本章主要是讲解如何设计和实现建立在裸机上的执行环境, 并让应用程序能够在这样的执行环境中运行.
导言中说:
大多数程序员的第一行代码都从 Hello, world! 开始,当我们满怀着好奇心在编辑器内键入仅仅数个字节,再经过几行命令编译(靠的是编译器)、运行(靠的是操作系统),终于在黑洞洞的终端窗口中看到期望中的结果的时候,一扇通往编程世界的大门已经打开。
回头看过去, 写一个C代码并简简单单的成功运行起来确实是依靠了太多的东西了!
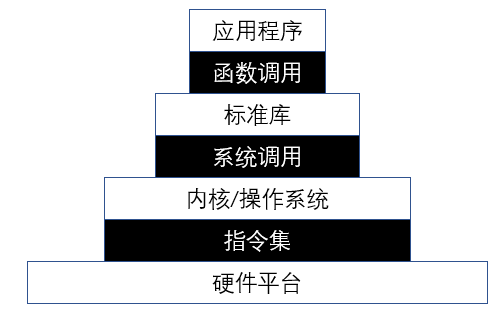
本章实际上做的工作是搞一个运行在裸机执行环境上的系统软件(LibOS); 这与一般的软件编写不同, 因为一般的软件用到的编译器需要链接到标准库, 而标准库又依赖于OS, 这里则要求不依赖任何的OS功能. 为了做到这一点, 做法是:
-
首先写一个不需要任何标准库的软件并通过编译. 先移除一般应用使用的标准库组件, 此时会导致编译失败; 再逐步添加尽可能少的不依赖于OS的运行时代码, 使得编译器能够正常编译.
-
正确对接LibOS与QEMU模拟器. 了解QEMU的启动流程与程序的内存布局等内容
-
为了使用Rust语言实现内核功能, 需要将控制权交给Rust入口函数; 其中又涉及到函数调用和栈的若干内容.
-
基于SBI服务完成一些更加低层次的功能(如Panic, 关机, 格式化输出等)
有关平台与架构
再说明一些rust编译器有关目标平台与目标三元组的内容, 可以打印rustc默认配置信息, 其中host一栏就说明了当前的目标平台(架构-CPU厂商-操作系统-运行时库).
1$ rustc --version --verbose
2rustc 1.72.0-nightly (f20afcc45 2023-07-04)
3binary: rustc
4commit-hash: f20afcc455bbcc5c0f7679450fb35fd0c9668880
5commit-date: 2023-07-04
6host: x86_64-unknown-linux-gnu
7release: 1.72.0-nightly
8LLVM version: 16.0.5下面我们需要将其换为riscv相关的架构, 首先查询一下rustc目前支持哪些:
1$ rustc --print target-list | grep riscv
2riscv32gc-unknown-linux-gnu
3riscv32gc-unknown-linux-musl
4riscv32i-unknown-none-elf
5riscv32im-unknown-none-elf
6riscv32imac-esp-espidf
7riscv32imac-unknown-none-elf
8riscv32imac-unknown-xous-elf
9riscv32imc-esp-espidf
10riscv32imc-unknown-none-elf
11riscv64gc-unknown-freebsd
12riscv64gc-unknown-fuchsia
13riscv64gc-unknown-linux-gnu
14riscv64gc-unknown-linux-musl
15riscv64gc-unknown-none-elf
16riscv64gc-unknown-openbsd
17riscv64imac-unknown-none-elf选择riscv64gc-unknown-none-elf目标平台:
-
第一栏表明CPU架构, 其中的
gc进一步说明了riscv更加详细的拓展指令集相关:- I:每款处理器都必须实现的基本整数指令集。在 RV32I 中,每个通用寄存器的位宽为 32 位;在 RV64I 中则为 64 位。它可以用来模拟绝大多数标准指令集拓展中的指令,除了比较特殊的 A 拓展,因为它需要特别的硬件支持。
- M 拓展:提供整数乘除法相关指令。
- A 拓展:提供原子指令和一些相关的内存同步机制,这个后面会展开。
- F/D 拓展:提供单/双精度浮点数运算支持。
- C 拓展:提供压缩指令拓展。
- G拓展: 基本指令集I加上拓展MAFD的总称
-
操作系统为None, 这是由于我们将在裸机上实现, 不需要使用Linux这么高级的系统
-
运行时库为elf代表没有任何系统调用的封装支持, 但可以生成ELF格式的执行程序
此时, 如果尝试对hello world程序执行cargo run --target riscv64gc-unknown-none-elf并不能成功:
1$ cargo build
2 Compiling os v0.1.0 (/home/rqdmap/tmp/os)
3error[E0463]: can't find crate for `std`
4 |
5 = note: the `riscv64gc-unknown-none-elf` target may not support the standard library
6 = note: `std` is required by `os` because it does not declare `#![no_std]`
7 = help: consider building the standard library from source with `cargo build -Zbuild-std`
8
9error: cannot find macro `println` in this scope
10 --> src/main.rs:2:5
11 |
122 | println!("Hello, world!");
13 | ^^^^^^^
14
15error: `#[panic_handler]` function required, but not found
16
17For more information about this error, try `rustc --explain E0463`.
18error: could not compile `os` (bin "os") due to 3 previous errors这是因为裸机平台上没有标准库std, 不过好在有经过裁剪的std库: core
core不需要任何OS支持, 不过其功能也比较受限. 由于Rust是一种面向系统(包括开发OS)的开发语言, 所以不少三方库仅仅依赖core包, 这很大程度上可以减轻我们的编程负担, 满足大部分的功能需求!
移除标准库依赖
为了方便交叉编译, 可以新建一个.cargo/config的文件, 其中放入:
1[build]
2target = "riscv64gc-unknown-none-elf"这会使得编译器默认使用该目标平台进行交叉编译, 而不需要再在cargo编译指令中指定目标架构了, 方便后续编译.
下面我们开始移除对std包的依赖. 首先使用#![no_std]放在源码开头, 防止rust使用标准库.
#![no_std]是一个声明这个crate不会连接到std-crate二十core-crate的crate级别的属性. libcore是std-crate的一个与平台无关的子集, 对程序将要运行在的系统上没有任何假设(需求). 因此, 它为语言原语,像是float, string和slices等提供api, 和开放的处理器特性, 像是原子操作与SIMD指令. 然而他缺少任何设计平台集成的API. 由于这些属性, no_std与libcore写成的代码能不能够用于任何类型的引导(stage 0)像是加载程序, 固件还有内核.
From: no_std - 嵌入式Rust之书
在 Rust 代码中,#[xxx] 和 #![xxx] 是两种不同的属性注解语法。
#[xxx] 用于为特定项(如函数、结构体、枚举等)添加属性。这些属性可以是编译器内置的属性,也可以是用户自定义的属性。例如,#[derive(Debug)] 用于为结构体或枚举自动生成 Debug trait 的实现。
#![xxx] 则是用于设置整个模块或 crate 的全局属性。它通常被放置在源文件的顶部,并影响整个模块或 crate 中的所有项。一些常见的全局属性包括 #![crate_name] 用于指定 crate 的名称,#![deny(warnings)] 用于禁止警告信息等。
总结起来,#[xxx] 是用于修饰单个项的属性注解,而 #![xxx] 是用于设置全局属性的注解。
由于此时没有std的支持了, 而rust的println事实上用到了write系统调用, 因而此时我们已经不能使用println!宏了; 暂时先将这一行注释掉吧!
1fn main() {
2 // println!("Hello, world!");
3}再次编译出现新的错误:
1$ cargo build
2 Compiling os v0.1.0 (/home/rqdmap/tmp/os)
3error: `#[panic_handler]` function required, but not found
4
5error: could not compile `os` (bin "os") due to previous errorRust程序在panic时会手动/自动调用panic!宏, 出于安全性的考虑, rust编译器在编译时要求提供panic!宏的具体实现. 不过由于已经没有std包了, 所以我们需要自己实现一下.
新建文件src/lang_items.rs, 写入
1use core::panic::PanicInfo;
2
3#[panic_handler]
4fn panic(_info: &PanicInfo) -> ! {
5 loop {}
6}这里的#[panic_handler]指导编译, 用于说明core包中panic!对接的函数实现; 同时在main函数前写上mod lang_items;即可以模块的方式引入上述文件中的函数.
一波未平一波又起, 新的代码还是会报错!
1$ cargo build
2 Compiling os v0.1.0 (/home/rqdmap/tmp/os)
3error: requires `start` lang_item
4
5error: could not compile `os` (bin "os") due to previous errorstart语义项代表了std执行程序前要进行的一些初始化工作, 由于禁用了std标准库, 那么编译器也就找不到这项功能的实现了.
添加#![no_main]告知编译器禁用该功能即可, 此时, cargo即可成功地编译一个看似可执行的程序.
对接QEMU
以make run中的QEMU指令为例:
1qemu-system-riscv64 \
2 -machine virt \
3 -nographic \
4 -bios ../bootloader/rustsbi-qemu.bin \
5 -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000其中比较关键的是-device后的参数, loader 表示在 Qemu 开机前将一个宿主机上的文件载入到 Qemu 的物理内存的指定位置中, file 和 addr 属性分别指定待载入文件的路径以及将文件载入到的 Qemu 物理内存上的物理地址.
QEMU在启动模拟时, 将必要的文件载入物理内存后:
-
设置PC计数器为
0x1000, 执行几条指令后跳转到0x80000000; 跳转的目的地是硬编码进入QEMU的, 作为使用者来说无法修改. -
将bootlader放在
0x80000000上, 其做一些初始化后再将控制权交给rust内核. rscore默认提供的bios会跳转到预先约定的0x80200000, 这也解释了为什么要将内核装载进入0x80200000上. -
为了正确与rustsbi对接, 内核应该确保从约定好的位置开始执行第一条指令.
编写第一条内核指令
编写一段asm代码, 使用rust的global_asm宏装载.
1# entry.asm
2 .section .text.entry
3 .globl _start
4_start:
5 li x1, 100这其中:
-
.section告知这之后的内容全部放在.text.entry段中 -
.globl告知编译器_start是一个全局符号 -
_start:声明了一个符号, 该符号指向为紧跟其后的内容, 即第五行的指令 -
li为load immediate, 将100加载到寄存器x1中
随后在rust代码中加入它即可.
1// main.rs
2#![no_std]
3#![no_main]
4
5mod lang_items;
6
7use core::arch::global_asm;
8global_asm!(include_str!("entry.asm"));
9
10fn main() {
11 // println!("Hello, world!");
12}内核内存布局的调整
如前所述, 我们需要保证内核的第一条代码从0x80200000开始, 默认的内存布局不满足该要求; 因而可以使用链接脚本调整编译器的行为:
如果一个程序全部使用相对地址(如相对某个寄存器(PC等))来访问变量与函数, 那么程序只需要整体保持相对位置地被装载进入内存的任何位置均可以正常执行. 这种程序就是位置无关程序, PIE.
但是如果程序依赖绝对地址, 那么其就一定有一个确定的内存布局, 而且程序必须被装载到对应的位置才能正常运行. 由于当前的内核不是pie的, 所以我们必须强制设置内存布局的结构, 并将内存相应地加载到0x80200000上.
链接脚本os/src/linker.ld:
1OUTPUT_ARCH(riscv)
2ENTRY(_start)
3BASE_ADDRESS = 0x80200000;
4
5SECTIONS
6{
7 . = BASE_ADDRESS;
8 skernel = .;
9
10 stext = .;
11 .text : {
12 *(.text.entry)
13 *(.text .text.*)
14 }
15
16 . = ALIGN(4K);
17 etext = .;
18 srodata = .;
19 .rodata : {
20 *(.rodata .rodata.*)
21 *(.srodata .srodata.*)
22 }
23
24 . = ALIGN(4K);
25 erodata = .;
26 sdata = .;
27 .data : {
28 *(.data .data.*)
29 *(.sdata .sdata.*)
30 }
31
32 . = ALIGN(4K);
33 edata = .;
34 .bss : {
35 *(.bss.stack)
36 sbss = .;
37 *(.bss .bss.*)
38 *(.sbss .sbss.*)
39 }
40
41 . = ALIGN(4K);
42 ebss = .;
43 ekernel = .;
44
45 /DISCARD/ : {
46 *(.eh_frame)
47 }
48}第一次接触链接脚本, 稍微详细地看一下:
-
L1,2,3 设置目标平台, 程序的入口点为之前设置的全局符号
_start, 设置了一个常量BASE_ADDRESS -
L5开始体现了链接过程收集过来的段的排布与合并方式, 其中
.表示目前的地址, 用来指示链接器将下一个收集来的段放在什么地址的下面;:前为最终生成的可执行文件的段的名字, 后面的花括号内则按照顺序收集输入文件的指定段, 表示哪些文件的哪些段需要放到这里. -
最终,
.text, .rodata, .data, .bss都收集了各个输入文件的同名段, 并且有两个全局符号(sxxx, exxx)记录这些段的起始位置 -
可以看到,
.text.entry是放在最开始的, 因而其位置也就等于BASE_ADDRESS, 符合要求
为了实际用户链接脚本, 还需要在.cargo/config加入:
1[target.riscv64gc-unknown-none-elf]
2rustflags = [
3 "-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes"
4]编译完成后, 可以使用readelf检查一下符号表以及段信息, 可以看到.text确实从我们想要的位置开始, 占据4个字节.
1$ readelf -a target/riscv64gc-unknown-none-elf/debug/os
2...
3Section Headers:
4 [Nr] Name Type Address Offset
5 Size EntSize Flags Link Info Align
6 [ 0] NULL 0000000000000000 00000000
7 0000000000000000 0000000000000000 0 0 0
8 [ 1] .text PROGBITS 0000000080200000 00001000
9 0000000000000004 0000000000000000 AX 0 0 1
10 [ 2] .bss NOBITS 0000000080201000 00001004
11 0000000000000000 0000000000000000 WA 0 0 1
12...
13Symbol table '.symtab' contains 106 entries:
14 Num: Value Size Type Bind Vis Ndx Name
15 ...
16 92: 0000000000000000 0 NOTYPE LOCAL DEFAULT 10
17 93: 0000000000000000 0 FILE LOCAL DEFAULT ABS yqvkc8kq9bldvip
18 94: 0000000080200000 0 NOTYPE GLOBAL DEFAULT 1 _start
19 95: 0000000080200000 0 NOTYPE GLOBAL DEFAULT ABS BASE_ADDRESS
20 96: 0000000080200000 0 NOTYPE GLOBAL DEFAULT 1 skernel
21 97: 0000000080200000 0 NOTYPE GLOBAL DEFAULT 1 stext
22 98: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 1 etext
23 99: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 1 srodata
24 100: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 1 erodata
25 101: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 1 sdata
26 102: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 1 edata
27 103: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 2 sbss
28 104: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 2 ebss
29 105: 0000000080201000 0 NOTYPE GLOBAL DEFAULT 2 ekernel元数据清理
在可执行文件的结构中, 开头和结尾部分存在一些元数据, 后面才会跟着代码段等各个段的信息, 当带有元数据的可执行文件被装载进qemu后, 第一行代码内核代码的位置便不在BASE_ADDRESS了, Qemu因此无法执行这样的内核代码, 为此需要strip掉这些elf的元数据:
1$ rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/release/os -O binary target/riscv64gc-unknown-none-elf/release/os.bin
2
3$ stat os
4 File: os
5 Size: 5208 Blocks: 16 IO Block: 4096 regular file
6Device: 0,42 Inode: 17893504 Links: 2
7Access: (0755/-rwxr-xr-x) Uid: ( 1000/ rqdmap) Gid: ( 1000/ rqdmap)
8Access: 2023-07-23 21:50:09.194861817 +0800
9Modify: 2023-07-23 21:50:08.071531321 +0800
10Change: 2023-07-23 21:50:08.078197971 +0800
11 Birth: 2023-07-23 21:50:08.071531321 +0800
12
13$ stat os.bin
14 File: os.bin
15 Size: 4 Blocks: 8 IO Block: 4096 regular file
16Device: 0,42 Inode: 17893509 Links: 1
17Access: (0755/-rwxr-xr-x) Uid: ( 1000/ rqdmap) Gid: ( 1000/ rqdmap)
18Access: 2023-07-23 21:50:09.194861817 +0800
19Modify: 2023-07-23 21:50:09.198195141 +0800
20Change: 2023-07-23 21:50:09.198195141 +0800
21 Birth: 2023-07-23 21:50:09.194861817 +0800清理过后的镜像文件只有4B, 这是由于其中确实仅包含了我们写的一条asm语句!
GDB验证
用两个shell脚本执行qemu+gdb的调试:
1#!/bin/zsh
2qemu-system-riscv64 \
3 -machine virt \
4 -nographic \
5 -bios ../bootloader/rustsbi-qemu.bin \
6 -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 \
7 -s -S
8
9#!/bin/zsh
10riscv64-linux-gnu-gdb \
11 -ex 'file target/riscv64gc-unknown-none-elf/release/os' \
12 -ex 'set arch riscv:rv64' \
13 -ex 'target remote localhost:1234'当qemu刚刚启动时, 使用x/10i $pc, 从pc的位置开始查看10条指令:
1x/10i $pc
2=> 0x1000: auipc t0,0x0
3 0x1004: add a2,t0,40
4 0x1008: csrr a0,mhartid
5 0x100c: ld a1,32(t0)
6 0x1010: ld t0,24(t0)
7 0x1014: jr t0
8 0x1018: unimp
9 0x101a: .2byte 0x8000
10 0x101c: unimp
11 0x101e: unimp可以验证到qemu确实是从0x1000开始执行, 不过固件仅包含6条指令以及一个数据段上的0x8000; 具体可以看到指令:
-
auipc t0,0x0: 将当前PC寄存器的值加上一个立即数(在这里是0x0), 并将结果存储在寄存器t0中. 这里需要注意, 当执行到0x1000的指令时, PC已经默认+4成为0x1004了 -
将寄存器t0的值加上立即数40, 并将结果存储在寄存器a2中, 将mhartid寄存器的值存储在寄存器a0中. mhartid寄存器用于标识硬件线程ID, 将寄存器t0的值加上立即数32, 然后将从该地址处读取的数据存储在寄存器a1中.
- a0-a2到底干啥的不知道..
-
ld t0,24(t0): 将0x101a对应的数据装载进入t0, 后续将进行跳转. -
jr t0: 跳转到t0中存储的内容. -
unimp: 该指令未实现, 如果执行到了该指令将导致异常 -
.2byte 0x8000: 数据段, 目标跳转地址
当跳转到0x80000000后将由rustsbi接管, 最终将进入到0x80200000, 可以通过b和c打断点来验证.
函数调用的支持
为了支持函数调用, 本质上是需要分配一块栈空间. 幸运的是编译器会帮我们完成有关函数调用开场白, 闭场白的工作, 因而我们只需要合理的初始化栈空间以及sp等寄存器即可.
修改entry.asm, 添加一段栈空间:
1# os/src/entry.asm
2 .section .text.entry
3 .globl _start
4_start:
5 la sp, boot_stack_top
6 call rust_main
7
8 .section .bss.stack
9 .globl boot_stack_lower_bound
10boot_stack_lower_bound:
11 .space 4096 * 16
12 .globl boot_stack_top
13boot_stack_top:lw t0, SYMBOL is an assembler pseudo instruction that puts the value of memory at the address SYMBOL into t0. (Load Word)
在所构想的内存布局中这块空间应该与其他的代码/数据物理隔离, 不过如果发生了栈溢出可能就会覆盖掉其余的段空间, 目前还没有太好的办法解决, 不过等后续引入了地址空间抽象和MMU硬件的帮助一切都会好起来
起初的错误言论: rust的入口点也可以做一些修改了, 不用再显示地引入entry.asm中的汇编代码了, 而是直接被entry.asm所调用:
事实上是, 如果这样做那么os.bin会变成0B, 这是显然的! 因为cargo编译的对象自始至终应该都是main.rs这个文件, 如果其中不主动引入asm代码那么该文件的代码也不会参与进来! 当引入了该asm代码后, 那么最开始才会在asm做一些初始化(这是由于入口点的符号所决定的), 随后再跳转到rust_main符号交由rust接手.
1#![no_std]
2#![no_main]
3mod lang_items;
4use core::arch::global_asm;
5global_asm!(include_str!("entry.asm"));
6#[no_mangle]
7pub fn rust_main() {
8 loop {}
9}如果不加入#[no_mangle]那么入口点的名称可能会发生变化, 导致链接器无法找到该符号进而链接失败.
这里还有一个比较奇怪的注解 #[no_mangle],它用于告诉 Rust 编译器:不要乱改函数的名称。 Mangling 的定义是:当 Rust 因为编译需要去修改函数的名称,例如为了让名称包含更多的信息,这样其它的编译部分就能从该名称获取相应的信息,这种修改会导致函数名变得相当不可读。 因此,为了让 Rust 函数能顺利被其它语言调用,我们必须要禁止掉该功能。
bss段清零
在内核初始化必须完成对bss段的清零, 由于目前已经将控制权转给rust了, 因而可以不再手写汇编而是在rust中完成该工作:
1fn clear_bss() {
2 extern "C" {
3 fn sbss();
4 fn ebss();
5 }
6 (sbss as usize..ebss as usize).for_each(|a| {
7 unsafe { (a as *mut u8).write_volatile(0) }
8 });
9}sbss和ebss是在链接脚本中定义的全局符号, 标记了bss段的开头和结尾, 使用rust代码对这段区域清零即可.
对裸指针的解引用是unsafe行为, 在rust中必须要被包裹在unsafe块中才行.
C 语言的代码定义在了 extern 代码块中, 而 extern 必须使用 unsafe 才能进行进行调用,原因在于其它语言的代码并不会强制执行 Rust 的规则,因此 Rust 无法对这些代码进行检查,最终还是要靠开发者自己来保证代码的正确性和程序的安全性。
在 extern “C” 代码块中,我们列出了想要调用的外部函数的签名。其中 “C” 定义了外部函数所使用的应用二进制接口ABI (Application Binary Interface):ABI 定义了如何在汇编层面来调用该函数。在所有 ABI 中,C 语言的是最常见的。
基于SBI实现一些基本功能
RISC-V指令集的SBI标准规定了类Unix操作系统之下的运行环境规范。这个规范拥有多种实现,RustSBI是它的一种实现。
RISC-V架构中,存在着定义于操作系统之下的运行环境。这个运行环境不仅将引导启动RISC-V下的操作系统, 还将常驻后台,为操作系统提供一系列二进制接口,以便其获取和操作硬件信息。 RISC-V给出了此类环境和二进制接口的规范,称为“操作系统二进制接口”,即“SBI”。
SBI的实现是在M模式下运行的特定于平台的固件,它将管理S、U等特权上的程序或通用的操作系统。
来源: 基于 SBI 服务完成输出和关机 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
SBI 是 RISC-V Supervisor Binary Interface 规范的缩写,OpenSBI 是RISC-V官方用C语言开发的SBI参考实现;RustSBI 是用Rust语言实现的SBI。
BIOS 是 Basic Input/Output System,作用是引导计算机系统的启动以及硬件测试,并向OS提供硬件抽象层。
机器上电之后,会从ROM中读取引导代码,引导整个计算机软硬件系统的启动。而整个启动过程是分为多个阶段的,现行通用的多阶段引导模型为:
ROM -> LOADER -> RUNTIME -> BOOTLOADER -> OS
Loader 要干的事情,就是内存初始化,以及加载 Runtime 和 BootLoader 程序。而Loader自己也是一段程序,常见的Loader就包括 BIOS 和 UEFI,后者是前者的继任者。
Runtime 固件程序是为了提供运行时服务(runtime services),它是对硬件最基础的抽象,对OS提供服务,当我们要在同一套硬件系统中运行不同的操作系统,或者做硬件级别的虚拟化时,就离不开Runtime服务的支持。SBI就是RISC-V架构的Runtime规范。
BootLoader 要干的事情包括文件系统引导、网卡引导、操作系统启动配置项设置、操作系统加载等等。常见的 BootLoader 包括GRUB,U-Boot,LinuxBoot等。
而 BIOS/UEFI 的大多数实现,都是 Loader、Runtime、BootLoader 三合一的,所以不能粗暴的认为 SBI 跟 BIOS/UEFI 有直接的可比性。
如果把BIOS当做一个泛化的术语使用,而不是指某个具体实现的话,那么可以认为 SBI 是 BIOS 的组成部分之一。
也可参考这份文稿《An Introduction to RISC-V Boot Flow》的P5, P7, P9-11。
题外话: 计算机最重要的思想之一就是分层抽象,在任意两层之间,还可以按照设计者的意愿再次添加抽象层。而软件架构的设计和实现,是为了解决现实世界的具体问题,会面临资源、财力、物力、人力、时间等多种因素的掣肘,就会诞生一些“不那么规矩”、“不那么单纯”的架构或组件/软件,它们往往会跨层次,跨模块,大模块拆小,小模块合并,甚至打破一些“金科玉律”等等。
所以,相比于弄懂一个名词,更多的精力应该放在理解事物的本质上,只要把解决问题的流程和方法弄明白了,解决问题的过程中所用到的子流程、工具、方法,你爱怎么叫怎么叫,甚至自己发明名词也可以(只是与外人沟通可能会不太顺畅)。
SBI居然是一个OS与硬件之间的抽象层, 难怪之前看到什么supervisor的文章一直在想他的运行位置是在os上还是怎么样才能获得那么大的能力..
添加RustSBI对应的代码, 在main中使用模块的方式引用使用:
1// sbi.rs
2#![allow(unused)] // 此行请放在该文件最开头
3const SBI_SET_TIMER: usize = 0;
4const SBI_CONSOLE_PUTCHAR: usize = 1;
5const SBI_CONSOLE_GETCHAR: usize = 2;
6const SBI_CLEAR_IPI: usize = 3;
7const SBI_SEND_IPI: usize = 4;
8const SBI_REMOTE_FENCE_I: usize = 5;
9const SBI_REMOTE_SFENCE_VMA: usize = 6;
10const SBI_REMOTE_SFENCE_VMA_ASID: usize = 7;
11const SBI_SHUTDOWN: usize = 8;
12
13use core::arch::asm;
14#[inline(always)]
15fn sbi_call(which: usize, arg0: usize, arg1: usize, arg2: usize) -> usize {
16 let mut ret;
17 unsafe {
18 asm!(
19 "ecall",
20 inlateout("x10") arg0 => ret,
21 in("x11") arg1,
22 in("x12") arg2,
23 in("x17") which,
24 );
25 }
26 ret
27}
28
29pub fn console_putchar(c: usize) {
30 sbi_call(SBI_CONSOLE_PUTCHAR, c, 0, 0);
31}
32
33pub fn shutdown() -> ! {
34 sbi_call(SBI_SHUTDOWN, 0, 0, 0);
35 panic!("It should shutdown!");
36}可以看到, rustabi的使用方式非常像传统内核的系统调用, 具体内部如何实现的暂时不管, 只需要知道接口如此可以使用即可.
利用该sbi调用实现putchar和shutdown的功能, main函数即可调用这两个函数了!
基于putchar以及macro_rules过程宏, 可以实现print!和println!宏:
1use crate::sbi::console_putchar;
2use core::fmt::{self, Write};
3
4struct Stdout;
5
6impl Write for Stdout {
7 fn write_str(&mut self, s: &str) -> fmt::Result {
8 for c in s.chars() {
9 console_putchar(c as usize);
10 }
11 Ok(())
12 }
13}
14
15pub fn print(args: fmt::Arguments) {
16 Stdout.write_fmt(args).unwrap();
17}
18
19#[macro_export]
20macro_rules! print {
21 ($fmt: literal $(, $($arg: tt)+)?) => {
22 $crate::console::print(format_args!($fmt $(, $($arg)+)?));
23 }
24}
25
26#[macro_export]
27macro_rules! println {
28 ($fmt: literal $(, $($arg: tt)+)?) => {
29 $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?));
30 }
31}由于这段rust代码中的过程宏的定义貌似比较复杂, 因而暂时折叠, 等待后续进一步看一些有关宏的内容后可能会对其有更容易的理解.
有了println!后即可将原本简陋的panic换成一个带有print输出功能的panic:
1// os/src/lang_item.rs
2use crate::sbi::shutdown;
3use core::panic::PanicInfo;
4
5#[panic_handler]
6fn panic(info: &PanicInfo) -> ! {
7 if let Some(location) = info.location() {
8 println!(
9 "Panicked at {}:{} {}",
10 location.file(),
11 location.line(),
12 info.message().unwrap()
13 );
14 } else {
15 println!("Panicked: {}", info.message().unwrap());
16 }
17 shutdown()
18}需要注意, 这里的panic相比于之前的多出了很多的信息, 特别是info.message, 添加上述代码后rust-analyze会告诉我们:
1info.message().unwrap() ■ use of unstable library feature 'panic_info_message'
这意味着我们需要在main.rs中添加: #![feature(panic_info_message)] 才能通过message获取报错信息; 至此main中就可以使用带有一些额外信息输出的panic功能了.
SBI关机失败问题
基于SBI的putchar之前测试过确实可以, 导致一直没有测试过shutdown是否可行, 结果刚刚尝试关机时出现了问题, rustsbi无法成功关机!
而且由于在main中调用panic, panic宏展开最终调用shutdown, shutdown如果失败, 则又会调用panic… 导致qemu模拟器上会出现非常多的报错信息..
我无法确定问题的原因是什么, 目前还是修改shutdown的方式为无限loop..
1pub fn shutdown(){
2 sbi_call(SBI_SHUTDOWN, 0, 0, 0);
3 println!("It should shutdown! Now loop..");
4 loop{}
5}彩色化Log日志
按照要求, 需要通过make run LOG=INFO等方式来实现对日志追踪的控制的.. 不过仔细想来, 我的rust程序如何接受命令行参数我都不知道.. 而且通常一个ELF可执行程序接受参数, 其参数应该都是shell/OS通过一些方式传递给他的, 其本身不具备什么功能可以访问到和他"同级"的参数列表.. 而我们在这里又实现的是一个OS, 那么OS作为一个应用程序而言又怎么能够获得命令行参数?…
官方给的这条基于makefile的指令为啥就能实现??.. 看了一下官方的源码:
1// src/logging.rs
2pub fn init() {
3 static LOGGER: SimpleLogger = SimpleLogger;
4 log::set_logger(&LOGGER).unwrap();
5 log::set_max_level(match option_env!("LOG") {
6 Some("ERROR") => LevelFilter::Error,
7 Some("WARN") => LevelFilter::Warn,
8 Some("INFO") => LevelFilter::Info,
9 Some("DEBUG") => LevelFilter::Debug,
10 Some("TRACE") => LevelFilter::Trace,
11 _ => LevelFilter::Off,
12 });
13}
14
15// **/core/src/macros/mod.rs
16#[stable(feature = "rust1", since = "1.0.0")]
17#[rustc_builtin_macro]
18#[macro_export]
19#[cfg_attr(not(test), rustc_diagnostic_item = "option_env_macro")]
20macro_rules! option_env {
21($name:expr $(,)?) => {{ /* compiler built-in */ }};
22}这是Rust语言中的一个宏定义,名为option_env。让我们逐行解释它的含义:
-
#[stable(feature = "rust1", since = "1.0.0")]: 这是一个属性(attribute),用于标记该宏的稳定性和引入版本。#[stable]属性表示该宏自 Rust 1.0.0 版本起就可用,并且不会随后的版本发生不兼容的更改。“rust1"表示该宏是在Rust 1.0.0版本中引入的。 -
#[rustc_builtin_macro]: 这个属性表明该宏是Rust编译器内置的宏。Rust编译器在处理这个宏时,会使用特殊的内部逻辑。 -
#[macro_export]: 这个属性允许该宏在 crate 的外部被其他 crate 使用。如果不加这个属性,该宏就只能在当前 crate 中使用。 -
#[cfg_attr(not(test), rustc_diagnostic_item = "option_env_macro")]: 这也是一个属性,用于控制编译器的行为。#[cfg_attr]允许根据条件来设置属性。在这里,它告诉编译器如果条件not(test)成立,则将该宏标记为rustc_diagnostic_item = "option_env_macro"。这个属性用于编译器诊断,通常你不需要直接使用它。 -
macro_rules! option_env { ... }: 这是宏的定义部分。这里使用macro_rules!宏来创建一个自定义的宏。在该宏的定义中,macro_rules!宏允许你使用模式匹配来捕获宏的参数,并根据模式生成相应的代码。
该 option_env 宏接受一个 name 参数,它是一个表示环境变量名的表达式。宏定义的实现部分由注释表示为“compiler built-in”,这意味着这个宏在编译器内部处理,不会产生具体的代码。这个宏的目的是检查是否定义了名为name的环境变量,并返回相应的值。如果环境变量未定义,则返回None(或可能是 null 或其他表示未定义的值)。由于这是一个编译器内置的宏,实际代码并未出现在你的代码中,而是在编译过程中由编译器处理。
对哦.. 这根本不是一个命令行参数, 而是一个环境变量.. 环境变量确实看上去是可以捕获的, 不过具体的原理也不细究了!
另外有关彩色Log的需求, rCore提示可以使用crate::log库.. 不过这里懒得去学习一些新的标准库的使用了, 因为这个库貌似还蛮重要的, 等之后再学的机会也不少, 由于其超出了OS和Rust的基本使用, 这里就先skip过去了.
