户态并发出系统调用
-
一个接一个的运行不同的应用程序
为了实现这些目的, 本章节需要做的事情分为:
-
调整应用程序, 使其能够发出系统调用; 操作系统提供额外的功能支持应用程序的执行, 包括但不限于
sys_write,sys_exit等具体的系统调用功能. -
实现批处理OS, 支持轮流启动不同的应用程序
-
特权级机制, 特权级切换等
特权级软硬件机制
当一些一般的应用程序出错后, 批处理OS可能会受到影响, 单凭软件很难保证其总是全速稳定工作; 通常需要一些CPU的硬件特权隔离机制, 使得CPU在执行不同的指令时可以处于不同的特权级.
为了确保OS的安全, 应用程序的限制主要体现在两方面: 应用程序不能访问任意的地址空间; 应用程序不能执行某些可能破坏计算机系统的指令(本章节的重点). 为了实现这样的限制, 规定低特权应用只能通过系统调用的方式去请求帮助执行高特权指令.
此时, 传统的函数调用方式(call, ret等)将会绕过硬件的特权机制检查, 因而还需要使用一类新的机器指令: ecall执行环境调用和eret执行环境返回来确保用户态和内核态的正确切换. 这些硬件机制还需要对应的软件支持, OS需要提供相关功能使得在eret前及时恢复用户态执行程序的上下文, 在ecall后及时检查应用程序的系统调用参数等, 确保其不会对OS造成破坏.
RISC-V特权架构
RISC-V架构共有4个特权级别, 级别数值越高, 特权级越高.
-
0: 用户/应用模式 (U, User/Application)
-
1: 监督模式 (S, Supervisor)
-
2: 虚拟监督模式 (H, Hypervisor)
-
3: 机器模式 (M, Machine)
一个典型Unix软件执行环境栈和对应的特权级如图所示, 从这个角度来看, 就能更加明确地知道SBI到底是什么位置干的什么事情了!
RISC-V 架构中,只有 M 模式是必须实现的,剩下的特权级则可以根据跑在 CPU 上应用的实际需求进行调整:
简单的嵌入式应用只需要实现 M 模式;
带有一定保护能力的嵌入式系统需要实现 M/U 模式;
复杂的多任务系统则需要实现 M/S/U 模式。
到目前为止,(Hypervisor, H)模式的特权规范还没完全制定好,所以本书不会涉及。
事实上 M/S/U 三个特权级的软件可分别由不同的编程语言实现, 即使是用同一种编程语言实现的, 其调用也并不是普通的函数调用控制流, 而是陷入异常控制流, 在该过程中会切换 CPU 特权级. 因此只有将接口下降到机器/汇编指令级才能够满足其跨高级语言的通用性和灵活性.
当上层软件的执行出现了一些异常的情况(系统调用或执行错误), 其需要用到执行环境中的一些功能, 这个过程往往伴随着CPU的特权级切换. RISC-V异常一览:
| Interrupt | Exception | Code Description |
|---|---|---|
| 0 | 0 | Instruction address misaligned |
| 0 | 1 | Instruction access fault |
| 0 | 2 | Illegal instruction |
| 0 | 3 | Breakpoint |
| 0 | 4 | Load address misaligned |
| 0 | 5 | Load access fault |
| 0 | 6 | Store/AMO address misaligned |
| 0 | 7 | Store/AMO access fault |
| 0 | 8 | Environment call from U-mode |
| 0 | 9 | Environment call from S-mode |
| 0 | 11 | Environment call from M-mode |
| 0 | 12 | Instruction page fault |
| 0 | 13 | Load page fault |
| 0 | 15 | Store/AMO page fault |
其中的3号异常(断点, ebreak)和8,9,11号异常(执行环境调用, ecall)是有意为之的异常, 通常也称为trap.
RISC-V特权指令
与特权级无关额度指令和寄存器(x0-x31)在任何级别下都可以执行, 但是每个特权级都对应一些特殊指令和控制状态寄存器csr.
S模式下有两类特权指令:
-
指令本身属于高特权级的指令, 如
sret指令(从S模式返回到U模式). -
指令访问了S模式特权级下才能访问的寄存器或内存, 如表示S模式系统状态的控制状态寄存器
sstatus等.
特权级切换
特权级切换通常发生于应用程序启动(上下文初始化), 系统调用(发出Trap), 出错, 结束(本质也是系统调用exit)时, 下面说明一些Trap指令与特权级切换的相关内容.
当用户态U发起Trap进入到S特权级后, 有一些与之相关的控制寄存器:
| CSR 名 | 该 CSR 与 Trap 相关的功能 |
|---|---|
| sstatus | SPP 等字段给出 Trap 发生之前 CPU 处在哪个特权级(S/U)等信息 |
| sepc | 当 Trap 是一个异常的时候,记录 Trap 发生之前执行的最后一条指令的地址 |
| scause | 描述 Trap 的原因 |
| stval | 给出 Trap 附加信息 |
| stvec | 控制 Trap 处理代码的入口地址 |
其中, sstatus是S特权级下最重要的CSR, 其中的多个字段从多个方面控制CPU行为和执行状态.
发生特权级切换, 软硬件会协同工作, 下面是一些硬件会自动完成的事情, 剩余的收尾工作可以留给软件, 提高OS的灵活性:
-
陷入时:
-
sstatus 的 SPP 字段会被修改为 CPU 当前的特权级(U/S)。
-
sepc 会被修改为 Trap 处理完成后默认会执行的下一条指令的地址。
-
scause/stval 分别会被修改成这次 Trap 的原因以及相关的附加信息。
-
CPU 会跳转到 stvec 所设置的 Trap 处理入口地址,并将当前特权级设置为 S ,然后从Trap 处理入口地址处开始执行。
-
-
返回时(sret):
-
CPU 会将当前的特权级按照 sstatus 的 SPP 字段设置为 U 或者 S ;
-
CPU 会跳转到 sepc 寄存器指向的那条指令,然后继续执行。
-
在 RV64 中, stvec 是一个 64 位的 CSR,在中断使能的情况下,保存了中断处理的入口地址。它有两个字段:
-
MODE 位于 [1:0],长度为 2 bits;
-
BASE 位于 [63:2],长度为 62 bits。
当 MODE 字段为 0 的时候, stvec 被设置为 Direct 模式, 此时进入 S 模式的 Trap 无论原因如何, 处理 Trap 的入口地址都是 BASE<<2, CPU 会跳转到这个地方进行异常处理. 本书中我们只会将 stvec 设置为 Direct 模式. 而 stvec 还可以被设置为 Vectored 模式, 有兴趣的同学可以自行参考 RISC-V 指令集特权级规范.
用户应用程序设计结构
在ch2下, user目录中存放了有关用户态应用程序的相关代码, 结构如下:
1$ tree user
2user
3├── Cargo.lock
4├── Cargo.toml
5├── Makefile
6└── src
7 ├── bin
8 │ ├── 00hello_world.rs
9 │ ├── 01store_fault.rs
10 │ ├── 02power.rs
11 │ ├── 03priv_inst.rs
12 │ └── 04priv_csr.rs
13 ├── console.rs
14 ├── lang_items.rs
15 ├── lib.rs
16 ├── linker.ld
17 └── syscall.rs
18
193 directories, 13 files就整个结构而言, user/src目录下存放了源码:
-
./user/src/bin/*下的5个文件为5个应用程序
-
./user/src/lib.rs代表这是一个库package, 其中又包含了一些其他模块文件
-
./user/src/linker.ld为内存布局说明. 在ch2的实现中, 自定义的链接脚本将3个应用程序放在
0x80400000, 并且同样地将.text.entry放在整个程序的开头位置; 其余的内容与ch1的基本一致.
应用程序
下面是极简的00号程序, 用于打印简单的字符串.
1#![no_std]
2#![no_main]
3
4#[macro_use]
5extern crate user_lib;
6
7#[no_mangle]
8fn main() -> i32 {
9 println!("Hello, world!");
10 0
11}- L5引用外部库, 该库其实就是./user目录下的cargo项目, user文件夹下的cargo项目配置中写明了项目名称为
user_lib. 其作为bin目录下源程序所依赖的用户库, 等价于其他编程语言提供的标准库.
1[package]
2name = "user_lib"
3...其余的一些应用程序也大致如此, 并无特别的要点.
lib库文件
模块关系
在lib.rs中如此声明了其与其他模块的关系:
1#[macro_use]
2pub mod console;
3mod lang_items;
4mod syscall;-
console为pub模块, 其中包含了ch1所实现的print函数与两个打印宏, 这作为库函数提供给bin下的应用程序
-
lang_items包含了pacnic的实现, 与ch1一样
-
syscall中定义了用户态下系统调用的实现, 其具体内容稍后说明
lib.rs
在ch2分支上, 入口点稍微做了一些调整:
1#[no_mangle]
2#[link_section = ".text.entry"]
3pub extern "C" fn _start() -> ! {
4 clear_bss();
5 exit(main());
6 panic!("unreachable after sys_exit!");
7}
8
9#[linkage = "weak"]
10#[no_mangle]
11fn main() -> i32 {
12 panic!("Cannot find main!");
13}-
L2指明将代码放在
.text.entry段下, 这与ch1中在asm文件中指定的方式有所不同 -
L3添加了
extern "C", 这是一种ABI标记, 指定函数的调用约定, 在这里即是通过C语言的约定来定义该入口点函数. -
L5调用了exit函数, 这是用户库所定义的系统调用接口, 用于通知批处理OS当前程序的结束状态
-
L9指明main函数是一个弱链接, 这是由于最后在链接的时候, 该文件和bin/目录下的应用程序均有
main符号, 通过指定弱链接, 链接器会将bin/下的应用程序作为主程序; 同时, 当子目录下的应用程序出现了一些问题而没有main, 那么链接器也可以找到备用的main符号从而使得编译通过, 不过这样的程序在实际运行时会报错. -
为了支持链接操作, 需要在开头指明可链接的特性:
#![feature(linkage)]
由于引入了系统调用功能, 因而在lib.rs中封装了两个系统调用(write和exit):
1use syscall::*;
2
3pub fn write(fd: usize, buf: &[u8]) -> isize {
4 sys_write(fd, buf)
5}
6pub fn exit(exit_code: i32) -> isize {
7 sys_exit(exit_code)
8}系统调用
在子模块syscall中, 主要是使用rust函数封装RISC-V的ecall汇编指令. 根据RISC-V的调用规范(ABI格式要求), 在合适的寄存器放合适的调用参数, 并使用ecall指令触发trap, 触发Environment call from U-mode异常, 从U模式进入S模式, 完成后返回, 从ecall的下一条指令继续执行.
有关RISC-V的调用规范参考 riscv-spec.pdf, 发现这竟是6.828的参考资料, 当初做lab的时候其实做的真的好粗糙..
有关函数调用栈的打印, 涉及到调用规范(Calling Convention), 其约定了某个指令集架构上, 某种编程语言的函数调用如何实现; 主要包括:
-
函数的输入参数和返回值如何传递;
-
函数调用上下文中调用者(Caller)/被调用者(Callee)保存寄存器的划分;
-
其他的在函数调用流程中对于寄存器的使用方法.
调用规范是对于一种确定的编程语言来说的, 因为一般意义上的函数调用只会在编程语言的内部进行.
来源: 为内核支持函数调用 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
Tips: 关于各个寄存器是Caller/Callee-Saver则可以参考上文中的 系统调用
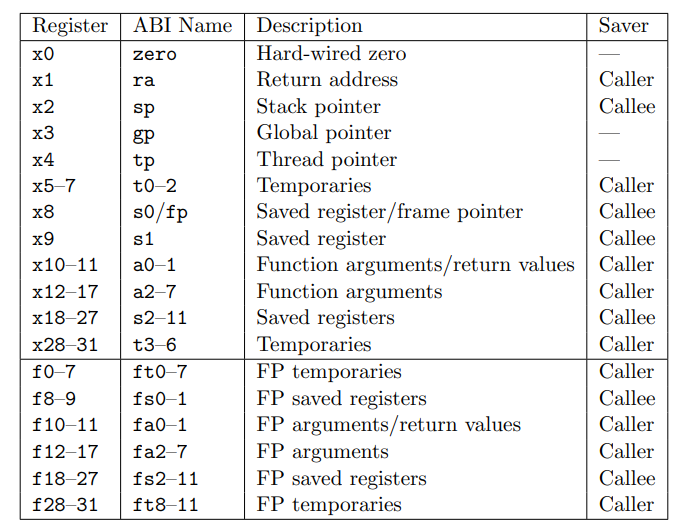
结合上表所示, a0-6为函数调用的参数, a0保存系统调用的返回值, a7用来传递syscall ID. 因而, 由此对应的rust代码如下:
1fn syscall(id: usize, args: [usize; 3]) -> isize {
2 let mut ret: isize;
3 unsafe {
4 asm!(
5 "ecall",
6 inlateout("x10") args[0] => ret,
7 in("x11") args[1],
8 in("x12") args[2],
9 in("x17") id
10 );
11 }
12 ret
13}在ch1中曾经使用 global_asm! 宏来嵌入全局汇编代码, 而这里的 asm! 宏可以将汇编代码嵌入到局部的函数上下文中. 相比 global_asm! , asm! 宏可以获取上下文中的变量信息并允许嵌入的汇编代码对这些变量进行操作. 由于编译器的能力不足以判定插入汇编代码这个行为的安全性, 所以我们需要将其包裹在 unsafe 块中自己来对它负责.
如果内联汇编完全由自己写其实非常的头疼, 如果希望将id放入a7, 那么id这个值本身在哪个寄存器并不为程序员所知, 这也是需要内联汇编帮助的原因. 在这里, 使用in关键字指定什么值最终将放入什么寄存器中, 而使用inlateout表示其同时作为输入和输出.
Rust的asm宏看上去比C的内联汇编貌似要优雅一些, 毕竟是一个更加崭新的语言, 在Rust写内联汇编或许会有一些更加好的体验. 答辩体验可以参考: C内联汇编-AT&T - rqdmap | blog
两个系统调用的实现如下:
1const SYSCALL_WRITE: usize = 64;
2const SYSCALL_EXIT: usize = 93;
3
4pub fn sys_write(fd: usize, buffer: &[u8]) -> isize {
5 syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()])
6}
7
8pub fn sys_exit(xstate: i32) -> isize {
9 syscall(SYSCALL_EXIT, [xstate as usize, 0, 0])
10}- 使用一个
&[u8]切片类型来描述缓冲区, 这是一个胖指针, 里面既包含缓冲区的起始地址, 还包含缓冲区的长度. 我们可以分别通过as_ptr和len方法取出它们并独立地作为实际的系统调用参数. 与C中不同, C中如果传递一个数组指针, 那么传递的参数其实只是一个指针, 并不像胖指针一样其中还包含了缓冲区的长度.
由于目前已经实现了write的系统调用, 因而可以不再使用sbi提供的putchar功能, 而修改为write调用:
1const STDOUT: usize = 1;
2
3impl Write for Stdout {
4 fn write_str(&mut self, s: &str) -> fmt::Result {
5 write(STDOUT, s.as_bytes());
6 Ok(())
7 }
8}而有关用户态的系统调用如何与操作系统进行交互可以参考后续章节
Trap管理有关ecall相关的处理逻辑.
Qemu用户态模拟
仅仅实现了用户态的程序能否进行真机调试呢? Qemu提供了这样的用户态工具. qemu-system-riscv64是RISC-V 64计算机的系统模拟器, 而qemu-riscv64是RISC-V 64的Qemu用户态模拟器.
Qemu 有两种运行模式:用户态模拟(User mode)和系统级模拟(System mode)。在 RISC-V 架构中,用户态模拟可使用 qemu-riscv64 模拟器,它可以模拟一台预装了 Linux 操作系统的 RISC-V 计算机。但是一般情况下我们并不通过输入命令来与之交互(就像我们正常使用 Linux 操作系统一样),它仅支持载入并执行单个可执行文件。具体来说,它可以解析基于 RISC-V 的应用级 ELF 可执行文件,加载到内存并跳转到入口点开始执行。在翻译并执行指令时,如果碰到是系统调用相关的汇编指令,它会把不同处理器(如 RISC-V)的 Linux 系统调用转换为本机处理器(如 x86-64)上的 Linux 系统调用,这样就可以让本机 Linux 完成系统调用,并返回结果(再转换成 RISC-V 能识别的数据)给这些应用。相对的,我们使用 qemu-system-riscv64 模拟器来系统级模拟一台 RISC-V 64 裸机,它包含处理器、内存及其他外部设备,支持运行完整的操作系统。
使用cargo build --release生成可执行文件, 随后使用qemu-riscv64 ./00hello_world即可在半模拟的场景下执行该可执行文件. 不过在我的环境下, 哪怕是hello world都会段错误… 看该章节的评论区发现好像大家也遇到过这个问题而且解决方案各不相同, 据传qemu-7.0可以正常, 更新版本的则会出现问题. 而我的qemu已经是8.0.2的超级崭新出厂了.. 那算了, 忍耐该瑕疵接着往后看看就是了!
批处理操作系统设计
在os目录下的cargo项目文件夹为操作系统的相关设计代码.
1$ tree os
2os
3├── build.rs
4├── Cargo.lock
5├── Cargo.toml
6├── Makefile
7└── src
8 ├── batch.rs
9 ├── console.rs
10 ├── entry.asm
11 ├── lang_items.rs
12 ├── link_app.S
13 ├── linker-qemu.ld
14 ├── logging.rs
15 ├── main.rs
16 ├── sbi.rs
17 ├── sync
18 │ ├── mod.rs
19 │ └── up.rs
20 ├── syscall
21 │ ├── fs.rs
22 │ ├── mod.rs
23 │ └── process.rs
24 └── trap
25 ├── context.rs
26 ├── mod.rs
27 └── trap.S
28
295 directories, 21 filesCargo构建脚本
注意到一个最不同的地方在于, 通常的源码文件存在与src/目录下, 在这里根目录下就存在了一个特殊的rs文件: build.rs, 这其实是Cargo的构建脚本.
在项目被构建之前, Cargo 会将构建脚本编译成一个可执行文件, 然后运行该文件并执行相应的任务.
在运行的过程中, 脚本可以使用之前 println 的方式跟 Cargo 进行通信: 通信内容是以 cargo: 开头的格式化字符串. 通过 println! 输出的内容在构建过程中默认是隐藏的, 如果大家想要在终端中看到这些内容, 你可以使用 -vv 参数来显示.
在这里, 我们看到:
1use std::fs::{read_dir, File};
2use std::io::{Result, Write};
3
4fn main() {
5 println!("cargo:rerun-if-changed=../user/src/");
6 println!("cargo:rerun-if-changed={}", TARGET_PATH);
7 insert_app_data().unwrap();
8}
9
10static TARGET_PATH: &str = "../user/target/riscv64gc-unknown-none-elf/release/";-
cargo:rerun-if-changed=...代表当目标目录下的文件发生变化时则重新运行该构建脚本 -
main中使用的变量
TARGET_PATH为下面才定义的静态常量, 这与C不同, C中不允许先使用一些后面才定义的静态常量.
构建脚本中的insert_app_data函数则具体生成这样一份汇编文件:
1 .align 3
2 .section .data
3 .global _num_app
4_num_app:
5 .quad 5
6 .quad app_0_start
7 .quad app_1_start
8 .quad app_2_start
9 .quad app_3_start
10 .quad app_4_start
11 .quad app_4_end
12
13 .section .data
14 .global app_0_start
15 .global app_0_end
16app_0_start:
17 .incbin "../user/target/riscv64gc-unknown-none-elf/release/00hello_world.bin"
18app_0_end:
19
20 .section .data
21 .global app_1_start
22 .global app_1_end
23app_1_start:
24 .incbin "../user/target/riscv64gc-unknown-none-elf/release/01store_fault.bin"
25app_1_end:
26
27 .section .data
28 .global app_2_start
29 .global app_2_end
30app_2_start:
31 .incbin "../user/target/riscv64gc-unknown-none-elf/release/02power.bin"
32app_2_end:
33
34 .section .data
35 .global app_3_start
36 .global app_3_end
37app_3_start:
38 .incbin "../user/target/riscv64gc-unknown-none-elf/release/03priv_inst.bin"
39app_3_end:
40
41 .section .data
42 .global app_4_start
43 .global app_4_end
44app_4_start:
45 .incbin "../user/target/riscv64gc-unknown-none-elf/release/04priv_csr.bin"
46app_4_end:-
L3开辟了一个64位的数组, 记录几个app的起始位置, 该数组第一个元素为app的数量, 后面按顺序排放应用程序的地址.
- 不太记得汇编中数组的长度是如何定义的, 特别是这里, 默认按照这样的语法写就是一个长度为7的数组吧应该, 那么如果我希望定义第二个数组应该怎么写? 大概直接再定义一个.global符号即可, 毕竟从本质上来说, 数组名就是一个指针而已, 其中也不会包含诸如当前数组有几个元素这样的内容, 在汇编的层面如何保证不越界什么的问题那是汇编程序员考虑的问题
-
L13的数据段开始, 依次插入5个app去除了ELF元数据的二进制镜像, 并各自有一对全局符号说明其起始和终止的位置.
-
为了实际使用上该汇编文件, 还需要在main.rs中添加上:
global_asm!(include_str!("link_app."));
应用管理器
在./src目录下的几个文件大部分都与ch1一致, 多出来的一个batch.rs负责批处理操作系统的一些核心功能, 其中一个组件便是负责管理与加载不同应用程序的应用管理器.
应用管理器的结构如下, 字段的含义是望文生义的:
1struct AppManager {
2 num_app: usize,
3 current_app: usize,
4 app_start: [usize; MAX_APP_NUM + 1],
5}结构体封装
自然的, 我们希望AppManager是一个全局可以访问、修改的变量, 在Rust中可以使用static mut类型的变量, 不过这种变量的访问都是unsafe的, 编程中尽量应该避免使用unsafe. 为此引入的解决方案是内部可变性, 由此开的新坑位于:
Rust中的智能指针 - rqdmap | blog. 使用RefCell包裹AppManager, 这样RefCell无需声明为mut, 同时也能使用borrow_mut修改内部包裹的AppManager的值.
事实上, RefCell内部也是基于unsafe实现的, 不过使用了安全的api封装, 这比我们自己使用unsafe代码块要安全的多.
此外, 由于学习rCore项目是遵循学习Rust为主, OS为辅的路线, 因而遇到了一些Rust稍进阶的内容也会触发中断去开新坑:)
那么能否设置一个全局RefCell呢? 写一个简单的程序测试一下:
1use std::cell::RefCell;
2static A: RefCell<i32> = RefCell::new(3);
3fn main() {
4 *A.borrow_mut() = 4;
5 println!("{}", A.borrow());
6}会得到报错:
1error[E0277]: `RefCell<i32>` cannot be shared between threads safely
2 --> src/main.rs:2:11
3 |
42 | static A: RefCell<i32> = RefCell::new(3);
5 | ^^^^^^^^^^^^ `RefCell<i32>` cannot be shared between threads safely
6 |
7 = help: the trait `Sync` is not implemented for `RefCell<i32>`
8 = note: if you want to do aliasing and mutation between multiple threads, use `std::sync::RwLock` instead
9 = note: shared static variables must have a type that implements `Sync`这是由于多线程之间共享的结构必须实现了Sync特征, RefCell未实现该特征也就不能作为全局变量使用.
由于孤儿原则, 我们对RefCell做一层封装后, 再打上Sync特征标记, 并为其实现了两个函数/方法:
1// os/src/sync/up.rs
2
3pub struct UPSafeCell<T> {
4 inner: RefCell<T>,
5}
6
7unsafe impl<T> Sync for UPSafeCell<T> {}
8
9impl<T> UPSafeCell<T> {
10 pub unsafe fn new(value: T) -> Self {
11 Self { inner: RefCell::new(value) }
12 }
13 /// Panic if the data has been borrowed.
14 pub fn exclusive_access(&self) -> RefMut<'_, T> {
15 self.inner.borrow_mut()
16 }
17}-
标记
Sync是一个unsafe行为, 有关unsafe的超能力可以先简单参考: Unsafe Rust - Rust语言圣经(Rust Course). 标记了Sync意味着向编译器保证该类型可以在多线程间安全的共享, 我们能够做出这样的保证的原因有两点: 当前的rCore只运行在单核; RefCell提供了运行时的借用检查功能, 保证Rust的内存安全 -
关联函数new也打上了
unsafe, 这其实有点迷惑, 打上了unsafe会有什么好处吗? 由于目前对于多线程/unsafe都不太了解, 因而还是不明个中道理.. 一个评论是:首先 new 被声明为一个 unsafe 函数,是因为我们希望使用者在创建一个 UPSafeCell 的时候保证在访问 UPSafeCell 内包裹的数据的时候始终不违背上述模式:即访问之前调用 exclusive_access ,访问之后销毁借用标记再进行下一次访问。这只能依靠使用者自己来保证,但我们提供了一个保底措施:当使用者违背了上述模式,比如访问之后忘记销毁就开启下一次访问时,程序会 panic 并退出。
或是是我理解有误,但是不是就算不将new函数声明为unsafe,仅仅是exclusive_access的实现就确保了,若引用未销毁就开启下一次访问,便会导致panic的功能(因为对refCell来说,只能同时允许一个borrow_mut引用,而我们只允许了外部使用borrow_mut来访问inner实例)。
如果在单线程上基于RefCell的确可以确保安全性。但是现在UPSafeCell是用来包裹可能被多线程并发访问的数据结构,而RefCell并不是线程安全的,也即并没有实现Sync Trait。因此这里的unsafe是需要调用者保证以线程安全的方式使用UPSafeCell:也即在获取与释放操作的中间不能进行执行流(或称线程)的切换。
- 其意思是, unsafe可以保证获取与释放操作该结构体的的中间不能进行执行流(或称线程)的切换吗?
-
exclusive_access封装borrow_mut, 返回的类型是RefMut<'_, T>; 这个是一个引用类型为T的数据的可变引用.
主要区别如下:
-
静态检查:在编译时,Rust 的借用规则会静态地分析代码,并确保不会同时存在多个可变引用,以避免数据竞争。因此,使用 mut &T 进行可变借用时,需要满足严格的静态生命周期和借用规则。而 RefMut 利用 RefCell 的动态借用检查机制,在运行时进行借用约束的检查。
-
动态借用检查:RefMut 在运行时进行借用约束的检查,可以在某些情况下绕过静态借用检查规则。这意味着可以在同一作用域中拥有多个可变引用。但是,如果违反了 RefCell 的借用约束,例如创建了悬垂指针或者发生数据竞争,程序将会 panic。
-
所有权转移:mut &T 可以通过可变引用对值进行修改,但是所有权仍然属于原始持有者。而 RefMut 并不具备掌握所有权的能力,它只是提供了对 RefCell 内部数据的可变引用。
总之,mut &T 是 Rust 的静态借用机制,要求满足严格的编译时借用规则;而 RefMut 是基于 RefCell 的动态借用机制,可以在运行时进行借用约束的检查,并允许在一定条件下拥有多个可变引用。
来源: ChatGPT
全局变量初始化
实现了UPSafeCell的封装后, 需要提供合适的初始化代码.
1// os/src/batch.rs
2lazy_static! {
3 static ref APP_MANAGER: UPSafeCell<AppManager> = unsafe { UPSafeCell::new({
4 extern "C" { fn _num_app(); }
5 let num_app_ptr = _num_app as usize as *const usize;
6 let num_app = num_app_ptr.read_volatile();
7 let mut app_start: [usize; MAX_APP_NUM + 1] = [0; MAX_APP_NUM + 1];
8 let app_start_raw: &[usize] = core::slice::from_raw_parts(
9 num_app_ptr.add(1), num_app + 1
10 );
11 app_start[..=num_app].copy_from_slice(app_start_raw);
12 AppManager {
13 num_app,
14 current_app: 0,
15 app_start,
16 }
17 })};
18}-
整个初始化代码被
lazy_static!宏包裹, 该宏由lazy_static提供, 需要引用依赖:toml1# os/Cargo.toml 2[dependencies] 3lazy_static = { version = "1.4.0", features = ["spin_no_std"] }
lazy_static! 宏提供了全局变量的运行时初始化功能.
一般情况下, 全局变量必须在编译期设置一个初始值, 但是有些全局变量依赖于运行期间才能得到的数据作为初始值. 这导致这些全局变量需要在运行时发生变化, 即需要重新设置初始值之后才能使用. 如果我们手动实现的话有诸多不便之处, 比如需要把这种全局变量声明为 static mut 并衍生出很多 unsafe 代码 . 这种情况下我们可以使用 lazy_static! 宏来帮助我们解决这个问题.
这里我们借助 lazy_static! 声明了一个 AppManager 结构的名为 APP_MANAGER 的全局实例, 且只有在它第一次被使用到的时候, 才会进行实际的初始化工作.
- 而实际的初始化代码逻辑也比较简单, 找到汇编文件中的符号
_num_app, 从该符号地址解析出app的数量和起始地址, 将结果存放在Rust切片中.
这样就可以以较少的unsafe代码实现全局变量的初始化工作了.
方法实现
再来看看rCore为AppManager实现了什么关联函数/成员方法.
1impl AppManager {
2 pub fn print_app_info(&self) {
3 println!("[kernel] num_app = {}", self.num_app);
4 for i in 0..self.num_app {
5 println!(
6 "[kernel] app_{} [{:#x}, {:#x})",
7 i,
8 self.app_start[i],
9 self.app_start[i + 1]
10 );
11 }
12 }
13
14 unsafe fn load_app(&self, app_id: usize) {
15 if app_id >= self.num_app {
16 println!("All applications completed!");
17 shutdown(false);
18 }
19 println!("[kernel] Loading app_{}", app_id);
20 // clear app area
21 core::slice::from_raw_parts_mut(APP_BASE_ADDRESS as *mut u8, APP_SIZE_LIMIT).fill(0);
22 let app_src = core::slice::from_raw_parts(
23 self.app_start[app_id] as *const u8,
24 self.app_start[app_id + 1] - self.app_start[app_id],
25 );
26 let app_dst = core::slice::from_raw_parts_mut(APP_BASE_ADDRESS as *mut u8, app_src.len());
27 app_dst.copy_from_slice(app_src);
28 // Memory fence about fetching the instruction memory
29 // It is guaranteed that a subsequent instruction fetch must
30 // observes all previous writes to the instruction memory.
31 // Therefore, fence.i must be executed after we have loaded
32 // the code of the next app into the instruction memory.
33 // See also: riscv non-priv spec chapter 3, 'Zifencei' extension.
34 asm!("fence.i");
35 }
36
37 pub fn get_current_app(&self) -> usize {
38 self.current_app
39 }
40
41 pub fn move_to_next_app(&mut self) {
42 self.current_app += 1;
43 }
44}-
调试用关联函数
print_app_info, 两个简单的成员函数:get_current_app,move_to_next_app -
load_app加载一个指定的app-
L21首先清空内存区域, L22-27随后再将指定的app的代码数据复制到指定的区域即可.
-
最后的
fence.i与指令缓存有关, 当OS操作了程序的代码段后, 指令缓存可能与内存中的指令不一致,fenci.i取值屏障的作用便是保证在它之后的取指过程必须能够看到在它之前的所有对于取指内存区域的修改, 这样CPU访问的应用代码就总是最新的而不是i-cache中过时的内容; 至于硬件如何实现该功能, 比如清零所有指令缓存内容或打上非法标记则由硬件自己决定.
-
至少在 Qemu 模拟器的默认配置下, 各类缓存如 i-cache/d-cache/TLB 都处于机制不完全甚至完全不存在的状态. 目前在 Qemu 平台上, 即使我们不加上刷新 i-cache 的指令, 大概率也是能够正常运行的. 但在 K210 物理计算机上, 如果没有执行汇编指令 fence.i , 就会产生由于指令缓存的内容与对应内存中指令不一致导致的错误异常.
用户栈与内核栈
Trap触发时, CPU就将切换特权级并跳转到stvec指定的处理位置,但是在进入Trap处理前必须要保存原本的上下文信息, 这一般就是通过内核栈来实现.
1const USER_STACK_SIZE: usize = 4096 * 2;
2const KERNEL_STACK_SIZE: usize = 4096 * 2;
3
4#[repr(align(4096))]
5struct KernelStack {
6 data: [u8; KERNEL_STACK_SIZE],
7}
8
9#[repr(align(4096))]
10struct UserStack {
11 data: [u8; USER_STACK_SIZE],
12}
13
14static KERNEL_STACK: KernelStack = KernelStack {
15 data: [0; KERNEL_STACK_SIZE],
16};
17static USER_STACK: UserStack = UserStack {
18 data: [0; USER_STACK_SIZE],
19};
20
21impl KernelStack {
22 fn get_sp(&self) -> usize {
23 self.data.as_ptr() as usize + KERNEL_STACK_SIZE
24 }
25 pub fn push_context(&self, cx: TrapContext) -> &'static mut TrapContext {
26 let cx_ptr = (self.get_sp() - core::mem::size_of::<TrapContext>()) as *mut TrapContext;
27 unsafe {
28 *cx_ptr = cx;
29 }
30 unsafe { cx_ptr.as_mut().unwrap() }
31 }
32}
33
34impl UserStack {
35 fn get_sp(&self) -> usize {
36 self.data.as_ptr() as usize + USER_STACK_SIZE
37 }
38}-
两个常数指示栈的大小, 这类全局的常量变量将直接存放在
.bss段中. -
get_sp获取栈顶指针, 由于栈从高向低增长, 因而初始时获取数组结尾的指针就是sp的位置. -
push_context保存上下文信息. 上下文信息封装在结构体TrapContext中, 有关该结构体我们马上就会更加详细的展示; 此时我们先看一些有关Rust语法的内容:-
L26的as类型转换, 目标类型
*mut T是什么? 乍一看好像认识, 但其实并不认识:(这其实是Rust的原始指针类型, 前缀为
*, 需要使用unsafe代码块来解引用他们. 有两种原始指针, 不可变原始指针*const T和可变原始指针*mut T, 前者支持Copy特征; 此外, 可以将一个可变引用转化为不可变引用(这称为指针弱化), 但反之不行. -
L30 中为何需要
as_mut? 参考 额外的操作 - Rust语言圣经(Rust Course)中的一些说明:为了存储引用,这里使用 Option 来包裹,并通过 ptr::as_ref 和 ptr::as_mut 来将裸指针转换成引用。
rust1pub struct IterMut<'a, T> { 2 next: Option<&'a mut Node<T>>, 3} 4 5impl<T> List<T> { 6 ... 7 pub fn iter_mut(&mut self) -> IterMut<'_, T> { 8 unsafe { 9 IterMut { next: self.head.as_mut() } 10 } 11}那么可以大胆猜测,
as_mut会解原始指针, 使其成为一个引用, 返回的结果是一个Option类型, 因而还需要unwrap快速解构该类型. 这一块确实还很玄乎, 等之后学完了unsafe编程后再考虑回头思考一下. -
另一个问题是返回值的生命周期(L25), 教程中并未说明为什么声明为`static全局生命周期; 我不理解的地方在于: 这个变量到底是不是确实是全局的生命周期? 如果是全局生命周期又如何被Rustc所检查/验证(因为生命周期标注只是提示编译器, 而并不修改其真实的生命周期长度)? 带有unsafe语句块中的原始指针后又会有什么新的变化吗? 这块可能也牵扯了生命周期的高阶知识, 暂时留坑.
-
Trap管理
Trap上下文TrapContext中存储了一些需要保存的物理资源, 如下所示.
1use riscv::register::sstatus::{self, Sstatus, SPP};
2/// Trap Context
3#[repr(C)]
4pub struct TrapContext {
5 /// general regs[0..31]
6 pub x: [usize; 32],
7 /// CSR sstatus
8 pub sstatus: Sstatus,
9 /// CSR sepc
10 pub sepc: usize,
11}这是最重要的"repr". 它的意图相当简单: 做 C 所做的事. 字段的顺序、大小和对齐方式与你在 C 或 C++ 中期望的完全一样. 任何你期望通过 FFI 边界的类型都应该有repr(C), 因为 C 是编程世界的语言框架. 这对于合理地使用数据布局做更多的技巧也是必要的, 比如将值重新解释为不同的类型.
如何选择保存哪些信息?
-
对于通用寄存器而言, 由于Trap控制流可能也会调用许多不同的模块, 很难去判断应该保存哪些寄存器, 还是将32个全部保存为妙; 尽管诸如x0(硬编码为0)等寄存器通常不会变化, 但是还是为其预留空间以便后续的实现方便.
-
对于CSR而言,
scause/stval在trap的开始就将被使用/存储, 而sstatus/sepc一直会被使用(如sret返回时), 因而需要保存这两个寄存器内容.
上下文的保存与恢复
当rCore批处理内核加载时, 会执行os/src/trap/mod.rs中的初始化函数:
1global_asm!(include_str!("trap.S"));
2
3/// initialize CSR `stvec` as the entry of `__alltraps`
4pub fn init() {
5 extern "C" {
6 fn __alltraps();
7 }
8 unsafe {
9 stvec::write(__alltraps as usize, TrapMode::Direct);
10 }
11}首先看到该文件引入的外部汇编文件trap.S, 该部分汇编代码涉及上下文的保存与恢复:
1.altmacro
2.macro SAVE_GP n
3 sd x\n, \n*8(sp)
4.endm
5.macro LOAD_GP n
6 ld x\n, \n*8(sp)
7.endm
8 .section .text
9 .globl __alltraps
10 .globl __restore
11 .align 2
12__alltraps:
13 csrrw sp, sscratch, sp
14 # now sp->kernel stack, sscratch->user stack
15 # allocate a TrapContext on kernel stack
16 addi sp, sp, -34*8
17 # save general-purpose registers
18 sd x1, 1*8(sp)
19 # skip sp(x2), we will save it later
20 sd x3, 3*8(sp)
21 # skip tp(x4), application does not use it
22 # save x5~x31
23 .set n, 5
24 .rept 27
25 SAVE_GP %n
26 .set n, n+1
27 .endr
28 # we can use t0/t1/t2 freely, because they were saved on kernel stack
29 csrr t0, sstatus
30 csrr t1, sepc
31 sd t0, 32*8(sp)
32 sd t1, 33*8(sp)
33 # read user stack from sscratch and save it on the kernel stack
34 csrr t2, sscratch
35 sd t2, 2*8(sp)
36 # set input argument of trap_handler(cx: &mut TrapContext)
37 mv a0, sp
38 call trap_handler
39
40__restore:
41 # case1: start running app by __restore
42 # case2: back to U after handling trap
43 mv sp, a0
44 # now sp->kernel stack(after allocated), sscratch->user stack
45 # restore sstatus/sepc
46 ld t0, 32*8(sp)
47 ld t1, 33*8(sp)
48 ld t2, 2*8(sp)
49 csrw sstatus, t0
50 csrw sepc, t1
51 csrw sscratch, t2
52 # restore general-purpuse registers except sp/tp
53 ld x1, 1*8(sp)
54 ld x3, 3*8(sp)
55 .set n, 5
56 .rept 27
57 LOAD_GP %n
58 .set n, n+1
59 .endr
60 # release TrapContext on kernel stack
61 addi sp, sp, 34*8
62 # now sp->kernel stack, sscratch->user stack
63 csrrw sp, sscratch, sp
64 sret-
开头的
altmacro用于启用一组另外的宏模式, 在文档 T-HEAD+RISC-V+AS+Manual+V1.4.2.pdf的7.4节查到了一些说明, 不过在这里我们只需要知道: 启用了该模式, 才能正常使用后续的.rept等命令. -
定义两个宏, 具体的语法暂且不管, 有点像C语言宏的
##, 传入变量n, 通过\n来做字符串替换. -
随后声明代码段, 给出两个全局符号, 即为后续两段代码的起始位置
-
指定4字节对齐方式, 这里需要注意,
.align后跟的是log2后的值, 参考文档: RISC-V-Directives (Using as); 因而.align 2表示4字节对齐! -
__alltraps逻辑:
-
L13中
csrrw rd, csr, rs的作用是rd <- csr; csr <- rs; 因而在这里的作用是交换sp和sscratch, 其中sscratch其实是内核栈. -
交换完成后, sp指向内核栈, 预分配38个字节, 随后将x0-31(跳过一些无用的寄存器), t0-1(通过指令csrr控制状态寄存器read)塞进去; 这与Rust的
TrapContext也是一一对应的. -
根据riscv调用规范, x2寄存器的abi名称为sp, 记录栈指针, 因而将用户栈的地址读出后放在该位置.
-
将sp移动到a0上, 作为函数参数, 调用
trap_handlerrust高级代码,pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext
-
-
当call指令完成后, 将进入下一条asm代码, 即__restore逻辑:
-
L43将
trap_handler的返回值装载进入sp, 返回值还是内核栈, 并没有被改变过. -
装载CSR和通用寄存器回去, sp收缩, 交换sp和sscratch, 切换为原本的用户栈, sret结束.
-
Trap处理
上面的汇编代码负责上下文的保存与恢复, 下面再进入rust高级代码trap_handler看看Trap具体是如何被处理的:
1// os/src/trap/mod.rs
2use riscv::register::{
3 mtvec::TrapMode,
4 scause::{self, Exception, Trap},
5 stval, stvec,
6};
7
8#[no_mangle]
9/// handle an interrupt, exception, or system call from user space
10pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext {
11 let scause = scause::read(); // get trap cause
12 let stval = stval::read(); // get extra value
13 match scause.cause() {
14 Trap::Exception(Exception::UserEnvCall) => {
15 cx.sepc += 4;
16 cx.x[10] = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]) as usize;
17 }
18 Trap::Exception(Exception::StoreFault) | Trap::Exception(Exception::StorePageFault) => {
19 println!("[kernel] PageFault in application, kernel killed it.");
20 run_next_app();
21 }
22 Trap::Exception(Exception::IllegalInstruction) => {
23 println!("[kernel] IllegalInstruction in application, kernel killed it.");
24 run_next_app();
25 }
26 _ => {
27 panic!(
28 "Unsupported trap {:?}, stval = {:#x}!",
29 scause.cause(),
30 stval
31 );
32 }
33 }
34 cx
35}- 借助Rust提供的riscv库可以比较方便的操作riscv的寄存器以及各种Trap, 使用方法只需要在cargo.toml中添加:
1[dependencies]
2riscv = { git = "https://github.com/rcore-os/riscv", features = ["inline-asm"] }-
L14-17处理
UserEnvCall, 用户环境的调用, 即系统调用.-
处理第一步是修改
sepc, 使其加4(ecall指令的长度), 成为发生trap指令的下一条指令; 这是由于硬件在trap返回后会进入sepc的地址继续执行. -
根据a7系统调用id, 传入a0-2作为调用参数, 执行系统调用, 将调用返回值存放在a0返回, 这是正常的系统调用流程.
-
-
L18-25分别处理程序访存错误和非法指令错误, 处理方案是直接调用
run_next_app函数运行下一个函数. -
L26-32处理不支持的trap类型, 直接panic整个系统.
-
最后返回cx, 内核栈其实没有变化过, 还是原本的内核栈的地址, 不太清楚为什么一定要再返回一遍..
系统调用实现
上节草草出现了个syscall函数, 需要与用户态的syscall加以区分. 其仅仅是名称一致, 但具体工作的环境以及实现的方式均有所不同.
在批处理内核中, syscall仅仅根据任务id进行任务分发:
1// os/src/syscall/mod.rs
2
3pub fn syscall(syscall_id: usize, args: [usize; 3]) -> isize {
4 match syscall_id {
5 SYSCALL_WRITE => sys_write(args[0], args[1] as *const u8, args[2]),
6 SYSCALL_EXIT => sys_exit(args[0] as i32),
7 _ => panic!("Unsupported syscall_id: {}", syscall_id),
8 }
9}而具体的任务则由sys_xxx系列函数进行实际的执行:
1// os/src/syscall/fs.rs
2const FD_STDOUT: usize = 1;
3
4pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize {
5 match fd {
6 FD_STDOUT => {
7 let slice = unsafe { core::slice::from_raw_parts(buf, len) };
8 let str = core::str::from_utf8(slice).unwrap();
9 print!("{}", str);
10 len as isize
11 },
12 _ => {
13 panic!("Unsupported fd in sys_write!");
14 }
15 }
16}
17
18// os/src/syscall/process.rs
19pub fn sys_exit(xstate: i32) -> ! {
20 println!("[kernel] Application exited with code {}", xstate);
21 run_next_app()
22}功能函数与程序执行
有了以上所有功能的支持, 我们总算可以为批处理操作系统实现最为重要的几个关键功能函数:
1/// init batch subsystem
2pub fn init() {
3 print_app_info();
4}
5
6/// print apps info
7pub fn print_app_info() {
8 APP_MANAGER.exclusive_access().print_app_info();
9}
10
11/// run next app
12pub fn run_next_app() -> ! {
13 let mut app_manager = APP_MANAGER.exclusive_access();
14 let current_app = app_manager.get_current_app();
15 unsafe {
16 app_manager.load_app(current_app);
17 }
18 app_manager.move_to_next_app();
19 drop(app_manager);
20 // before this we have to drop local variables related to resources manually
21 // and release the resources
22 extern "C" {
23 fn __restore(cx_addr: usize);
24 }
25 unsafe {
26 __restore(KERNEL_STACK.push_context(TrapContext::app_init_context(
27 APP_BASE_ADDRESS,
28 USER_STACK.get_sp(),
29 )) as *const _ as usize);
30 }
31 panic!("Unreachable in batch::run_current_app!");
32}其中run_next_app最为重要, 用于切换到下一个应用程序进行执行:
-
使用appmanager装载一个新的程序到地址空间, 这里需要注意
current_app指向的是下一个即将装载的app, 这可以通过对该变量的更新进行验证: L16装载完current_app上的app后, L18进行一次自增操作, 这意味者下一次装载时装载的正是后一个应用程序. -
unsafe块包裹汇编代码, 为
__restore传递一个上下文信息作为参数, 这为__restore第一步中将sp置为a0提供了依据(兼容应用切换和一般的系统调用), 具体看到函数内部:-
KERNEL_STACK.push_context函数将传递进来的内容复制到内核栈中, 并返回其对应的内核栈地址 -
app_init_context关联函数如下定义:rust1// os/src/trap/context.rs 2impl TrapContext { 3 /// set stack pointer to x_2 reg (sp) 4 pub fn set_sp(&mut self, sp: usize) { 5 self.x[2] = sp; 6 } 7 /// init app context 8 pub fn app_init_context(entry: usize, sp: usize) -> Self { 9 let mut sstatus = sstatus::read(); // CSR sstatus 10 sstatus.set_spp(SPP::User); //previous privilege mode: user mode 11 let mut cx = Self { 12 x: [0; 32], 13 sstatus, 14 sepc: entry, // entry point of app 15 }; 16 cx.set_sp(sp); // app's user stack pointer 17 cx // return initial Trap Context of app 18 } 19}其根据传入的栈顶指针和程序入口点(提前约定为0x80400000, 用户APP的起始位置), 设置恢复后的权限为User态, 以此构造一个特殊的Trap上下文进行返回
-
当批处理操作系统初始化完成, 或者是某个应用程序运行结束或出错的时候, 我们要调用 run_next_app 函数切换到下一个应用程序. 此时 CPU 运行在 S 特权级, 而它希望能够切换到 U 特权级. 在 RISC-V 架构中, 唯一一种能够使得 CPU 特权级下降的方法就是执行 Trap 返回的特权指令, 如 sret 、mret 等. 事实上, 在从操作系统内核返回到运行应用程序之前, 要完成如下这些工作:
-
构造应用程序开始执行所需的 Trap 上下文;
-
通过 __restore 函数, 从刚构造的 Trap 上下文中, 恢复应用程序执行的部分寄存器;
-
设置 sepc CSR的内容为应用程序入口点 0x80400000;
-
切换 scratch 和 sp 寄存器, 设置 sp 指向应用程序用户栈;
-
执行 sret 从 S 特权级切换到 U 特权级.
它们可以通过复用 __restore 的代码来更容易的实现上述工作. 我们只需要在内核栈上压入一个专门为启动应用程序而特殊构造的 Trap 上下文, 再通过 __restore 函数, 就能让这些寄存器到达启动应用程序所需要的上下文状态.
批处理系统工作流程图
实践练习
代码公开存储在: rqdmap/rcore at ch2-lab
打印函数调用栈
为了打印函数调用栈, 需要禁止Rust编译器优化掉frame-pointers结构, 因而需要添加如下配置:
1// os/.cargo/config
2
3[target.riscv64gc-unknown-none-elf]
4rustflags = [
5 "-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes"
6]fp(栈底)和sp(栈顶)指针共同构成了函数调用栈帧的空间, 参考: Call stack - Wikipedia
一个问题是, Call stack内部有什么是怎么决定的? 我找了很多资料但是好像并没有说明为什么就是这样的结构(尤其是fp的位置).. 据 pdos.csail.mit.edu/6.S081/2020/lec/l-riscv.txt所说, 是这样的:
1Stack
2 .
3 .
4 +-> .
5 | +-----------------+ |
6 | | return address | |
7 | | previous fp ------+
8 | | saved registers |
9 | | local variables |
10 | | ... | <-+
11 | +-----------------+ |
12 | | return address | |
13 +------ previous fp | |
14 | saved registers | |
15 | local variables | |
16 +-> | ... | |
17 | +-----------------+ |
18 | | return address | |
19 | | previous fp ------+
20 | | saved registers |
21 | | local variables |
22 | | ... | <-+
23 | +-----------------+ |
24 | | return address | |
25 +------ previous fp | |
26 | saved registers | |
27 | local variables | |
28 $fp --> | ... | |
29 +-----------------+ |
30 | return address | |
31 | previous fp ------+
32 | saved registers |
33 $sp --> | local variables |
34 +-----------------+这也是大部分资料不加说明就给出的结论..
有关具体的结构留坑以后再考据.. 我还是不明白是什么规定/约束使得ra后就紧跟着fp..
抛去具体的原因不谈, 实现起来不算困难, 但是让我自己写还是不行, 因为要用一些core里的库..
1// os/src/backtrace.rs
2use core::arch::asm;
3use core::ptr;
4
5#[no_mangle]
6pub fn unwind() {
7 println!("[kernel] rqdmap: 123");
8 let mut fp: *const usize;
9 unsafe{
10 asm!("mv {}, fp", out(reg) fp);
11
12 println!("[Kernel] == Begin stack trace ==");
13 while fp != ptr::null() {
14 let ra = *fp.sub(1);
15 let prev_fp = *fp.sub(2) as *const usize;
16 println!("[kernel] 0x{:x}, fp = 0x{:x}", ra as usize, prev_fp as usize);
17 fp = prev_fp;
18 }
19 println!("[Kernel] == End stack trace ==");
20 }
21}实现的代码比较简单, 做一些简单的测试:
1// os/src/main.rs
2mod backtrace;
3
4fn foo1() { foo2(); }
5fn foo2() { foo3(); }
6fn foo3() { foo4(); }
7fn foo4() { foo5(); }
8fn foo5() { foo6(); }
9
10fn foo6() {
11 backtrace::unwind();
12}
13
14#[no_mangle]
15pub fn rust_main() -> ! {
16 clear_bss();
17 println!("[kernel] Hello, world!");
18 trap::init();
19 batch::init();
20
21 foo1();
22 foo2();
23 backtrace::unwind();
24 backtrace::unwind();
25
26 panic!("Stop...");
27
28 batch::run_next_app();
29}猜猜会发生什么:)
1[Kernel] == Begin stack trace ==
2[kernel] 0x80200fd2, fp = 0x80239000
3[kernel] 0x80200010, fp = 0x0
4[Kernel] == End stack trace ==
5[Kernel] == Begin stack trace ==
6[kernel] 0x80200fda, fp = 0x80239000
7[kernel] 0x80200010, fp = 0x0
8[Kernel] == End stack trace ==
9[Kernel] == Begin stack trace ==
10[kernel] 0x80200fe2, fp = 0x80239000
11[kernel] 0x80200010, fp = 0x0
12[Kernel] == End stack trace ==
13[Kernel] == Begin stack trace ==
14[kernel] 0x80200fea, fp = 0x80239000
15[kernel] 0x80200010, fp = 0x0
16[Kernel] == End stack trace ==
17[kernel] Panicked at src/main.rs:56 Stop...这真的会很让人怀疑是不是写错了.. 做了一些排查工作:
-
把std的写法cv拿过来看看, 也是一样的输出, 那么可能是其余的问题
-
能否通过gdb看一下rust源码呢? 遗憾的是我并不知道怎么弄, 目前的调试方式是使用riscv-gdb与qemu连接, 但这种gdb好像不能查看rust的源代码, 只有通过rust包提供的rust-gdb才行, 但是rust-gdb又无法与qemu的调试功能相连接(或许可以, 未仔细研究)…一筹莫展
-
编译器偷偷做了优化吗? 加一些冗余的代码:
rust1fn foo1() { println!("Start func1"); foo2(); println!("End func1"); } 2fn foo2() { println!("Start func2"); foo3(); println!("End func2"); } 3fn foo3() { println!("Start func3"); foo4(); println!("End func3"); } 4fn foo4() { println!("Start func4"); foo5(); println!("End func4"); } 5fn foo5() { println!("Start func5"); foo6(); println!("End func5"); }调用foo1(), 输出还是很不正常:
rust1Start func1 2Start func2 3Start func3 4Start func4 5Start func5 6[Kernel] == Begin stack trace == 7[kernel] 0x8020059e, fp = 0x80238fc0 8[kernel] 0x80200778, fp = 0x80239000 9[kernel] 0x80200010, fp = 0x0 10[Kernel] == End stack trace == 11End func5 12End func4 13End func3 14End func2 15End func1 16[kernel] Panicked at src/main.rs:53 Stop...查看一下foox每层的调用栈情况呢?
rust1[Kernel] == Begin stack trace == 2[kernel] 0x802007a0, fp = 0x80239000 3[kernel] 0x80200010, fp = 0x0 4[Kernel] == End stack trace == 5Start func1 6[Kernel] == Begin stack trace == 7[kernel] 0x802004a2, fp = 0x80238fc0 8[kernel] 0x802007a8, fp = 0x80239000 9[kernel] 0x80200010, fp = 0x0 10[Kernel] == End stack trace == 11Start func2 12[Kernel] == Begin stack trace == 13[kernel] 0x802004e6, fp = 0x80238fc0 14[kernel] 0x802007a8, fp = 0x80239000 15[kernel] 0x80200010, fp = 0x0 16[Kernel] == End stack trace == 17Start func3 18[Kernel] == Begin stack trace == 19[kernel] 0x80200530, fp = 0x80238fc0 20[kernel] 0x802007a8, fp = 0x80239000 21[kernel] 0x80200010, fp = 0x0 22[Kernel] == End stack trace == 23Start func4 24[Kernel] == Begin stack trace == 25[kernel] 0x80200574, fp = 0x80238fc0 26[kernel] 0x802007a8, fp = 0x80239000 27[kernel] 0x80200010, fp = 0x0 28[Kernel] == End stack trace == 29Start func5 30[Kernel] == Begin stack trace == 31[kernel] 0x802005be, fp = 0x80238fc0 32[kernel] 0x802007a8, fp = 0x80239000 33[kernel] 0x80200010, fp = 0x0 34[Kernel] == End stack trace == 35[Kernel] == Begin stack trace == 36[kernel] 0x802005c6, fp = 0x80238fc0 37[kernel] 0x802007a8, fp = 0x80239000 38[kernel] 0x80200010, fp = 0x0 39[Kernel] == End stack trace == 40End func5 41End func4 42End func3 43End func2 44End func1 45[kernel] Panicked at src/main.rs:54 Stop...所有的都是三层! 这太奇怪了, 就像rustc自动将我好几个foo函数全部展开后放在rust_main下了一样! ast语法树分析确实可能做到这样的事情, 以求减少递归而变成顺序的结构; 用一个自递归考验一下他:
rust1fn foo(left: usize){ 2 if left > 0 { 3 backtrace::unwind(); 4 foo(left - 1); 5 } 6 backtrace::unwind(); 7} 8 9pub fn rust_main() -> ! { 10 backtrace::unwind(); 11 foo(4); 12}编译器优化总算无能为力了! 成功看到了对应的多层递归层数:
rust1[Kernel] == Begin stack trace == 2[kernel] 0x80200fee, fp = 0x80239000 3[kernel] 0x80200010, fp = 0x0 4[Kernel] == End stack trace == 5[Kernel] == Begin stack trace == 6[kernel] 0x80200f60, fp = 0x80238fc0 7[kernel] 0x80200ff8, fp = 0x80239000 8[kernel] 0x80200010, fp = 0x0 9[Kernel] == End stack trace == 10[Kernel] == Begin stack trace == 11[kernel] 0x80200f60, fp = 0x80238fa0 12[kernel] 0x80200f6c, fp = 0x80238fc0 13[kernel] 0x80200ff8, fp = 0x80239000 14[kernel] 0x80200010, fp = 0x0 15[Kernel] == End stack trace == 16[Kernel] == Begin stack trace == 17[kernel] 0x80200f60, fp = 0x80238f80 18[kernel] 0x80200f6c, fp = 0x80238fa0 19[kernel] 0x80200f6c, fp = 0x80238fc0 20[kernel] 0x80200ff8, fp = 0x80239000 21[kernel] 0x80200010, fp = 0x0 22[Kernel] == End stack trace == 23[Kernel] == Begin stack trace == 24[kernel] 0x80200f60, fp = 0x80238f60 25[kernel] 0x80200f6c, fp = 0x80238f80 26[kernel] 0x80200f6c, fp = 0x80238fa0 27[kernel] 0x80200f6c, fp = 0x80238fc0 28[kernel] 0x80200ff8, fp = 0x80239000 29[kernel] 0x80200010, fp = 0x0 30[Kernel] == End stack trace == 31[Kernel] == Begin stack trace == 32[kernel] 0x80200f6c, fp = 0x80238f60 33[kernel] 0x80200f6c, fp = 0x80238f80 34[kernel] 0x80200f6c, fp = 0x80238fa0 35[kernel] 0x80200f6c, fp = 0x80238fc0 36[kernel] 0x80200ff8, fp = 0x80239000 37[kernel] 0x80200010, fp = 0x0 38[Kernel] == End stack trace == 39[Kernel] == Begin stack trace == 40[kernel] 0x80200f6c, fp = 0x80238f80 41[kernel] 0x80200f6c, fp = 0x80238fa0 42[kernel] 0x80200f6c, fp = 0x80238fc0 43[kernel] 0x80200ff8, fp = 0x80239000 44[kernel] 0x80200010, fp = 0x0 45[Kernel] == End stack trace == 46[Kernel] == Begin stack trace == 47[kernel] 0x80200f6c, fp = 0x80238fa0 48[kernel] 0x80200f6c, fp = 0x80238fc0 49[kernel] 0x80200ff8, fp = 0x80239000 50[kernel] 0x80200010, fp = 0x0 51[Kernel] == End stack trace == 52[Kernel] == Begin stack trace == 53[kernel] 0x80200f6c, fp = 0x80238fc0 54[kernel] 0x80200ff8, fp = 0x80239000 55[kernel] 0x80200010, fp = 0x0 56[Kernel] == End stack trace == 57[Kernel] == Begin stack trace == 58[kernel] 0x80200ff8, fp = 0x80239000 59[kernel] 0x80200010, fp = 0x0 60[Kernel] == End stack trace == 61[kernel] Panicked at src/main.rs:52 Stop...
那么可以认为实现成功!
至于未经好好调教的rustc编译器, 则暂时放过他一马(实际是放过我自己一马)
内核功能拓展
To Be Done.
sys_write安全检查
To Be Done.
后记
虽然不是很愿意承认.. 但是这类博客感觉又要变成依托答辩了.. 非常的不可阅读, 而且充斥着不少到处抄来的东西, 有一些未经验证与不成体系的技术内容.. 痛苦
